
La taille optimale d'un échantillon représentatif. Comment déterminer la taille d'échantillon optimale pour une enquête de masse
Lors de la conception d'un échantillon d'observation, la question se pose de la taille d'échantillon requise. Ce nombre peut être déterminé sur la base de l'erreur d'échantillonnage admissible, sur la base de la probabilité sur la base de laquelle il est possible de garantir le taux d'erreur à fixer, et enfin sur la base de la méthode de sélection.
Les formules pour la taille d'échantillon requise pour diverses méthodes d'échantillonnage peuvent être dérivées des ratios correspondants utilisés dans le calcul des erreurs d'échantillonnage marginales. Voici les expressions les plus couramment utilisées dans la pratique pour la taille d'échantillon requise :
échantillonnage aléatoire et mécanique approprié :
(resélection)
![]() (sélection non répétée)
(sélection non répétée)
exemple type :
(resélection)
![]() (sélection non répétée)
(sélection non répétée)
échantillonnage en série :
(resélection)
(sélection non répétée)
Dans ce cas, selon les objectifs de l'étude, les variances et les erreurs d'échantillonnage peuvent être calculées pour la valeur ou la proportion moyenne du trait.
Considérons des exemples de détermination de la taille d'échantillon requise pour diverses méthodes de formation d'un échantillon de population.
Exemple 5 Dans 100 agences de voyages de la ville, il est prévu de mener une enquête sur le nombre mensuel moyen de bons vendus par la méthode de sélection mécanique. Quelle devrait être la taille de l'échantillon pour qu'avec une probabilité de 0,683 l'erreur ne dépasse pas 3 bons, si, selon l'enquête pilote, la variance est de 225.
Solution. Calculez la taille d'échantillon requise :
Agences.
Exemple 6 Afin de déterminer la proportion d'employés des banques commerciales de la région âgés de plus de 40 ans, il est prévu d'organiser un échantillon type proportionnel au nombre d'employés hommes et femmes avec une sélection mécanique au sein des groupes. Le nombre total d'employés de banque est de 12 000 personnes, dont 7 000 hommes et 5 000 femmes.
D'après les enquêtes précédentes, la moyenne des variances intra-groupe est connue pour être de 1 600. Déterminez la taille d'échantillon requise avec une probabilité de 0,997 et une erreur de 5 %.
Solution. Calculez la taille totale d'un échantillon typique :
![]() personnes
personnes
Calculons maintenant le volume des groupes types individuels :
![]() personnes
personnes
![]() personnes
personnes
Ainsi, la taille requise de l'échantillon d'employés de banque est de 550 personnes, incl. 319 hommes et 231 femmes.
Exemple 7 La société par actions compte 200 équipes de travailleurs. Il est prévu de mener une enquête par sondage afin de déterminer la proportion de travailleurs atteints de maladies professionnelles. On sait que la variance inter-séries de la proportion est de 225. Avec une probabilité de 0,954, calculer le nombre d'équipes requises pour l'enquête auprès des travailleurs si l'erreur d'échantillonnage ne doit pas dépasser 5 %.
Solution. Le nombre requis de brigades sera calculé sur la base de la formule du volume d'échantillonnage non répétitif en série :
![]() brigades.
brigades.
3. Détermination de la taille d'échantillon requise
Il est très important de déterminer la taille optimale de l'échantillon, qui, avec une certaine probabilité, fournira la précision spécifiée des résultats d'observation. À mesure que la taille de l'échantillon augmente, l'erreur d'échantillonnage diminue. Mais comme les unités échantillonnées pour une enquête sont souvent détruites, les taux d'échantillonnage des unités de l'échantillon doivent être optimaux. La taille optimale de l'échantillon peut être obtenue à partir des formules d'erreur d'échantillonnage.
Tableau 8.4
Formules pour déterminer la taille optimale de l'échantillon
|
Méthode de sélection |
Pour moyen |
|
|
Répétition auto-aléatoire |
|
|
|
Aléatoire et mécanique non répétable |
|
|
|
Typologique non répétitif |
|
|
|
Série non répétitive avec des séries égales |
|
|








Les formules montrent qu'à mesure que l'erreur d'échantillonnage estimée augmente, la taille d'échantillon requise diminue considérablement.
Pour calculer la taille de l'échantillon, vous devez connaître la variance. Elle peut être empruntée à des enquêtes antérieures sur la même population ou une population similaire, ou une enquête par sondage ad hoc de petite taille peut être réalisée.
Exemple 2 : Dans l'entreprise, 100 travailleurs sur 1000 ont été interrogés dans l'ordre d'un échantillon aléatoire non répétitif et les données suivantes ont été obtenues sur leur revenu pour octobre (tableau 8.5).
Tableau 8.5
Répartition des travailleurs selon le revenu mensuel moyen
Définir:
1) le revenu mensuel moyen des salariés de cette entreprise, garantissant le résultat avec une probabilité de 0,997 ;
2) la part des travailleurs de l'entreprise avec un revenu mensuel de 19 000 roubles. et plus, garantissant un résultat avec une probabilité de 0,954 ;
3) la taille d'échantillon requise pour déterminer le revenu mensuel moyen des employés de l'entreprise, de sorte qu'avec une probabilité de 0,954, l'erreur d'échantillonnage marginale ne dépasse pas 200 roubles.
Solution:
1) Déterminons le revenu mensuel moyen des employés de cette entreprise, en garantissant le résultat avec une probabilité de 0,997.
|
n= 100 personnes N= 1000 personnes |
Solution: pour déterminer l'intervalle du revenu mensuel moyen des salariés d'une entreprise donnée dans la population générale, il est nécessaire de connaître la valeur de l'erreur marginale d'échantillonnage Depuis P \u003d 0,997, alors (selon le tableau 8.2) t= 3. Une sélection aléatoire non répétitive a été faite, selon le tableau. 8.3, nous sélectionnons la formule de calcul de l'erreur d'échantillonnage moyenne pour la moyenne :
La taille du revenu mensuel moyen des travailleurs selon l'enquête par sondage sera déterminée par la formule de la moyenne pondérée arithmétique: Des calculs supplémentaires seront effectués dans le tableau suivant :
Connaissance t Et Mille frotter. Ensuite, l'intervalle du revenu mensuel moyen des travailleurs de cette entreprise sera le suivant:
|
 et la taille du revenu mensuel moyen des travailleurs selon l'enquête par sondage
et la taille du revenu mensuel moyen des travailleurs selon l'enquête par sondage  .
. t et erreur d'échantillonnage moyenne
t et erreur d'échantillonnage moyenne  .
. , Où
, Où  est la variance de l'échantillon.
est la variance de l'échantillon. .
.



 mille roubles.
mille roubles.
 mille roubles.
mille roubles. Déterminons la valeur de l'erreur d'échantillonnage marginale :
Déterminons la valeur de l'erreur d'échantillonnage marginale : ;
; .
.Réponse: le revenu mensuel moyen des employés de cette entreprise avec une probabilité de 0,997 est de l'ordre de 18,08 mille roubles. jusqu'à 18,92 mille roubles.
2) Déterminons la part des travailleurs de l'entreprise avec un revenu mensuel de 19 000 roubles. et plus, garantissant un résultat avec une probabilité de 0,954.
|
n= 100 personnes N= 1000 personnes
|
Solution: pour déterminer l'intervalle de la part des travailleurs avec un revenu mensuel de 19 mille roubles. et surtout, il faut connaître la valeur de l'erreur marginale d'échantillonnage de la fraction L'erreur d'échantillonnage marginale est déterminée par la formule Depuis P \u003d 0,954, alors (selon le tableau 8.2) t= 2. Une sélection aléatoire non répétitive a été faite, selon le tableau. 8.3 sélectionner la formule de calcul de l'erreur d'échantillonnage moyenne pour la proportion :
La part de l'échantillon est déterminée par le rapport du nombre d'unités qui ont le trait à l'étude m au nombre total d'unités d'échantillonnage n, ou Alors l'erreur moyenne de la part est Connaissance t et déterminer la valeur de l'erreur d'échantillonnage marginale pour la part : Ensuite, l'intervalle de la part des travailleurs avec un revenu mensuel de 19 000 roubles. et au-dessus dans la population générale sera la suivante :
|

 et la proportion de travailleurs ayant ce revenu mensuel moyen selon l'échantillon O.
et la proportion de travailleurs ayant ce revenu mensuel moyen selon l'échantillon O. . Cela dépend de la valeur du facteur de confiance t et l'erreur d'échantillonnage moyenne.
. Cela dépend de la valeur du facteur de confiance t et l'erreur d'échantillonnage moyenne. , Où O- la part des travailleurs de l'entreprise avec un revenu mensuel moyen de 19 000 roubles. et plus dans l'échantillon.
, Où O- la part des travailleurs de l'entreprise avec un revenu mensuel moyen de 19 000 roubles. et plus dans l'échantillon. .
. .
.Réponse : la part des travailleurs de l'entreprise avec un revenu mensuel de 19 000 roubles. et plus, avec une probabilité de 0,954 se situe entre 19,4 % et 36,6 %.
Déterminons la taille d'échantillon requise lors de la détermination du revenu mensuel moyen des employés de l'entreprise, de sorte qu'avec une probabilité de 0,954, l'erreur d'échantillonnage marginale ne dépasse pas 200 roubles.
|
N= 1000 personnes |
Solution: la taille d'échantillon requise pour déterminer le revenu mensuel moyen est déterminée par la formule (selon le tableau 8.4) : Selon la condition du problème, on sait : avec une probabilité P = 0,954 t\u003d 2 (voir tableau. 8.2); 0,2 mille roubles;
|
 (selon l'échantillon précédent).
(selon l'échantillon précédent). personnes
personnesRéponse : pour qu'avec une probabilité de 0,954, l'erreur d'échantillonnage marginale ne dépasse pas 200 roubles, 189 personnes doivent être examinées.
4.5. Détermination de la taille de l'échantillon
La procédure de conception de l'échantillon comprend solution séquentielle des trois tâches suivantes :
Définition de l'objet d'étude;
Détermination de la structure de l'échantillon ;
Détermination de la taille de l'échantillon.
Généralement, objet d'une étude marketing est un ensemble d'objets d'observation, qui peuvent être des consommateurs, des salariés de l'entreprise, des intermédiaires, etc. Si cette population est si petite que l'équipe de recherche dispose des capacités de travail, financières et temporelles nécessaires pour établir un contact avec chacun de ses éléments, il est alors tout à fait réaliste de mener une étude continue de l'ensemble de la population. Dans ce cas, après avoir déterminé l'objet de la recherche, vous pouvez passer à la procédure suivante (choix de la méthode de collecte des données, de l'outil de recherche et de la méthode de communication avec le public).
Cependant, dans la pratique, il est très souvent impossible ou inapproprié de mener une étude continue sur l'ensemble de la population. Il peut y avoir les raisons suivantes à cela :
L'impossibilité d'entrer en contact avec certains éléments de la population ;
Des coûts déraisonnablement élevés pour mener une étude complète ou l'existence de restrictions financières qui ne permettent pas de mener une étude complète ;
Le peu de temps imparti à l'étude, dû à la perte de pertinence des informations au fil du temps ou à d'autres raisons, et qui ne permet pas la collecte, la systématisation et l'analyse de données extensives pour l'ensemble de la population.
