
Регрессия в Excel: уравнение, примеры. Линейная регрессия
Для оценки существенности, значимости коэффициента корреляции используется t-критерий Стьюдента.
Находится средняя ошибка коэффициента корреляции по формуле:
Н а
основе ошибки рассчитываетсяt-критерий:
а
основе ошибки рассчитываетсяt-критерий:
Рассчитанное значение t-критерия сравнивают с табличным, найденным в таблице распределения Стьюдента при уровне значимости 0,05 или 0,01 и числе степеней свободы n-1. Если расчетное значение t-критерия больше табличного, то коэффициент корреляции признается значимым.
При криволинейной связи для оценки значимости корреляционного отношения и уравнения регрессии применяется F-критерий. Он вычисляется по формуле:

или

где η – корреляционное отношение; n – число наблюдений; m – число параметров в уравнении регрессии.
Рассчитанное значение F сравнивается с табличным для принятого уровня значимости α (0,05 или 0,01) и чисел степеней свободы к 1 =m-1 и k 2 =n-m. Если расчетное значение F превышает табличное, связь признается существенной.
Значимость коэффициента регрессии устанавливается с помощью t-критерия Стьюдента, который вычисляется по формуле:

где σ 2 а i - дисперсия коэффициента регрессии.
Она вычисляется по формуле:

где к – число факторных признаков в уравнении регрессии.
Коэффициент регрессии признается значимым, если t a 1 ≥t кр. t кр отыскивается в таблице критических точек распределения Стьюдента при принятом уровне значимости и числе степеней свободы k=n-1.
4.3.Корреляционно-регрессионный анализ в Excel
Проведём корреляционно-регрессионный анализ взаимосвязи урожайности и затрат труда на 1 ц зерна. Для этого открываем лист Excel, в ячейки А1:А30 вводим значения факторного признака – урожайности зерновых культур, в ячейки В1:В30 значения результативного признака – затраттруда на 1 ц зерна. В меню Сервис выберем опцию Анализ данных. Щелкнув левой кнопкой мыши по этому пункту, откроем инструмент Регрессия. Щелкаем по кнопке OK, на экране появляется диалоговое окно Регрессия. В поле Входной интервал У вводим значения результативного признака (выделяя ячейки В1:В30), в поле Входной интервал Х вводим значения факторного признака (выделяя ячейки А1:А30). Отмечаем уровень вероятности 95%, выбираем Новый рабочий лист. Щелкаем по кнопке OK. На рабочем листе появляется таблица «ВЫВОД ИТОГОВ», в которой даны результаты вычисления параметров уравнения регрессии, коэффициента корреляции и другие показатели, позволяющие определить значимость коэффициента корреляции и параметров уравнения регрессии.
|
ВЫВОД ИТОГОВ | ||||||||
|
Регрессионная статистика | ||||||||
|
Множественный R | ||||||||
|
R-квадрат | ||||||||
|
Нормированный R-квадрат | ||||||||
|
Стандартная ошибка | ||||||||
|
Наблюдения | ||||||||
|
Дисперсионный анализ | ||||||||
|
Значимость F | ||||||||
|
Регрессия | ||||||||
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
|
|
Y-пересечение | ||||||||
|
Переменная X 1 | ||||||||
В данной таблице «Множественный R» - это коэффициент корреляции, «R-квадрат» - коэффициент детерминации. «Коэффициенты: Y-пересечение» - свободный член уравнения регрессии 2,836242; «Переменная Х1» – коэффициент регрессии -0,06654. Здесь имеются также значения F-критерия Фишера 74,9876, t-критерия Стьюдента 14,18042, «Стандартная ошибка 0,112121», которые необходимы для оценки значимости коэффициента корреляции, параметров уравнения регрессии и всего уравнения.
На основе данных таблицы построим уравнение регрессии: у х =2,836-0,067х. Коэффициент регрессии а 1 =-0,067 означает, что с повышением урожайности зерновых на 1 ц/га затраты труда на 1 ц зерна уменьшаются на 0,067 чел.-ч.
Коэффициент корреляции r=0,85>0,7, следовательно, связь между изучаемыми признаками в данной совокупности тесная. Коэффициент детерминации r 2 =0,73 показывает, что 73% вариации результативного признака (затрат труда на 1 ц зерна) вызвано действием факторного признака (урожайности зерновых).
В таблице критических точек распределения Фишера - Снедекора найдём критическое значение F-критерия при уровне значимости 0,05 и числе степеней свободы к 1 =m-1=2-1=1 и k 2 =n-m=30-2=28, оно равно 4,21. Так как рассчитанное значение критерия больше табличного (F=74.9896>4,21), то уравнение регрессии признаётся значимым.
Для оценки значимости коэффициента корреляции рассчитаем t-критерий Стьюдента:
В таблице критических точек распределения
Стьюдента найдём критическое значениеt-критерия
при уровне значимости 0,05 и числе степеней
свободы n-1=30-1=29,
оно равно 2,0452. Так как расчётное значение
больше табличного, то коэффициент
корреляции является значимым.
таблице критических точек распределения
Стьюдента найдём критическое значениеt-критерия
при уровне значимости 0,05 и числе степеней
свободы n-1=30-1=29,
оно равно 2,0452. Так как расчётное значение
больше табличного, то коэффициент
корреляции является значимым.
Проверку значимости уравнения регрессии произведем на основе
F-критерия Фишера:
Значение F-критерия Фишера можно найти в таблице Дисперсионный анализ протокола Еxcel. Табличное значение F-критерия при доверительной вероятности α = 0,95 и числе степеней свободы, равном v1 = k = 2 и v2 = n – k – 1= 50 – 2 – 1 = 47, составляет 0,051.
Поскольку Fрасч > Fтабл, уравнение регрессии следует признать значимым, то есть его можно использовать для анализа и прогнозирования.
Оценку значимости коэффициентов полученной модели, используя результаты отчета Excel, можно осуществить тремя способами.
Коэффициент уравнения регрессии признается значимым в том случае, если:
1) наблюдаемое значение t-статистики Стьюдента для этого коэффициента больше, чем критическое (табличное) значение статистики Стьюдента (для заданного уровня значимости, например α = 0,05, и числа степеней свободы df = n – k – 1, где n – число наблюдений, а k – число факторов в модели);
2) Р-значение t-статистики Стьюдента для этого коэффициента меньше, чем уровень значимости, например, α = 0,05;
3) доверительный интервал для этого коэффициента, вычисленный с некоторой доверительной вероятностью (например, 95%), не содержит ноль внутри себя, то есть нижняя 95% и верхняя 95% границы доверительного интервала имеют одинаковые знаки.
Значимость коэффициентов a 1 и a 2 проверим по второму и третьему способам:
P-значение (a 1 ) = 0,00 < 0,01 < 0,05.
Р-значение (a 2 ) = 0,00 < 0,01 < 0,05.
Следовательно, коэффициенты a 1 и a 2 значимы при 1%-ном уровне, а тем более при 5%-ном уровне значимости. Нижние и верхние 95% границы доверительного интервала имеют одинаковые знаки, следовательно, коэффициенты a 1 и a 2 значимы.
Определение объясняющей переменной, от которой
Может зависеть дисперсия случайных возмущений.
Проверка выполнения условия гомоскедастичности
Остатков по тесту Гольдфельда–Квандта
При проверке предпосылки МНК о гомоскедастичности остатков в модели множественной регрессии следует вначале определить, по отношению к какому из факторов дисперсия остатков более всего нарушена. Это можно сделать в результате визуального исследования графиков остатков, построенных по каждому из факторов, включенных в модель. Та из объясняющих переменных, от которой больше зависит дисперсия случайных возмущений, и будет упорядочена по возрастанию фактических значений при проверке теста Гольдфельда–Квандта. Графики легко получить в отчете, который формируется в результате использования инструмента Регрессия в пакете Анализ данных).