Par conséquent, les populations importantes et dispersées sont souvent étudiées à l'aide d'un échantillon, qui, comme vous le savez, est compris comme une partie de la population, conçue pour représenter la population dans son ensemble.
La précision avec laquelle un échantillon reflète la population dans son ensemble dépend de structure et taille de l'échantillon.
Il existe deux approches de la structure de l'échantillon- probabiliste et déterministe.
Approche probabiliste de la structure de l'échantillon suppose que tout élément de la population peut être sélectionné avec une certaine probabilité (non nulle). Il existe différents types d'échantillons basés sur la théorie des probabilités (typiques, emboîtés, etc.). Le plus simple et le plus courant dans la pratique est un échantillon aléatoire simple, dans lequel chaque élément de la population a une probabilité égale d'être sélectionné pour la recherche.
L'échantillonnage probabiliste est plus précis, il permet au chercheur d'évaluer le degré de fiabilité des données qu'il a recueillies, bien qu'il soit plus compliqué et plus coûteux que l'échantillonnage déterministe.
Approche déterministe pour échantillonner la structure suppose que la sélection des éléments de la population se fait par des méthodes basées soit sur des considérations de commodité, soit sur la décision du chercheur, soit sur des groupes contingents.
pour des raisons de commodité, consiste à choisir des éléments quelconques de la population en fonction de la facilité à entrer en contact avec eux. L'imperfection de cette méthode est due, peut-être, à la faible représentativité de l'échantillon obtenu, puisque les éléments de la population qui conviennent au chercheur peuvent ne pas être des représentants suffisamment caractéristiques de la population en raison de leur sélection non aléatoire et déraisonnable.
Cependant, d'autre part, la simplicité, l'économie et l'efficacité de l'étude réalisée par cette méthode lui ont valu une diffusion assez large dans la pratique et, surtout, dans la conduite d'études préalables visant à clarifier les principaux problèmes.
Méthode d'échantillonnage basée sur décision du chercheur, consiste à choisir les éléments de la population qui, selon lui, en sont les représentants caractéristiques. Cette méthode est plus parfaite que la précédente, car elle est basée sur l'orientation vers les représentants caractéristiques de la population étudiée, bien qu'ils soient sélectionnés sur la base des idées subjectives des chercheurs à son sujet.
Méthode d'échantillonnage basée sur normes contingentes, consiste à choisir les éléments caractéristiques de la population en fonction des caractéristiques précédemment obtenues de l'ensemble de la population. Ces caractéristiques peuvent être obtenues par la réalisation d'études préalables et, contrairement à la méthode précédente, ne sont pas subjectives. Par conséquent, cette méthode est plus avancée, elle permet d'obtenir des populations d'échantillons qui ne sont pas moins représentatives que les échantillons probabilistes à des coûts nettement inférieurs pour la réalisation d'une enquête.
Après avoir choisi la structure de l'échantillon (l'approche de sa formation, le type de formation probabiliste ou de lancement d'un échantillon déterministe), le chercheur devra déterminer le volume, c'est-à-dire le nombre d'éléments de l'échantillon.
Taille de l'échantillon détermine la fiabilité des informations obtenus à la suite de son étude, ainsi que les coûts nécessaires à l'étude. La taille de l'échantillon dépend au niveau de l'homogénéité ou de la variété des objets étudiés.
Plus la taille de l'échantillon est grande, plus sa précision est élevée et plus le coût de réalisation de son enquête est élevé. Avec une approche probabiliste de la structure de l'échantillon, son volume peut être déterminé à l'aide de formules statistiques bien connues, sur la base des exigences spécifiées pour sa précision.
En pratique, plusieurs approches sont utilisées pour déterminer la taille de l'échantillon :
1. Approche arbitraire sur la base de l'application de la "règle empirique". Par exemple, on suppose sans preuve que pour obtenir des résultats précis, l'échantillon doit représenter 5 % de la population. Cette approche est simple et facile à mettre en œuvre, mais il n'est pas possible d'établir la précision des résultats obtenus. Avec une population suffisamment importante, cela peut aussi être assez coûteux.
La taille de l'échantillon peut être définie en fonction de certaines conditions prédéterminées. Par exemple, un client d'une étude de marché sait que lorsqu'il étudie l'opinion publique, l'échantillon est généralement de 1 000 à 1 200 personnes, il recommande donc au chercheur de s'en tenir à ce chiffre. Dans le cas où des enquêtes annuelles sont menées sur un marché particulier, un échantillon de même taille est utilisé chaque année. Contrairement à la première approche, ici, lors de la détermination de la taille de l'échantillon, la logique connue est utilisée, qui est cependant très vulnérable.
Par exemple, lors de la réalisation de certaines études, la précision peut être moindre que dans l'étude de l'opinion publique, et la taille de la population peut être plusieurs fois plus petite que dans l'étude de l'opinion publique. Ainsi, cette approche ne tient pas compte des circonstances actuelles et peut être assez coûteuse.
Dans certains cas, le coût de réalisation d'une enquête est utilisé comme principal argument pour déterminer la taille de l'échantillon. Ainsi, le budget des études marketing prévoit le coût de réalisation de certaines enquêtes, qui ne peut être dépassé. Évidemment, la valeur des informations reçues n'est pas prise en compte. Cependant, dans certains cas, même un petit échantillon peut donner des résultats assez précis.
Il semble raisonnable de considérer les coûts non pas de manière absolue, mais par rapport à l'utilité des informations obtenues à la suite des enquêtes. Le client et le chercheur doivent tenir compte des différentes tailles d'échantillon et des méthodes de collecte de données, des coûts, d'autres facteurs
2. Taille de l'échantillon au niveau de l'intervalle de confiance de l'erreur tolérée, qui, comme déjà mentionné, est donnée par la précision opportune des généralisations finales : d'augmenté à approximatif. Cependant, nous avons ici à l'esprit les erreurs dites aléatoires associées à la nature de toute erreur statistique. Ce sont eux qui sont calculés comme les erreurs de représentativité des échantillons probabilistes.
V. I. Paniotto donne les calculs suivants d'un échantillon représentatif avec l'hypothèse d'une erreur de 5 % (tableau 4.2).
Tableau 4.2
Tableau d'échantillons estimés
Pour une population de plus de 100 000, l'échantillon est de 400 unités. Si, toutefois, nous avons à l'esprit des populations générales de 5 000 ou plus, alors, selon les calculs du même auteur, il est possible d'indiquer l'ampleur de l'erreur d'échantillonnage réelle en fonction de son volume, ce qui est très important pour nous , en gardant à l'esprit que l'ampleur de l'erreur tolérée dépend de l'objectif de la recherche et ne doit pas nécessairement approcher le niveau de 5 %.
Tableau 4.3
Tableau de calcul
Outre les erreurs aléatoires, des erreurs systématiques sont possibles. Ils dépendent de l'organisation de l'enquête par sondage. Il s'agit de divers biais d'échantillon vers l'un des pôles du paramètre d'échantillon.
3. Taille de l'échantillon basée sur l'analyse statistique . Cette approche repose sur la détermination de la taille minimale de l'échantillon en fonction de certaines exigences de fiabilité et de fiabilité des résultats. Il est également utilisé dans l'analyse des résultats obtenus pour les sous-groupes individuels constitués dans le cadre d'un échantillon par sexe, âge, niveau d'éducation, etc. Les exigences de fiabilité et d'exactitude des résultats pour les sous-groupes individuels dictent certaines exigences pour la taille de l'échantillon dans son ensemble.
L'approche la plus théoriquement justifiée et correcte pour déterminer la taille de l'échantillon est basée sur le calcul d'intervalles fiables. Le concept de variation caractérise le degré de dissemblance (similarité) des réponses des répondants à une certaine question. Dans un sens plus strict, la variation des valeurs d'une caractéristique dans l'agrégat est la différence de ses valeurs entre différentes unités de l'agrégat donné au cours de la même période ou à un moment donné. Les résultats des réponses aux questions de l'enquête sont généralement présentés sous la forme d'une courbe de distribution (Fig. 4.1). Avec une forte similarité des réponses, ils parlent d'une faible variation (courbe de distribution étroite) et avec une faible similarité des réponses, une forte variation (large courbe de distribution).
Comme mesure de la variation, l'écart type est généralement pris, qui caractérise la distance moyenne par rapport au score moyen des réponses de chaque répondant à une question particulière.

Petite variation
forte variation
Riz. 4.1. Courbes de variation et de distribution
Étant donné que toutes les décisions de commercialisation sont prises dans des conditions d'incertitude, il est conseillé de tenir compte de cette circonstance lors de la détermination de la taille de l'échantillon. Étant donné que la définition des valeurs étudiées pour une population étroite est effectuée sur la base de statistiques d'échantillon, il est nécessaire d'établir la plage (intervalle de confiance) dans laquelle les estimations pour la population dans son ensemble devraient se situer, et l'erreur dans leur détermination.
Un intervalle de confiance est une plage dont les points extrêmes correspondent à un certain pourcentage de certaines réponses à une question. L'intervalle de confiance est étroitement lié à l'écart-type du trait étudié dans la population générale : plus il est grand, plus l'intervalle de confiance doit être large pour inclure un certain pourcentage de réponses.
Un intervalle de confiance de 95 % ou 99 % est standard dans la recherche marketing. Aucune entreprise n'effectue d'études de marché avec plusieurs échantillons. Et les statistiques mathématiques permettent d'obtenir des informations sur la distribution de l'échantillon, n'ayant que des données sur la variation d'un seul échantillon.
Un indicateur de la mesure dans laquelle une estimation qui est vraie pour la population dans son ensemble diffère d'une estimation qui est attendue pour un échantillon typique est l'erreur type. De plus, plus la taille de l'échantillon est grande, plus l'erreur est faible. Une valeur de variation élevée entraîne une valeur d'erreur élevée et vice versa.
Lorsqu'une question donnée n'a que deux réponses, exprimées en pourcentage (une mesure en pourcentage est utilisée), la taille de l'échantillon est déterminée par la formule suivante :

où n est la taille de l'échantillon ; z est l'écart normalisé déterminé sur la base du niveau de confiance sélectionné ; p est la variation trouvée pour l'échantillon ; g-(100-p); e est une erreur acceptable.
Lors de la détermination de l'indice de variation pour une certaine population, il est tout d'abord conseillé de procéder à une analyse qualitative préliminaire de la population étudiée, tout d'abord, pour établir la similitude des unités de la population sur les plans démographique, social et autres de intérêt pour le chercheur. Il est possible de mener une étude pilote, en utilisant les résultats d'études similaires menées dans le passé. Lors de l'utilisation d'une mesure de la variabilité en pourcentage, la circonstance est prise en compte que la variabilité maximale est atteinte pour p = 50 %, ce qui est le pire des cas. De plus, cet indicateur n'affecte pas radicalement la taille de l'échantillon. L'avis du client de l'étude sur la taille de l'échantillon est également pris en compte.
Il est possible de déterminer la taille de l'échantillon en utilisant des moyennes plutôt que des pourcentages.

où s est l'écart type.
En pratique, si l'échantillon est reconstitué et qu'aucune enquête similaire n'a été menée, alors s n'est pas connu. Dans ce cas, il est conseillé de spécifier l'erreur e en fractions de l'écart type. La formule de calcul est convertie et prend la forme suivante :
 Où
Où  .