Графики остатков по каждому из факторов двухфакторной модели
Из представленных графиков видно, что дисперсия остатков более всего нарушена по отношению к фактору Краткосрочная дебиторская задолженность.
Проверим наличие гомоскедастичности в остатках двухфакторной модели на основе теста Гольдфельда–Квандта.
Уберем из середины упорядоченной совокупности С = 1/4 · n = 1/4 · 50 = 12,5 (12) значения. В результате получим две совокупности соответственно с малыми и большими значениями Х4.
Для каждой совокупности выполним расчеты:
Упорядочим переменные Y и X2 по возрастанию фактора Х4 (в Excel для этого можно использовать команду Данные – Сортировка по возрастанию Х4):
|
Данные, отсортированные по возрастанию X4: |
||
|
Сумма |
111234876536,511 |
||||
|
966570797682,068 |
|||||
|
455748832843,413 |
|||||
|
232578961097,877 |
|||||
|
834043911651,192 |
|||||
|
193722998259,505 |
|||||
|
1246409153509,290 |
|||||
|
31419681912489,100 |
|||||
|
2172804245053,280 |
|||||
|
768665257272,099 |
|||||
|
2732445494273,330 |
|||||
|
163253156450,331 |
|||||
|
18379855056009,900 |
|||||
|
10336693841766,000 |
|||||
|
Сумма |
69977593738424,600 |
Уравнения для совокупностей
Y = -27275,746 + 0,126X2 + 1,817 X4
Y = 61439,511 + 0,228X2 + 0,140X4
Результаты данной таблицы получены с помощью инструмента Регрессия поочередно к каждой из полученных совокупностей.
4. Найдем отношение полученных остаточных сумм квадратов
(в числителе должна быть большая сумма):
5. Вывод о наличии гомоскедастичности остатков делаем с помощью F-критерия Фишера с уровнем значимости α = 0,05 и двумя одинаковыми степенями свободы k1 = k2 = == 17
где р – число параметров уравнения регрессии:
Fтабл (0,05; 17; 17) = 9,28.
Так как Fтабл > R ,то подтверждается гомоскедастичность в остатках двухфакторной регрессии.
Итоговые тесты по эконометрике
1. Оценка значимости параметров уравнения регрессии осуществляется на основе:
А) t - критерия Стьюдента;
б) F -критерия Фишера – Снедекора;
в) средней квадратической ошибки;
г) средней ошибки аппроксимации.
2. Коэффициент регрессии в уравнении , характеризующем связь между объемом реализованной продукции (млн. руб.) и прибылью предприятий автомобильной промышленности за год (млн. руб.) означает, что при увеличении объема реализованной продукции на 1 млн. руб. прибыль увеличивается на:
г) 0,5млн. руб.;
в) 500тыс. руб.;
Г) 1,5 млн. руб.
3. Корреляционное отношение (индекс корреляции) измеряет степень тесноты связи между Х и Y :
а) только при нелинейной форме зависимости;
Б) при любой форме зависимости;
в) только при линейной зависимости.
4. По направлению связи бывают:
а) умеренные;
Б) прямые;
в) прямолинейные.
5. По
17 наблюдениям построено уравнение
регрессии: .
Для проверки значимости уравнения
вычислено
наблюдаемое
значение
t
- статистики: 3.9. Вывод:
.
Для проверки значимости уравнения
вычислено
наблюдаемое
значение
t
- статистики: 3.9. Вывод:
А) Уравнение значимо при a= 0,05;
б) Уравнение незначимо при a = 0,01;
в) Уравнение незначимо при a = 0,05.
6. Каковы последствия нарушения допущения МНК «математическое ожидание регрессионных остатков равно нулю»?
А) Смещенные оценки коэффициентов регрессии;
б) Эффективные, но несостоятельные оценки коэффициентов регрессии;
в) Неэффективные оценки коэффициентов регрессии;
г) Несостоятельные оценки коэффициентов регрессии.