.
Ci-dessus, nous avons parlé d'agrégats de très grandes tailles. Cependant, dans certains cas, les populations ne sont pas importantes. Habituellement, si l'échantillon est inférieur à cinq pour cent de la population, la population est considérée comme importante et les calculs sont effectués selon les règles ci-dessus. Si la taille de l'échantillon dépasse 5% de la population, alors cette dernière est considérée comme petite et un facteur de correction est introduit dans les formules ci-dessus.
La taille de l'échantillon dans ce cas est déterminée comme suit :
 ,
,
Travaux pratiques n ° 8. "Détermination de la taille d'échantillon requise"
"Déterminer la taille d'échantillon requise"
Le type d'observation discontinue le plus répandu est l'observation sélective, dans laquelle toutes les unités de la population étudiée ne sont pas examinées, mais seulement une certaine partie d'entre elles est sélectionnée.
L'ensemble des objets (observations) à étudier est appelé la population générale. Population échantillon ou échantillon appelée la partie de la population générale, sélectionnée pour l'étude des propriétés assurant la représentativité.
La sélection dans la population générale est effectuée de manière à obtenir, sur la base de l'échantillon, une idée assez précise des principaux paramètres de la population dans son ensemble. Dans ce cas, nous parlons à la fois d'une estimation ponctuelle, qui est considérée comme la valeur correspondante de la moyenne, de la part, etc., obtenue à la suite de l'échantillon, et d'une estimation d'intervalle, c'est-à-dire sur les limites dans lesquelles, avec une certaine probabilité, la valeur du paramètre recherché dans la population générale peut se situer. La principale exigence à laquelle l'échantillon doit répondre est celle de sa représentativité, c'est-à-dire représentativité.
En statistique, les résultats de l'observation continue sont parfois évalués comme des caractéristiques sélectives. Une telle interprétation des données obtenues a lieu dans les cas où le nombre d'unités examinées est petit et il n'y a aucune certitude ferme que les caractéristiques étudiées ne peuvent pas prendre d'autres valeurs que celles identifiées à la suite de l'observation. Lors de la réalisation d'expériences, le nombre de valeurs peut être infiniment grand. Par conséquent, lors de la formulation de conclusions basées sur leur nombre limité, il est nécessaire de considérer les données obtenues comme des caractéristiques sélectives.
Lorsque l'on étend les résultats d'une enquête par sondage à la population générale, il convient de garder à l'esprit qu'il peut y avoir un écart entre les caractéristiques de la population générale et de l'échantillon, du fait que l'on n'enquête pas sur l'ensemble de la population, mais seulement sur une partie de celui-ci.
Erreur d'observation statistique la valeur de l'écart entre les valeurs calculées et réelles des caractéristiques des objets à l'étude est prise en compte.
La méthode d'échantillonnage permet d'importantes économies de ressources matérielles et financières lors de la réalisation d'observations statistiques, ce qui permet d'élargir le programme d'enquête et d'augmenter son efficacité. Le deuxième avantage est la grande fiabilité des données obtenues, puisqu'avec une taille d'échantillon relativement réduite, il est possible d'organiser un contrôle efficace de la qualité des informations recueillies. Ainsi, la probabilité d'occurrence d'erreurs d'enregistrement et de leur non-détection au stade de la vérification des informations primaires est réduite. Et enfin, dans un certain nombre de cas, lorsque l'observation continue est associée à la destruction ou à la détérioration des unités examinées (par exemple, lors du contrôle de la qualité des produits alimentaires entrant sur le marché), seule une enquête sélective est possible.
La précision des estimations obtenues sur la base de la méthode d'échantillonnage ne dépend pas de la proportion d'unités enquêtées, mais de leur nombre.
Les grandes étapes de l'observation sélective;
1) détermination de l'objectif, des tâches et élaboration d'un programme d'observation ;
2) échantillonnage ;
3) collecte de données basée sur le programme développé ;
4) analyse des résultats obtenus et calcul des principales caractéristiques de l'échantillon ;
5) calcul de l'erreur d'échantillonnage et distribution de ses résultats à la population générale.
Distinguer types d'échantillons:
1) aléatoire(en fait aléatoire);
2) mécanique(par exemple, tous les 10, 20, etc.) ;
3) typique (stratifié), lorsque la population générale est divisée en groupes et que plusieurs objets sont examinés dans chaque groupe));
4) en série (imbrication) lorsque des séries entières sont sélectionnées au hasard.
La façon la plus simple de former un échantillon de population est de sélection aléatoire appropriée. Les fondements théoriques de la méthode d'échantillonnage, développés à l'origine en relation avec la sélection aléatoire proprement dite, sont également utilisés pour déterminer les erreurs d'échantillonnage dans d'autres méthodes d'observation.
En fait, la sélection aléatoire peut être répétée et non répétée. À répété En sélection, chaque unité tirée au hasard dans la population générale, après retour de l'observation à cette population, peut être réexaminée. En pratique, ce mode de sélection est rare. Beaucoup plus commun est en fait aléatoire non répétitif sélection dans laquelle les unités enquêtées ne sont pas retournées à la population et ne peuvent pas être ré-enquêtées. Avec la sélection répétée, la probabilité d'être inclus dans l'échantillon pour chaque unité de la population générale reste inchangée. Avec la sélection non répétitive, cela change, mais pour toutes les unités restant dans la population générale après la sélection de plusieurs unités de celle-ci, la probabilité d'être incluse dans l'échantillon est la même.
Les populations sont souvent détenues par de grands groupes de personnes. Il est souvent erroné de penser que la fiabilité des résultats sera plus élevée si les questions sont répondues par chaque membre de la société. En raison des énormes coûts de temps, d'argent et de main-d'œuvre, un tel examen est inacceptable. Avec une augmentation du nombre de répondants, non seulement les coûts augmenteront, mais le risque de recevoir des données incorrectes augmentera également. D'un point de vue pratique, de nombreux questionnaires et codeurs réduiront la probabilité d'un contrôle fiable de leurs actions. Une telle enquête est dite continue.
En sociologie, une étude discontinue, ou une méthode sélective, est le plus souvent utilisée. Ses résultats peuvent être étendus à un large ensemble de personnes, que l'on appelle le général.
Définition et signification de la méthode d'échantillonnage
La méthode d'échantillonnage est une méthode quantitative de sélection d'une partie des unités étudiées dans la masse totale, tandis que les résultats de l'enquête s'appliqueront à chaque individu n'y ayant pas participé.
La méthode d'échantillonnage est à la fois un objet de recherche scientifique et une discipline académique. Il agit comme un moyen d'obtenir des informations fiables sur la population générale et permet d'évaluer tous ses paramètres. Les conditions de sélection des unités affectent ensuite l'analyse statistique des résultats. Si les procédures d'échantillonnage sont mal mises en œuvre, l'utilisation des méthodes de traitement des informations collectées, même les plus fiables, sera inutile.

Concepts clés de la théorie du choix
Ils appellent la relation d'unités, par rapport à laquelle les conclusions de l'étude de l'échantillon sont formulées. Il peut s'agir de résidents d'un pays, d'une localité spécifique, de l'équipe de travail d'une entreprise, etc.
L'échantillon (ou l'échantillon) fait partie du général, qui a été sélectionné à l'aide de méthodes et de critères spéciaux. Par exemple, des critères statistiques sont pris en compte dans le processus de formation.
Le nombre d'individus inclus dans un ensemble donné est appelé son volume. Mais cela peut être exprimé non seulement par le nombre de personnes, mais aussi par les bureaux de vote, les colonies, c'est-à-dire certainement de grandes unités qui incluent des unités d'observation. Mais c'est déjà un échantillon à plusieurs degrés.
L'unité de sélection est constituée par les éléments constitutifs de la population générale, il peut s'agir soit directement d'unités d'observation (échantillonnage à un degré) soit de formations plus importantes.
Une propriété telle que la représentativité de la sélection joue un rôle important dans l'obtention de résultats de recherche fiables à l'aide d'une méthode d'échantillonnage. C'est-à-dire que la partie de la population générale qui est devenue répondante doit reproduire pleinement toutes ses caractéristiques. Tout écart est considéré comme une erreur.

Étapes d'application de la méthode d'échantillonnage
Chaque empirique se compose d'étapes. Si la méthode d'échantillonnage est appliquée, leur ordre sera organisé comme suit :
- Création d'un échantillon préliminaire : la population générale est établie, les procédures de sélection, les volumes sont caractérisés.
- Mise en œuvre du projet : dans le cadre de la collecte d'informations sociologiques, les questionnaires effectuent des tâches avec indication du mode de sélection des répondants.
- Identification et correction des erreurs de représentativité.
Types d'échantillons en sociologie
Après avoir déterminé la population générale, le chercheur procède à des procédures sélectives. Ils peuvent être divisés en deux types (critères) :
- Le rôle des lois probabilistes dans le déroulement de l'échantillonnage.
- Le nombre d'étapes de sélection.
Si le premier critère est appliqué, alors la méthode d'échantillonnage aléatoire et de sélection non aléatoire est distinguée. Sur la base de ce dernier, on peut affirmer que l'échantillon peut être à un ou plusieurs degrés.
Les types d'échantillons se reflètent directement non seulement dans les étapes de préparation et de conduite de l'étude, mais également dans ses résultats. Avant de privilégier l'un d'entre eux, vous devez comprendre le contenu des concepts.
La définition de "aléatoire" dans l'usage quotidien a reçu une signification complètement opposée à celle des mathématiques. Une telle sélection est effectuée selon des règles strictes, aucune dérogation n'est autorisée, car il est important de s'assurer que chaque unité de la population générale a les mêmes chances d'être incluse dans l'échantillon. Si ces conditions ne sont pas remplies, cette probabilité sera différente.
À son tour, l'échantillon aléatoire est divisé en :
- simple;
- mécanique (systématique);
- imbrication (série, cluster);
- stratifié (typique ou zoné).
Une méthode d'échantillonnage simple est réalisée à l'aide d'une table de nombres aléatoires. Initialement, la taille de l'échantillon est déterminée ; une liste complète des répondants numérotés inclus dans la population générale est créée. Des tableaux spéciaux contenus dans des publications mathématiques et statistiques sont utilisés pour la sélection. Tout autre qu'eux est interdit. Si la taille de l'échantillon est un nombre à trois chiffres, le numéro de chaque unité d'échantillonnage doit être à trois chiffres, à savoir de 001 à 790. Le dernier chiffre indique le nombre total de personnes. L'étude impliquera les personnes auxquelles un numéro a été attribué dans la plage spécifiée, indiquée dans le tableau.

La sélection systématique est basée sur des calculs. Une liste alphabétique de tous les éléments de la population générale est préalablement compilée, l'étape est définie, et alors seulement - la taille de l'échantillon. La formule d'une étape est la suivante :
N : n, où N est la population et n est l'échantillon.
Par exemple, 150 000 : 5 000 = 30. Ainsi, chaque trentième personne sera sélectionnée pour participer à l'enquête.
Entité de type nid
Un échantillon groupé est utilisé lorsque la population de personnes à l'étude est constituée de petits groupes naturels. Dans ce cas, il convient de noter que le numéro de liste de ces nids est déterminé à la première étape. À l'aide d'une table de nombres aléatoires, une sélection est effectuée et une enquête continue auprès de tous les répondants de chaque nid sélectionné est menée. De plus, plus ils sont nombreux à participer à l'étude, plus l'erreur d'échantillonnage moyenne est faible. Cependant, il est possible d'utiliser une telle technique à condition que les nids étudiés aient une caractéristique similaire.
L'essence du choix stratifié
Un échantillon stratifié diffère des précédents en ce qu'à la veille de la sélection, la population générale est divisée en strates, c'est-à-dire en parties homogènes qui ont une caractéristique commune. Par exemple, le niveau d'éducation, les préférences électorales, le niveau de satisfaction à l'égard de divers aspects de la vie. L'option la plus simple consiste à séparer les sujets par sexe et par âge. En principe, il est nécessaire de procéder à la sélection de telle manière qu'un nombre de personnes proportionnel au nombre total soit distingué de chaque strate.
La taille de l'échantillon dans ce cas peut être plus petite que dans une situation de sélection aléatoire, mais la représentativité sera plus élevée. Il faut reconnaître que l'échantillonnage stratifié sera le plus coûteux en termes financiers et informationnels, et l'échantillonnage emboîté sera le plus avantageux à cet égard.

Échantillonnage par quota non aléatoire
Il existe également un échantillon de quota. C'est le seul type de sélection non aléatoire qui a une justification mathématique. L'échantillon de quota est formé d'unités qui doivent être représentées par des proportions et correspondre à la population générale. Sous cette forme, une distribution ciblée des fonctionnalités est effectuée. Si les opinions et les évaluations des personnes font partie des caractéristiques étudiées, le sexe, l'âge et l'éducation des répondants sont souvent des quotas.
Dans une étude sociologique, on distingue également deux méthodes de sélection : répétée et non répétée. Dans le premier cas, l'unité sélectionnée après l'enquête est renvoyée dans la population générale afin de continuer à participer à la sélection. Dans la deuxième option, les répondants sont triés, ce qui augmente les chances que les membres restants de la population soient sélectionnés.
Le sociologue G. A. Churchill a élaboré la règle suivante : la taille de l'échantillon doit s'efforcer de fournir au moins 100 observations pour la composante de classification primaire et 20 à 50 pour la composante de classification secondaire. Il convient de garder à l'esprit que certains des répondants inclus dans l'échantillon, pour diverses raisons, peuvent ne pas participer à l'enquête ou la refuser complètement.

Méthodes de détermination de la taille de l'échantillon
Dans la recherche sociologique, les méthodes suivantes sont applicables:
1. Arbitraire, c'est-à-dire que la taille de l'échantillon est déterminée entre 5 et 10 % de la composition de la population générale.
2. La méthode de calcul traditionnelle repose sur la réalisation d'enquêtes régulières, par exemple une fois par an, auprès de 600, 2 000 ou 2 500 répondants.
3. Statistique - est d'établir la fiabilité de l'information. La statistique en tant que science ne se développe pas dans l'isolement. Les sujets et domaines de ses recherches s'inscrivent activement dans d'autres domaines connexes : technique, économique et humanitaire. Ainsi, ses méthodes sont utilisées en sociologie, dans la préparation des enquêtes et, en particulier, dans la détermination de la taille des échantillons. La statistique en tant que science repose sur une vaste base méthodologique.
4. Cher, dans lequel le montant admissible des dépenses de recherche est établi.
5. La taille de l'échantillon peut être égale au nombre d'unités de la population générale, alors l'étude sera continue. Cette approche est applicable en petits groupes. Par exemple, la main-d'œuvre, les étudiants, etc.
Auparavant, il était possible d'établir que l'échantillon sera considéré comme représentatif lorsque ses caractéristiques décrivent les propriétés de la population générale avec une erreur minimale.
L'estimation de la taille de l'échantillon précède les calculs finaux du nombre d'unités qui seront sélectionnées dans la population générale :
n \u003d Npqt 2: N∆ 2 p + pqt 2 , dans lequel N est le nombre d'unités de la population générale, p est la part du trait étudié (q \u003d 1 - p), t est le coefficient de correspondance de la probabilité de confiance P (déterminée par une table spéciale), ∆ p - erreur autorisée.
Il ne s'agit là que d'une variation sur la façon dont la taille de l'échantillon est calculée. La formule peut changer en fonction des conditions et des critères d'étude sélectionnés (par exemple, rééchantillonnage ou échantillonnage sans réplication).
Erreurs d'échantillonnage
Les enquêtes sociologiques auprès de la population reposent sur l'utilisation d'un des types d'échantillonnage que nous avons envisagé plus haut. Cependant, dans tous les cas, la tâche de chaque chercheur devrait être d'évaluer le degré de précision des indicateurs obtenus, c'est-à-dire qu'il est nécessaire de déterminer dans quelle mesure ils reflètent les caractéristiques de la population générale.
Les erreurs d'échantillonnage peuvent être divisées en erreurs aléatoires et non aléatoires. Le premier type implique l'écart de l'indicateur de l'échantillon par rapport à l'indicateur général, qui peut être exprimé par la différence de leurs parts (moyenne) et qui n'est causé que par un type d'enquête non continu. Et c'est tout naturellement que cet indicateur diminue dans un contexte d'augmentation du nombre de répondants interrogés.
Une erreur systématique est un écart par rapport à l'indicateur général, également constaté à la suite de la soustraction de l'échantillon et des parts générales et résultant de l'incohérence de la méthodologie d'échantillonnage avec les règles établies.
Ces types d'erreurs sont inclus dans l'erreur d'échantillonnage totale. Dans une étude, un seul échantillon peut être prélevé dans la population. Le calcul de l'écart maximal possible de l'indicateur d'échantillon peut être effectué à l'aide d'une formule spéciale. C'est ce qu'on appelle l'erreur marginale d'échantillonnage. Il y a aussi une chose telle que l'erreur d'échantillonnage moyenne. Il s'agit de l'écart type de l'échantillon par rapport à la part générale.
Il existe également une erreur de type a posteriori (post-expérimentale). Cela signifie l'écart des indicateurs de l'échantillon par rapport à la part générale (moyenne). Il est calculé en comparant l'indicateur général, dont les informations proviennent de sources fiables, et l'échantillon, qui a été constitué lors de l'enquête. Les départements du personnel des entreprises, les organismes statistiques nationaux agissent souvent comme des sources d'informations fiables.
Il existe également une erreur a priori, qui est également l'écart de l'échantillon et des indicateurs généraux, qui peut être exprimé comme la différence entre leurs parts et peut être calculé à l'aide d'une formule spéciale.

Dans la recherche en éducation, les erreurs suivantes sont le plus souvent commises lors de la sélection des répondants pour une enquête :
1. Ensembles d'échantillons de groupes appartenant à différentes populations générales. Lorsqu'elles sont utilisées, des inférences statistiques sont développées qui s'appliquent à l'ensemble de l'échantillon. Il est bien évident que cela ne peut être acceptable.
2. Les capacités organisationnelles et financières du chercheur ne sont pas prises en compte lors de l'examen des types d'échantillons et l'un d'entre eux est privilégié.
3. Les critères statistiques de la structure de la population générale ne sont pas pleinement utilisés pour éviter les erreurs d'échantillonnage.
4. Les exigences de représentativité de la sélection des répondants dans le cadre d'études comparatives ne sont pas prises en compte.
5. Les instructions à l'enquêteur doivent être adaptées au type spécifique de sélection adopté.
La nature de la participation des répondants à l'étude peut être ouverte ou anonyme. Cela doit être pris en compte lors de la constitution de l'échantillon, car, en désaccord avec les conditions, les participants peuvent partir.
Le nombre total d'objets d'observation (personnes, ménages, entreprises, établissements, etc.) avec un certain ensemble de caractéristiques (sexe, âge, revenu, nombre, chiffre d'affaires, etc.), limitées dans l'espace et dans le temps. Exemples de population
- Tous les résidents de Moscou (10,6 millions de personnes selon le recensement de 2002)
- Hommes moscovites (4,9 millions selon le recensement de 2002)
- Personnes morales russes (2,2 millions début 2005)
- Commerces de détail vendant des produits alimentaires (20 000 début 2008), etc.
Échantillon (échantillon de population)
Une partie des objets de la population sélectionnés pour l'étude afin de tirer une conclusion sur l'ensemble de la population. Pour que la conclusion obtenue en étudiant l'échantillon soit étendue à l'ensemble de la population, l'échantillon doit avoir la propriété d'être représentatif.
Représentativité de l'échantillon
La propriété de l'échantillon de refléter correctement la population générale. Le même échantillon peut ou non être représentatif de différentes populations.
Exemple:
- Un échantillon composé uniquement de Moscovites possédant une voiture ne représente pas l'ensemble de la population de Moscou.
- L'échantillon d'entreprises russes comptant jusqu'à 100 salariés ne représente pas toutes les entreprises en Russie.
- L'échantillon de Moscovites effectuant des achats sur le marché ne représente pas le comportement d'achat de tous les Moscovites.
Dans le même temps, ces échantillons (sous réserve d'autres conditions) peuvent parfaitement représenter les propriétaires de voitures moscovites, les petites et moyennes entreprises russes et les acheteurs effectuant des achats sur les marchés, respectivement.
Il est important de comprendre que la représentativité de l'échantillon et l'erreur d'échantillonnage sont des phénomènes différents. La représentativité, contrairement à l'erreur, ne dépend pas de la taille de l'échantillon.
Exemple:
Peu importe à quel point nous augmentons le nombre de propriétaires de voitures Moscovites interrogés, nous ne pourrons pas représenter tous les Moscovites avec cet échantillon.
Erreur d'échantillonnage (intervalle de confiance)
L'écart des résultats obtenus à l'aide de l'observation d'un échantillon par rapport aux données réelles de la population générale.
Il existe deux types d'erreur d'échantillonnage : statistique et systématique. L'erreur statistique dépend de la taille de l'échantillon. Plus la taille de l'échantillon est grande, plus elle est faible.
Exemple:
Pour un échantillon aléatoire simple de 400 unités, l'erreur statistique maximale (avec une confiance de 95%) est de 5%, pour un échantillon de 600 unités - 4%, pour un échantillon de 1100 unités - 3% .
L'erreur systématique dépend de divers facteurs qui ont un impact constant sur l'étude et biaisent les résultats de l'étude dans une certaine direction.
Exemple:
- L'utilisation de tout échantillon probabiliste sous-estime la proportion de personnes à revenu élevé qui sont actives. Cela est dû au fait que ces personnes sont beaucoup plus difficiles à trouver dans un endroit particulier (par exemple, à la maison).
- Le problème des répondants qui refusent de répondre aux questions (la part des "refuseniks" à Moscou, pour différentes enquêtes, varie de 50% à 80%)
Dans certains cas, lorsque les vraies distributions sont connues, le biais peut être nivelé en introduisant des quotas ou en repondérant les données, mais dans la plupart des études réelles, même l'estimation peut être assez problématique.
Types d'échantillons
Les échantillons sont divisés en deux types :
- probabiliste
- improbabilité
1. Échantillons probabilistes
1.1 Échantillonnage aléatoire (sélection aléatoire simple)
Un tel échantillon suppose l'homogénéité de la population générale, la même probabilité de disponibilité de tous les éléments, la présence d'une liste complète de tous les éléments. Lors de la sélection des éléments, en règle générale, une table de nombres aléatoires est utilisée.
1.2 Échantillonnage mécanique (systématique)
Une sorte d'échantillon aléatoire, trié par un attribut (ordre alphabétique, numéro de téléphone, date de naissance, etc.). Le premier élément est sélectionné au hasard, puis chaque 'k'ème élément est sélectionné par incréments de 'n'. La taille de la population générale, tandis que - N=n*k
1.3 Stratifié (zoné)
Il est utilisé en cas d'hétérogénéité de la population générale. La population générale est divisée en groupes (strates). Dans chaque strate, la sélection est effectuée de manière aléatoire ou mécanique.
1.4 Échantillonnage en série (emboîté ou groupé)
Avec l'échantillonnage en série, les unités de sélection ne sont pas les objets eux-mêmes, mais des groupes (grappes ou nids). Les groupes sont choisis au hasard. Les objets au sein des groupes sont examinés partout.
2. Des échantillons incroyables
La sélection dans un tel échantillon s'effectue non pas selon les principes du hasard, mais selon des critères subjectifs - accessibilité, typicité, représentation paritaire, etc.
2.1. Échantillonnage par quotas
Initialement, un certain nombre de groupes d'objets sont attribués (par exemple, les hommes âgés de 20 à 30 ans, de 31 à 45 ans et de 46 à 60 ans; les personnes ayant un revenu allant jusqu'à 30 000 roubles, avec un revenu de 30 à 60 ans mille roubles et avec un revenu de plus de 60 mille roubles ) Pour chaque groupe, le nombre d'objets à enquêter est spécifié. Le nombre d'objets devant appartenir à chacun des groupes est fixé, le plus souvent, soit proportionnellement à la part connue du groupe dans la population générale, soit identique pour chaque groupe. Au sein des groupes, les objets sont choisis au hasard. L'échantillonnage par quota est assez souvent utilisé.
2.2. Méthode boule de neige
L'échantillon est construit comme suit. Chaque répondant, en commençant par le premier, est invité à contacter ses amis, collègues, connaissances qui rempliraient les conditions de sélection et pourraient participer à l'étude. Ainsi, à l'exception de la première étape, l'échantillon est constitué avec la participation des objets d'étude eux-mêmes. La méthode est souvent utilisée lorsqu'il est nécessaire de trouver et d'interroger des groupes de répondants difficiles à atteindre (par exemple, les répondants à revenu élevé, les répondants appartenant au même groupe professionnel, les répondants qui ont des passe-temps/passions similaires, etc. )
2.3 Échantillonnage spontané
Les répondants les plus accessibles sont interrogés. Des exemples typiques d'échantillons spontanés se trouvent dans les journaux/magazines remis aux répondants pour qu'ils les remplissent eux-mêmes, la plupart des enquêtes sur Internet. La taille et la composition des échantillons spontanés ne sont pas connues à l'avance et sont déterminées par un seul paramètre - l'activité des répondants.
2.4 Exemple de cas typiques
Des unités de la population générale sont sélectionnées qui ont une valeur moyenne (typique) de l'attribut. Cela pose le problème du choix d'une caractéristique et de la détermination de sa valeur typique.
Cours magistral sur la théorie de la statistique
Des informations plus détaillées sur les observations d'échantillons peuvent être obtenues en les visualisant.
Calcul de la taille de l'échantillon
De toutes les questions que l'on pose au célèbre Gallup Polling Institute, la plus populaire est celle-ci : comment pouvez-vous, après avoir interrogé 1 000 personnes, juger ce que pensent 250 millions d'Américains ?
Pour répondre à cette question, il faut mentionner non seulement les hautes qualifications et la vaste expérience pratique des employés, mais aussi leur utilisation des statistiques et des mathématiques. Si les méthodes d'enquête ne sont pas fondées sur la science, les résultats peuvent être trompeurs.
En statistique, les distinctions suivantes de tailles d'échantillon sont acceptées. La taille d'échantillon suffisante pour l'annulation mutuelle du caractère aléatoire et l'obtention de caractéristiques statistiques de nature régulière est de 30. Un échantillon d'une telle taille est appelé petit. La nature de la distribution des valeurs de trait dans de petits échantillons se rapproche de la normale avec une augmentation du nombre d'essais. La taille d'échantillon minimale permettant d'obtenir les valeurs moyennes de la caractéristique avec l'indication des probabilités de confiance est de 5. Les échantillons d'une telle taille sont appelés ultra-petit. La distribution des valeurs de caractéristiques dans de tels échantillons est caractérisée par la distribution de Student. Mais la plupart des sociologies traitent d'un échantillon beaucoup plus large.
Lors de la planification d'une enquête par sondage, il arrive un moment où vous devez décider du nombre de personnes à interroger, c'est-à-dire quelle devrait être la taille de l'échantillon. Cette décision est extrêmement importante, car un échantillon trop grand coûtera cher et un échantillon trop petit réduira la qualité des résultats.
Taille de l'échantillon- le nombre total d'unités d'observation incluses dans l'échantillon.
Étant donné que l'échantillon fait partie de la population générale sélectionnée à l'aide de méthodes spéciales, il est important que cette partie ne déforme pas l'idée de l'ensemble, c'est-à-dire le représentait. Les sociologues, qui mènent souvent des recherches empiriques, sont constamment préoccupés par la question de savoir combien de personnes doivent être interrogées pour obtenir des informations fiables ? Gallup aux États-Unis mène des sondages réguliers sur un échantillon national de 1 500 personnes et atteint une précision étonnante (l'erreur d'échantillonnage varie de 1 à 1,5 %). Le Centre Socio-Express de l'Institut de Sociologie de l'Académie des Sciences de Russie mène des recherches sur un échantillon de 2 000 personnes, alors que l'erreur d'échantillonnage ne dépasse pas 3 % 31 .
Les experts estiment que le meilleur échantillon n'est pas nécessairement un grand échantillon. Bien sûr, plus la taille de l'échantillon est grande, plus la précision de ses résultats est élevée. Cependant, même un échantillon énorme ne garantit pas le succès si la population est "mal mélangée", c'est-à-dire est hétérogène. Homogène un tel ensemble est considéré dans lequel la caractéristique contrôlée est répartie uniformément, ne forme pas de vides ou d'épaississements. Dans ce cas, en interrogeant plusieurs personnes, vous pouvez obtenir des informations précises sur la distribution de cette caractéristique dans la population générale.
Ainsi, la représentativité des données n'est pas affectée par les caractéristiques quantitatives de la population de l'échantillon (son volume), mais par les caractéristiques qualitatives de la population générale - le degré de son homogénéité.
En sociologie, une formule unique et claire n'a pas encore été inventée, à l'aide de laquelle il est possible de calculer la taille optimale de l'échantillon de population - une telle formule n'existe tout simplement pas dans la nature. Et cela s'explique très simplement. Le fait est que la détermination de la taille de l'échantillon de population n'est pas tant un problème statistique qu'un problème significatif. En d'autres termes, la taille de l'échantillon de population dépend de nombreux facteurs, dont les buts et les objectifs, le modèle théorique, les hypothèses et les méthodes de recherche, le degré d'homogénéité de la population générale et enfin, la précision requise des informations reçues.
Nous devons toujours nous rappeler que chaque augmentation en pourcentage de l'exactitude des informations dans l'étude entraîne une forte augmentation du coût de sa réalisation. Le célèbre institut Gallup, qui mène des sondages aux États-Unis depuis de nombreuses décennies, a constaté qu'avec un échantillon national de 100 personnes, l'erreur d'échantillonnage sera de ± 11 % ; 200 personnes - ±8 % ; 400 - ±6 % ; 600 - ±5 % ; 750 -±4 % ; 1000 - ±4 % ; 1500 - ±3 % ; 4000 personnes - ±2%. C'est pourquoi il mène des sondages à l'échelle nationale aux États-Unis sur un échantillon de 1 500 à 2 000 personnes. Comme on peut le voir, il préfère une augmentation de 1 % de l'erreur à une augmentation multiple du coût de l'étude.
La pratique montre que pour de nombreux sociologues la justification de la taille de l'échantillon est une pierre d'achoppement, malgré l'importante littérature consacrée aux méthodes d'échantillonnage et, en particulier, au calcul de la taille de l'échantillon. Il y a plusieurs raisons : 1) manque de littérature spécialisée dans la périphérie ; 2) le manque de temps pour l'auto-éducation ; 3) incapacité à utiliser l'appareil mathématique. À cet égard, il est nécessaire d'énoncer la stratégie et les tactiques de justification de la taille de l'échantillon sans formules mathématiques complexes.
La procédure de calcul de la taille de l'échantillon est un enchaînement de compromis sans fin entre souci de précision et ressources limitées, manque de temps et information incomplète sur le phénomène étudié. C'est à la fois une science et un art dont la connaissance est accessible à tous. Cependant, pour cela, vous devez connaître les stratégies de calcul de la taille de l'échantillon (calcul préliminaire, stratégies séquentielles et combinées), ainsi que les facteurs affectant la taille de l'échantillon (taille de la population générale, variation des réponses des répondants, précision de l'estimation, nature de la distribution attendue des réponses, méthode de recherche, mode de traitement) .
Stratégie de précalcul consiste dans le fait que la taille de l'échantillon est déterminée avant l'étude principale. Dans le cas le plus simple, vous pouvez utiliser l'expérience déjà acquise, par exemple l'Institut Gallup, qui utilise un échantillon d'environ 1 500 à 2 000 personnes. Pour une étude nationale moyenne, la taille de l'échantillon est d'environ 400 à 600 personnes.
Pour calculer la taille d'un échantillon aléatoire, il est nécessaire de connaître la précision d'estimation souhaitée, l'ampleur du risque de la réponse reçue et le degré de variabilité de la réponse. Traditionnellement, la précision de l'estimation est de 5 % et la valeur de risque est de 0,95. En d'autres termes, si, selon l'étude par sondage, 60% des répondants sont satisfaits de leur travail, alors on peut affirmer que dans la population générale la part des satisfaits sera de 55 à 65% dans 95% des cas. , et dans 5 % des cas cette proportion peut dépasser cet intervalle. En supposant une précision de 5 % et une valeur de risque de 0,95, la taille de l'échantillon serait la suivante (tableau 2.4).
Tableau 2.4 Dépendance de la taille de l'échantillon à la taille de la population générale
Les résultats sont donnés dans le tableau. 2.4 témoignent contre une idée fausse courante selon laquelle la taille de l'échantillon est un pourcentage rigidement fixé de la population générale, égal à 10. En fait, cette valeur n'est pas une constante, mais une variable qui change dans des conditions spécifiques. La taille de l'échantillon dépend également des questions utilisées dans le questionnaire. Les chiffres du tableau. 2.4 n'est valable que pour un cas - lorsqu'il s'agit d'une question dichotomique, dans laquelle la dispersion maximale des réponses est de 50 à 50 %. Sans information préalable sur la dispersion des estimations, le sociologue s'assure en quelque sorte d'avance et estime que cette dispersion sera de 50 à 50 %. Si de telles informations sont disponibles, la taille de l'échantillon sera la suivante.
Tableau 2.5 Dépendance de la taille de l'échantillon à la distribution de la réponse dichotomique
En tableau. 2.5 montre la distribution des réponses aux questions qualitatives. Le calcul de la taille de l'échantillon pour les questions quantitatives, y compris les questions telles que «l'âge» et le «salaire», est basé sur le coefficient de variation (tableau 2.6), qui montre quel pourcentage est l'écart type par rapport à la moyenne arithmétique, et vous permet de comparer les uns avec les autres (selon le degré de variation) tous les signes.
Tableau 2.6 Dépendance de la taille de l'échantillon sur le coefficient de variation
| Le coefficient de variation, % | ||||||||||||
| Taille de l'échantillon |
Si les conditions de travail, les relations dans l'équipe, les salaires, etc. sont étudiés. en utilisant une échelle à cinq membres, le coefficient de variation varie ici de 27 à 62 %, et en utilisant une échelle à sept membres, de 78 à 113 %. Par conséquent, plus l'échelle est longue, plus le coefficient de variation est élevé et plus la taille de l'échantillon doit être grande. Si le sociologue veut se débrouiller avec un petit échantillon, alors les questions doivent être formulées de manière plus simple. On pense parfois que plus l'échelle est longue, plus la mesure est précise. Mais les avantages des échelles à sept points par rapport aux échelles à cinq points n'ont pas été prouvés.
Il est largement admis parmi les sociologues que plus la taille de l'échantillon est grande, plus le résultat est précis, ce qui les oblige à augmenter de manière exorbitante le nombre de répondants. En réalité, la situation est différente : tab. La figure 2.7, compilée à partir des données Gallup, montre la relation entre la taille de l'échantillon et le pourcentage de précision. Il s'ensuit qu'avec une augmentation de la taille de l'échantillon, la précision augmente, mais jusqu'à un certain seuil. Déjà avec 600 répondants, le niveau de précision souhaité de 5 % est atteint. Par conséquent, 600 personnes est une taille d'échantillon acceptable.
Il n'y a pas de contradiction entre les chiffres de 400 et 600 personnes. Dans le premier cas, la taille de l'échantillon a été calculée sur la base de la disposition sur la distribution normale des réponses des répondants, et dans le second - de la pratique. L'écart entre la théorie et la pratique est dû au fait que, dans une situation réelle, la distribution des estimations diffère de la normale, de sorte que la taille de l'échantillon doit être calculée en tenant compte précisément de cette circonstance ; le moyen le plus efficace de réduire la taille de l'échantillon consiste à réduire le coefficient de variation des estimations.
Tableau 2.7 Relation entre la taille de l'échantillon et la précision de l'estimation
Lors du calcul de la taille de l'échantillon, les sociologues commettent souvent l'erreur suivante: après avoir calculé la taille d'échantillon requise pour l'ensemble de la population à l'aide de formules existantes, ils l'attribuent ensuite proportionnellement aux subdivisions individuelles de l'échantillon, par exemple, par ateliers, entreprises, districts , villes, types de familles. Après cela, au stade du traitement des données, les différences entre les départements eux-mêmes sont analysées. Cependant, il est plus correct de calculer la taille de l'échantillon séparément pour chaque division, puis d'additionner les volumes individuels. Supposons que des calculs de la taille de l'échantillon pour trois magasins (tenant compte de la dimension de l'échelle, du nombre d'employés, de la nature de la distribution attendue des devis) aient permis d'établir que dans le premier magasin il faut demander 384 personnes, dans le second - 222 et dans le troisième - 600. La taille totale de l'échantillon sera alors de 384 + 222 + 600 = 1206 personnes.
Si un sociologue doit interroger une certaine catégorie de travailleurs (par exemple, les chauffeurs de bus), dont on sait seulement qu'elle appartient, par exemple, au dixième employé de l'entreprise, et qu'il décide de demander à 139 chauffeurs de bus, et l'échantillon total la taille de l'entreprise sera de 1390 personnes, celles-ci. autrement dit, en sélectionnant au hasard 1390 répondants dans l'entreprise, on espère, conformément à la théorie de l'échantillonnage, identifier 139 personnes de la spécialité qui nous intéresse.
Lors du calcul d'un échantillon de quotas, les sociologues déterminent souvent arbitrairement sa taille à 1 000 personnes, en fonction de la commodité du calcul des quotas. Mais avec le même succès, vous pouvez prendre n'importe quel autre numéro rond. Plus justifiée est l'approche dans laquelle le volume de l'échantillon de quota est calculé comme pour un échantillon aléatoire. Une autre option pour calculer la taille de l'échantillon de quota consiste à utiliser la théorie des petits échantillons. Son essence : si l'objectif n'est pas fixé de donner une analyse différenciée par groupes de travailleurs, multiplier alors le nombre de gradations de questions à étudier par 25 (taille minimale statistiquement significative du groupe). Par exemple, trois variables sont étudiées : le sexe - deux catégories, l'âge - deux catégories (moins de 30 ans et plus de 30 ans), la satisfaction au travail - mesurée sur une échelle de cinq points. Ensuite, la taille d'échantillon requise pour cet exemple sera de 2x2x5x25 = 500 personnes. La taille de l'échantillon est multipliée par 2,5. Il est clair qu'avec l'augmentation du nombre de variables et du nombre de gradations, la taille de l'échantillon peut devenir catastrophique. Il n'y a qu'une seule issue : une étude détaillée du problème initial, qui vous permettra de filtrer les questions inutiles dans le questionnaire, en laissant les plus importantes. Si plusieurs hypothèses sont testées dans l'étude, la taille de l'échantillon pour tester chaque hypothèse est calculée séparément. Ainsi, lors de l'utilisation de l'échantillonnage, le nombre de questions dans le questionnaire et les hypothèses doivent être minimes.
Nous avons donc calculé la taille d'échantillon requise. Maintenant, et seulement maintenant, il faut vérifier si la valeur obtenue est compatible avec les ressources allouées. Une erreur typique de nombreux sociologues appliqués est que lors du calcul de la taille de l'échantillon, les ressources disponibles sont au premier plan ou, pire, le sociologue accepte passivement toutes les conditions dictées par le client. Ceci est fondamentalement faux pour plusieurs raisons. Premièrement, le calcul de la taille de l'échantillon vous permet de pénétrer plus profondément dans l'essence du sujet à l'étude et les spécificités des méthodes de recherche, ce qui signifie que vous pouvez raisonnablement exiger plus de ressources ou prendre la bonne décision de réduire la taille de l'échantillon. Si l'administration a refusé de fournir des ressources supplémentaires, et que les objectifs de l'étude ne permettent pas de réduire la taille de l'échantillon (c'est-à-dire que le sociologue ne peut accepter la décision de l'administration), alors il est nécessaire de passer à un autre schéma de recherche. Deuxièmement, un calcul raisonnable de la taille de l'échantillon montre le professionnalisme du sociologue et incite le client à le traiter avec plus de respect.
Stratégie de calcul séquentiel taille de l'échantillon. Lors du calcul de la taille de l'échantillon, il est souhaitable de connaître la dispersion des estimations et certains autres paramètres. Cependant, ils sont généralement inconnus. Afin d'éviter les erreurs, il est préférable de supposer qu'elles sont maximales. Le paiement de notre ignorance est le gonflement de la taille de l'échantillon au-delà de ce qui est nécessaire et des coûts financiers et temporels supplémentaires (nous devons interroger plus de personnes). Pour réduire les coûts, une stratégie cohérente est utilisée - la taille de l'échantillon n'est pas calculée à l'avance, mais dépend des résultats finaux de l'étude. Par exemple, 100 personnes sont interrogées, puis la valeur de la dispersion des estimations est fixée et, en fonction de celle-ci, la taille d'échantillon requise est calculée. S'il s'avère que 100 personnes suffisent, l'étude se termine. Sinon, le nombre requis de répondants obtient, mais pas à l'infini. Il existe un exemple bien connu de la pratique de J. Gallup, qui au début de sa carrière a activement expérimenté la taille des échantillons. En 1936, on demanda aux Américains : « Souhaitez-vous un renouvellement du National Industrial Restoration Act ? Un étrange paradoxe est apparu : J. Gallup a d'abord interrogé 500 personnes et mesuré l'erreur d'échantillonnage, puis a constamment augmenté le nombre de répondants à 30 000. Malheureusement, il a constaté que l'ajout de 29 500 répondants augmentait la précision des informations de moins de 1 %. . Par conséquent, l'enquête pourrait déjà être terminée à 500 répondants. Cet exemple montre qu'en appliquant une stratégie cohérente, une réduction significative du nombre d'observations requises peut être obtenue par rapport à un calcul préliminaire de la taille de l'échantillon.
Cependant, la stratégie de calcul séquentiel de la taille de l'échantillon n'apporte le résultat souhaité que si le sociologue peut effectuer les calculs nécessaires au cours de l'enquête elle-même, par exemple par téléphone, à l'aide de systèmes informatiques. Le sociologue saisit les réponses du répondant dans son ordinateur personnel, à partir duquel les résultats sont immédiatement envoyés à l'ordinateur du responsable de l'étude, traités, et l'écran d'affichage affiche des informations non seulement sur les fréquences unidimensionnelles réparties sur un problème particulier, mais aussi sur la taille d'échantillon requise.
S'il existe un risque que la taille de l'échantillon devienne catastrophique, il est nécessaire de combiner les deux types de stratégie - préliminaire et séquentielle, c'est-à-dire appliquer stratégie combinée. En calculant l'échantillon selon la stratégie préliminaire, nous obtenons les valeurs supérieures admissibles pour la stratégie séquentielle, ou, en d'autres termes, la valeur de la taille de l'échantillon, à laquelle l'interrogation selon la stratégie séquentielle s'arrête.
L'approche la plus raisonnable et la plus correcte pour déterminer la taille de l'échantillon est basée sur le calcul des intervalles de confiance, qui repose sur un certain nombre de concepts de base des statistiques mathématiques (variation, écart type, intervalle de confiance, erreur type).
Pour calculer la taille d'échantillon requise dans une étude quantitative, deux concepts statistiques sont le plus souvent utilisés - l'intervalle de confiance et le niveau de confiance. Intervalle de confiance est l'erreur d'échantillonnage que vous spécifiez. Par exemple, si vous définissez un intervalle de confiance de 3 % et que la réponse spécifique à une question de recherche spécifique est de 48 %, cela signifie que même si l'ensemble de la population est interrogé, la valeur réelle se situera entre 45 (48 - 3) et 51 % (48 + 3). Probabilité de confiance montre à quel point vous pouvez être confiant dans vos résultats que les caractéristiques de l'échantillon correspondent aux caractéristiques de l'ensemble de la population - en d'autres termes, avec quelle probabilité une réponse aléatoire tombera dans l'intervalle de confiance. Généralement, des niveaux de confiance de 95 % et 99 % sont utilisés. Le plus souvent, 95% est utilisé - c'est largement suffisant dans la grande majorité des études. Si nous combinons la probabilité de confiance et l'intervalle de confiance, alors nous pouvons dire que les réponses à la question avec une probabilité de 95 % se situeront entre 45 et 51 %.
L'estimation approximative suivante de la fiabilité des résultats d'une enquête par sondage est très utile. Une fiabilité accrue permet une erreur d'échantillonnage allant jusqu'à 3%, ordinaire - de 3 à 10% (intervalle de confiance des distributions au niveau de 0,03-0,1), approximatif - de 10 à 20%, approximatif - de 20 à 40%, et estimé - plus de 40%.
Sur la base de ces concepts, en tenant compte d'un certain nombre d'hypothèses, des formules de calcul de la taille de l'échantillon sont dérivées, qui supposent que la représentativité est garantie en utilisant des procédures d'échantillonnage probabiliste correctes.
Dans certains cas, le coût de réalisation d'une enquête est utilisé comme principal argument pour déterminer la taille de l'échantillon. Ainsi, le budget des études marketing prévoit le coût de réalisation de certaines enquêtes, qui ne peut être dépassé, et il est évident que la valeur des informations obtenues n'est pas prise en compte. Cependant, dans certains cas, même un petit échantillon peut donner des résultats assez précis.
La pratique de la recherche suggère la règle suivante : la taille de l'échantillon doit fournir au moins 100 observations pour chaque élément de classification primaire et au moins 20 à 50 observations pour chaque élément de classification secondaire. Les composantes primaires de la classification correspondent aux plus critiques et les secondaires correspondent aux cellules les moins critiques de la classification croisée adoptée dans cette étude 34 . Les calculs théoriques et la pratique prouvent que pour obtenir des données fiables sur l'opinion et les préférences de la population d'une ville aussi grande que Saint-Pétersbourg, il suffit d'interroger 700 à 800 personnes. Cependant, la plupart des enquêtes sur la population ici sont menées sur des échantillons allant jusqu'à 1,5 mille personnes.
Erreur d'échantillonnage
Comme nous le savons déjà, la représentativité est la propriété d'un échantillon de population de représenter une caractéristique de la population générale. S'il n'y a pas de correspondance, ils disent erreur de représentativité- le degré d'écart de la structure statistique de l'échantillon par rapport à la structure de la population générale correspondante. Supposons que le revenu familial mensuel moyen des retraités de la population générale soit de 2 000 roubles et de 6 000 roubles dans l'échantillon. Cela signifie que le sociologue n'a interrogé que la partie aisée des retraités, et une erreur de représentativité s'est glissée dans son étude. En d'autres termes, l'erreur de représentativité est décalage entre deux populations- général, vers lequel se dirige l'intérêt théorique du sociologue et une idée des propriétés dont il veut finalement recevoir, et sélectif, vers lequel se dirige l'intérêt pratique du sociologue, qui agit à la fois comme un objet d'examen et un moyen d'obtenir des informations sur la population générale.
Outre le terme "erreur de représentativité" dans la littérature nationale, vous pouvez en trouver un autre - "erreur d'échantillonnage". Parfois, ils sont utilisés de manière interchangeable, et parfois «l'erreur d'échantillonnage» est utilisée à la place de «l'erreur de représentativité» comme concept quantitativement plus précis.
Erreur d'échantillonnage- écart des caractéristiques moyennes de la population échantillon par rapport aux caractéristiques moyennes de la population générale.
En pratique, l'erreur d'échantillonnage est déterminée en comparant les caractéristiques connues de la population aux moyennes de l'échantillon. En sociologie, les enquêtes auprès de la population adulte utilisent le plus souvent les données des recensements de la population, les relevés statistiques actuels et les résultats des enquêtes précédentes. Les caractéristiques sociodémographiques sont généralement utilisées comme paramètres de contrôle. Comparaison des moyennes de la population générale et de l'échantillon, sur cette base, la détermination de l'erreur d'échantillonnage et sa réduction est appelée contrôle de la représentativité.Étant donné qu'une comparaison de ses propres données et de celles d'autres personnes peut être effectuée à la fin de l'étude, cette méthode de contrôle est appelée a postériori ceux. réalisé après expérience.
Dans les sondages Gallup, la représentativité est contrôlée par les données disponibles dans les recensements nationaux sur la répartition de la population par sexe, âge, éducation, revenu, profession, race, lieu de résidence, taille de l'agglomération. Le Centre panrusse d'étude de l'opinion publique (VTsIOM) utilise à ces fins des indicateurs tels que le sexe, l'âge, l'éducation, le type d'établissement, l'état matrimonial, le domaine d'emploi, le statut professionnel du répondant, qui sont empruntés à le Comité d'État des statistiques de la Fédération de Russie. Dans les deux cas, la population est connue. L'erreur d'échantillonnage ne peut pas être établie si les valeurs de la variable dans l'échantillon et la population sont inconnues.
Lors de l'analyse des données, les spécialistes du VTsIOM effectuent une réparation approfondie de l'échantillon afin de minimiser les écarts survenus lors du travail sur le terrain. Des changements particulièrement forts sont observés en termes de sexe et d'âge. Cela s'explique par le fait que les femmes et les diplômés du supérieur passent plus de temps à la maison et prennent plus facilement contact avec l'enquêteur ; constituent un groupe facilement accessible par rapport aux hommes et aux personnes "sans instruction".
L'erreur d'échantillonnage est due à deux facteurs : la méthode d'échantillonnage et la taille de l'échantillon.
Les erreurs d'échantillonnage sont divisées en deux types - aléatoires et systématiques. Erreur aléatoire - est la probabilité que la moyenne de l'échantillon tombe (ou ne tombe pas) en dehors de l'intervalle donné. Les erreurs aléatoires comprennent les erreurs statistiques inhérentes à la méthode d'échantillonnage elle-même. Ils diminuent avec l'augmentation de la taille de l'échantillon (tableau 2.8).
Tableau 2.8
Dépendance de la taille de l'échantillon à son erreur 36 (la taille de la population générale est de 20 000 unités)
| Erreur d'échantillonnage, % | |||||||||||||
| Taille de l'échantillon, unités |
Le deuxième type d'erreur d'échantillonnage est erreurs systématiques. Si un sociologue décide de connaître l'opinion de tous les habitants de la ville sur la politique sociale menée par les collectivités locales, et n'interroge que ceux qui ont le téléphone, alors il y a un biais délibéré dans l'échantillon en faveur des couches aisées, c'est-à-dire erreur systématique.
Ainsi, les erreurs systématiques sont le résultat de l'activité du chercheur lui-même. Ce sont les plus dangereux, car ils conduisent à des biais assez importants dans les résultats de l'étude. Les erreurs systématiques sont considérées comme pires que les erreurs aléatoires également parce qu'elles ne peuvent pas être contrôlées et mesurées.
Elles surviennent lorsque, par exemple : 1) l'échantillon ne répond pas aux objectifs de l'étude (le sociologue a décidé de n'étudier que les retraités actifs, mais a interrogé tout le monde à la suite) ; 2) il y a ignorance de la nature de la population générale (le sociologue pensait que 70% de tous les retraités ne travaillaient pas, mais il s'est avéré que seulement 10% ne travaillaient pas) ; 3) seuls les éléments « gagnants » de la population générale sont sélectionnés (par exemple, seuls les retraités aisés).
Attention!Contrairement aux erreurs aléatoires, les erreurs systématiques ne diminuent pas avec l'augmentation de la taille de l'échantillon.
Résumant tous les cas d'erreurs systématiques, les méthodologistes en ont dressé un registre. Ils pensent que les facteurs suivants peuvent être à l'origine de biais non contrôlés dans la distribution des observations de l'échantillon :
♦ les règles méthodologiques et méthodologiques pour mener des recherches sociologiques ont été violées ;
♦ des méthodes d'échantillonnage, de collecte de données et de calcul inadéquates ont été choisies;
♦ il y a eu un remplacement des unités d'observation requises par d'autres, plus accessibles ;
♦ Une couverture incomplète de la population échantillonnée (manque de questionnaires, remplissage incomplet des questionnaires, inaccessibilité des unités d'observation) a été constatée.
Les sociologues font rarement des erreurs intentionnelles. Le plus souvent, les erreurs surviennent parce que le sociologue ne connaît pas bien la structure de la population générale : la répartition des personnes par âge, profession, revenu, etc.
Les erreurs systématiques sont plus faciles à prévenir (par rapport aux erreurs aléatoires), mais elles sont très difficiles à éliminer. Il est préférable d'éviter les erreurs systématiques en anticipant avec précision leurs sources à l'avance - au tout début de l'étude.
Voilà quelque façons d'éviter les erreurs :
♦ chaque unité de la population générale doit avoir une probabilité égale d'être incluse dans l'échantillon ;
♦ il est souhaitable de sélectionner parmi des populations homogènes ;
♦ besoin de connaître les caractéristiques de la population générale ;
♦ Les erreurs aléatoires et systématiques doivent être prises en compte lors de la constitution de l'échantillon.
Si l'échantillon (ou seulement l'échantillon) est correctement conçu, alors le sociologue obtient des résultats fiables qui caractérisent l'ensemble de la population. S'il est compilé de manière incorrecte, l'erreur survenue à l'étape de l'échantillonnage est multipliée à chaque étape ultérieure de la recherche sociologique et atteint finalement une valeur supérieure à la valeur de l'étude. On dit que de telles recherches font plus de mal que de bien.
De telles erreurs ne peuvent se produire qu'avec un échantillon de population. Pour éviter ou réduire la probabilité d'erreur, le moyen le plus simple est d'augmenter la taille de l'échantillon (et idéalement à la taille de la population : lorsque les deux populations correspondent, l'erreur d'échantillonnage disparaîtra complètement). Économiquement, cette méthode est impossible. Il reste un autre moyen - d'améliorer les méthodes mathématiques d'échantillonnage. Ils sont appliqués dans la pratique. C'est la première voie de pénétration dans la sociologie des mathématiques. Le deuxième canal est le traitement mathématique des données.
Le problème des erreurs devient particulièrement important dans la recherche marketing, où des échantillons peu volumineux sont utilisés. Habituellement, ils représentent plusieurs centaines, moins souvent - un millier de répondants. Ici, le point de départ du calcul de l'échantillon est la question de la détermination de la taille de la population de l'échantillon. La taille de l'échantillon dépend de deux facteurs : i) le coût de la collecte d'informations et 2) la recherche d'un certain degré de fiabilité statistique des résultats, que le chercheur espère obtenir. Bien sûr, même les personnes qui n'ont pas d'expérience en statistique et en sociologie comprennent intuitivement que plus la taille de l'échantillon est grande, c'est-à-dire plus grande. plus elles sont proches de la taille de la population dans son ensemble, plus les données torturées sont fiables et valides. Cependant, nous avons déjà parlé plus haut de l'impossibilité pratique d'enquêtes complètes dans les cas où elles sont effectuées sur des objets dont le nombre dépasse les dizaines, les centaines de milliers et même les millions. Il est clair que le coût de la collecte d'informations (y compris le paiement de la réplication des outils, la main-d'œuvre des questionnaires, les gestionnaires de terrain et les opérateurs de saisie informatique) dépend du montant que le client est prêt à allouer, et dépend peu des chercheurs. Quant au deuxième facteur, nous y reviendrons un peu plus en détail.
Ainsi, plus la taille de l'échantillon est grande, plus l'erreur possible est petite. Bien qu'il convient de noter que si vous souhaitez doubler la précision, vous devrez augmenter l'échantillon non pas de deux, mais de quatre fois. Par exemple, pour doubler la précision des données obtenues à partir d'une enquête auprès de 400 personnes, il faudrait interroger 1 600 personnes au lieu de 800. Cependant, il est peu probable que la recherche marketing ait besoin d'une précision de 100 %. Si un brasseur a besoin de savoir quelle proportion de consommateurs de bière préfère sa marque, et non la variété de son concurrent - 60 % ou 40 %, alors la différence entre 57 %, 60 ou 63 % n'affectera pas ses plans.
L'erreur d'échantillonnage peut dépendre non seulement de sa taille, mais aussi du degré de différences entre les unités individuelles au sein de la population générale que nous étudions. Par exemple, si nous voulons savoir combien de bière est consommée, nous constaterons qu'au sein de notre population, les taux de consommation varient considérablement d'une personne à l'autre. (hétérogène population générale). Dans un autre cas, nous étudierons la consommation de pain et constaterons qu'elle varie beaucoup moins significativement d'une personne à l'autre. (homogène population générale). Plus la différence (ou l'hétérogénéité) au sein de la population est grande, plus la quantité d'erreur d'échantillonnage possible est grande. Ce modèle ne fait que confirmer ce que le simple bon sens nous dit. Ainsi, comme l'affirme à juste titre V. Yadov, « le nombre (volume) de l'échantillon dépend du niveau d'homogénéité ou d'hétérogénéité des objets étudiés. Plus ils sont homogènes, plus le nombre est petit et peut fournir des conclusions statistiquement fiables.
La détermination de la taille de l'échantillon dépend également du niveau de l'intervalle de confiance de l'erreur statistique admissible. Cela fait référence à la soi-disant aléatoire erreurs liées à la nature de toute erreur statistique. DANS ET. Paniotto donne les calculs suivants d'un échantillon représentatif avec l'hypothèse d'une erreur de 5 % (tableau 2.9) :
Tableau 2.9
Exemples de calculs représentatifs
Cela signifie que si vous, après avoir interrogé, disons, 400 personnes dans une ville de district, où la population adulte solvable est de 100 000 personnes, avez constaté que 33% des acheteurs interrogés préfèrent les produits d'une usine de transformation de viande locale, alors avec un 95 % 39 de probabilité on peut dire que 33±5% (soit de 28 à 38%) des habitants de cette ville sont des acheteurs réguliers de ces produits.
Vous pouvez également utiliser les calculs de Gallup pour estimer le rapport entre la taille des échantillons et l'erreur d'échantillonnage (voir ci-dessus).
Aujourd'hui, de nombreux calculs difficiles sont pris en charge par la technologie et des programmes statistiques sont disponibles sur Internet. Ainsi, avec le calcul de l'échantillon, le sociologue paresseux a eu une telle opportunité sur le site Web du Business and Marketing Analytical Center (http://www.bma.ru/enter.htm), où l'utilisateur n'a qu'à entrer le données nécessaires, puis cliquez sur le bouton "Calculer".
Estimation d'intervalle de probabilité d'événement. Formules de calcul du nombre d'échantillons dans le cas d'une méthode de sélection aléatoire.Pour déterminer les probabilités des événements qui nous intéressent, nous utilisons la méthode d'échantillonnage : nous effectuons n expériences indépendantes, dans chacune desquelles l'événement A peut se produire (ou ne pas se produire) (probabilité R occurrence de l'événement A dans chaque expérience est constante). Alors la fréquence relative p* des occurrences d'événements UN dans une série de n tests est pris comme une estimation ponctuelle de la probabilité p survenance d'un événement UN dans un test séparé. Dans ce cas, la valeur p* est appelée partage d'échantillon occurrences d'événements UN, et r- part générale .
En vertu du corollaire du théorème central limite (théorème de Moivre-Laplace), la fréquence relative d'un événement avec une grande taille d'échantillon peut être considérée comme normalement distribuée avec les paramètres M(p*)=p et
Ainsi, pour n>30, l'intervalle de confiance de la fraction générale peut être construit à l'aide des formules :

où u cr est trouvé selon les tables de la fonction de Laplace, en tenant compte de la probabilité de confiance donnée γ : 2Ф(u cr)=γ.
Avec une petite taille d'échantillon n≤30, l'erreur marginale ε est déterminée à partir du tableau de distribution de Student : ![]() où t cr =t(k; α) et le nombre de degrés de liberté k=n-1 probabilité α=1-γ (zone bilatérale).
où t cr =t(k; α) et le nombre de degrés de liberté k=n-1 probabilité α=1-γ (zone bilatérale).
Les formules sont valables si la sélection a été effectuée aléatoirement de manière répétée (la population générale est infinie), sinon il faut faire une correction pour la sélection non répétitive (tableau).
Erreur d'échantillonnage moyenne pour la proportion générale
| Population | Sans fin | volume ultime N |
| Type de sélection | Répété | non répétitif |
| Erreur d'échantillonnage moyenne |
Formules pour calculer la taille de l'échantillon avec une méthode de sélection aléatoire appropriée
| Méthode de sélection | Formules de taille d'échantillon | ||
| pour le milieu | pour partager | ||
| Répété | |||
| non répétitif | |||
Problèmes concernant la part générale
A la question "La valeur donnée de p 0 couvre-t-elle l'intervalle de confiance ?" - peut être répondu en testant l'hypothèse statistique H 0:p=p 0 . On suppose que les expériences sont réalisées selon le schéma de test de Bernoulli (indépendant, probabilité p survenance d'un événement UN constant). Par échantillon de volume n déterminer la fréquence relative p * d'occurrence de l'événement A : où m- nombre d'occurrences de l'événement UN dans une série de n essais. Pour tester l'hypothèse H 0, on utilise des statistiques qui, avec une taille d'échantillon suffisamment grande, ont une distribution normale standard (tableau 1).Tableau 1 - Hypothèses sur la part générale
Hypothèse | H0:p=p0 | H 0:p 1 \u003d p 2 |
| Hypothèses | Schéma de test de Bernoulli | Schéma de test de Bernoulli |
| Exemples d'estimations |  |
|
| Statistiques K | 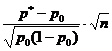 | 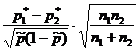 |
| Répartition des statistiques K | Norme normale N(0,1) |
Exemple 1. À l'aide d'un rééchantillonnage aléatoire, la direction de l'entreprise a mené une enquête aléatoire auprès de 900 de ses employés. Il y avait 270 femmes parmi les répondants. Tracez un intervalle de confiance qui, avec une probabilité de 0,95, couvre la véritable proportion de femmes dans l'ensemble de l'équipe de l'entreprise.
Solution. Par condition, la proportion de femmes dans l'échantillon est (la fréquence relative des femmes parmi tous les répondants). Étant donné que la sélection est répétée et que la taille de l'échantillon est grande (n = 900), l'erreur d'échantillonnage marginale est déterminée par la formule ![]()
La valeur de u cr est trouvée dans le tableau de la fonction de Laplace à partir de la relation 2Ф(u cr)=γ, c'est-à-dire ![]() La fonction de Laplace (Annexe 1) prend la valeur 0,475 à u cr =1,96. Par conséquent, l'erreur marginale
La fonction de Laplace (Annexe 1) prend la valeur 0,475 à u cr =1,96. Par conséquent, l'erreur marginale ![]() et l'intervalle de confiance souhaité
et l'intervalle de confiance souhaité
(p - ε, p + ε) = (0,3 - 0,18 ; 0,3 + 0,18) = (0,12 ; 0,48)
Ainsi, avec une probabilité de 0,95, on peut garantir que la proportion de femmes dans l'ensemble de l'équipe de l'entreprise est comprise entre 0,12 et 0,48.
Exemple #2. Le propriétaire du parking considère le jour "chanceux" si le parking est rempli à plus de 80%. Au cours de l'année, 40 inspections de parkings ont été réalisées, dont 24 ont été « réussies ». Avec une probabilité de 0,98, trouvez l'intervalle de confiance pour estimer le pourcentage réel de jours "chanceux" au cours de l'année.
Solution. La fraction d'échantillon de "bons" jours est
D'après le tableau de la fonction de Laplace, on trouve la valeur de u cr pour un
un niveau de confiance
Ф(2,23) = 0,49, u cr = 2,33.
En considérant que la sélection n'est pas répétitive (c'est-à-dire que deux contrôles n'ont pas été effectués le même jour), on trouve l'erreur marginale : ![]()
où n=40 , N = 365 (jours). D'ici ![]()
et intervalle de confiance pour la fraction générale : (p – ε, p + ε) = (0,6 – 0,17 ; 0,6 + 0,17) = (0,43 ; 0,77)
Avec une probabilité de 0,98, on peut s'attendre à ce que la proportion de "bonnes" journées au cours de l'année soit comprise entre 0,43 et 0,77.
Exemple #3. Après avoir vérifié 2 500 éléments du lot, ils ont découvert que 400 éléments étaient de la plus haute qualité, mais que n–m ne l'étaient pas. Combien de produits devez-vous vérifier pour déterminer la part du grade premium avec une précision de 0,01 avec une certitude de 95 % ?
Nous recherchons une solution selon la formule de détermination de la taille de l'échantillon pour la re-sélection.
Ф(t) = γ/2 = 0.95/2 = 0.475 et selon le tableau de Laplace cette valeur correspond à t=1.96
Fraction d'échantillon w = 0,16 ; erreur d'échantillonnage ε = 0,01
Exemple #4. Un lot de produits est accepté si la probabilité que le produit réponde à la norme est d'au moins 0,97. Parmi les 200 produits sélectionnés au hasard du lot testé, 193 produits ont été trouvés conformes à la norme. Est-il possible d'accepter le lot au seuil de signification α=0,02 ?
Solution. Nous formulons les hypothèses principales et alternatives.
H 0: p \u003d p 0 \u003d 0,97 - part générale inconnue pégale à la valeur spécifiée p 0 =0,97. Par rapport à l'état - la probabilité que la pièce du lot testé soit conforme à la norme est de 0,97 ; ceux. lot de produits peut être accepté.
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Valeur statistique observée K(tableau) calculer pour des valeurs données p 0 =0,97, n=200, m=193

La valeur critique est trouvée dans le tableau de la fonction de Laplace à partir de l'égalité
![]()
Selon la condition α=0,02, donc F(Kcr)=0,48 et Kcr=2,05. La région critique est gaucher, c'est-à-dire est l'intervalle (-∞;-K kp)= (-∞;-2.05). La valeur observée Kobs = -0,415 n'appartient pas à la région critique, donc, à ce niveau de signification, il n'y a aucune raison de rejeter l'hypothèse principale. Un lot de produits peut être accepté.
Exemple numéro 5. Deux usines produisent le même type de pièces. Pour évaluer leur qualité, des échantillons ont été prélevés sur les produits de ces usines et les résultats suivants ont été obtenus. Parmi les 200 produits sélectionnés de la première usine, 20 étaient défectueux, et parmi les 300 produits de la deuxième usine, 15 étaient défectueux.
À un niveau de signification de 0,025, découvrez s'il existe une différence significative dans la qualité des pièces fabriquées par ces usines.
Selon la condition α=0,025, donc F(Kcr)=0,4875 et Kcr=2,24. Avec une alternative bilatérale, la zone des valeurs admissibles a la forme (-2,24 ; 2,24). La valeur observée Kobs = 2,15 se situe dans cet intervalle, c'est-à-dire à ce niveau de signification, il n'y a aucune raison de rejeter l'hypothèse principale. Les usines fabriquent des produits de même qualité.