7. Какое из следующих утверждений верно в случае гетероскедастичности остатков?
А) Выводы по t и F- статистикам являются ненадежными;
г) Оценки параметров уравнения регрессии являются смещенными.
8. На чем основан тест ранговой корреляции Спирмена?
А) На использовании t – статистики;
в) На использовании
 ;
;
9. На чем основан тест Уайта?
б) На использовании F– статистики;
В) На
использовании
 ;
;
г) На графическом анализе остатков.
10. Каким методом можно воспользоваться для устранения автокорреляции?
11. Как называется нарушение допущения о постоянстве дисперсии остатков?
а) Мультиколлинеарность;
б) Автокорреляция;
В) Гетероскедастичность;
г) Гомоскедастичность.
12. Фиктивные переменные вводятся в:
а) только в линейные модели;
б) только во множественную нелинейную регрессию;
в) только в нелинейные модели;
Г) как в линейные, так и в нелинейные модели, приводимые к линейному виду.
13. Если в матрице
парных коэффициентов корреляции
встречаются
 ,
то это свидетельствует:
,
то это свидетельствует:
А) О наличии мультиколлинеарности;
б) Об отсутствии мультиколлинеарности;
в) О наличии автокорреляции;
г) Об отсутствии гетероскедастичности.
14. С помощью какой меры невозможно избавиться от мультиколлинеарности?
а) Увеличение объема выборки;
Г) Преобразование случайной составляющей.
15. Если
 и ранг матрицы А меньше (К-1) то уравнение:
и ранг матрицы А меньше (К-1) то уравнение:
а) сверхиденцифицировано;
Б) неидентифицировано;
в) точно идентифицировано.
16.Уравнение регрессии имеет вид:
А)
 ;
;
б)
 ;
;
в)
 .
.
17.В чем состоит проблема идентификации модели?
А) получение однозначно определенных параметров модели, заданной системой одновременных уравнений;
б) выбор и реализация методов статистического оценивания неизвестных параметров модели по исходным статистическим данным;
в) проверка адекватности модели.
18. Какой метод применяется для оценивания параметров сверхиденцифицированного уравнения?
В) ДМНК, КМНК;
19. Если качественная переменная имеет k альтернативных значений, то при моделировании используются:
А) (k-1) фиктивная переменная;
б) kфиктивных переменных;
в) (k+1) фиктивная переменная.
20. Анализ тесноты и направления связей двух признаков осуществляется на основе:
А) парного коэффициента корреляции;
б) коэффициента детерминации;
в) множественного коэффициента корреляции.
21. В линейном
уравнении
 x
=
а
0
+a
1
х
коэффициент регрессии показывает:
x
=
а
0
+a
1
х
коэффициент регрессии показывает:
а) тесноту связи;
б) долю дисперсии "Y", зависимую от "X";
В) на сколько в среднем изменится "Y" при изменении "X" на одну единицу;
г) ошибку коэффициента корреляции.
22. Какой показатель используется для определения части вариации, обусловленной изменением величины изучаемого фактора?
а) коэффициент вариации;
б) коэффициент корреляции;
В) коэффициент детерминации;
г) коэффициент эластичности.
23. Коэффициент эластичности показывает:
А) на сколько % изменится значение y при изменении x на 1 %;
б) на сколько единиц своего измерения изменится значение yпри измененииxна 1 %;
в) на сколько % изменится значение yпри измененииxна ед. своего измерения.
24. Какие методы можно применить для обнаружения гетероскедастичности ?
А) Тест Голфелда-Квандта;
Б) Тест ранговой корреляции Спирмена;
в) Тест Дарбина- Уотсона.
25. На чем основан тест Голфельда -Квандта
а) На использовании t– статистики;
Б) На использовании F – статистики;
в) На использовании
 ;
;
г) На графическом анализе остатков.
26. С помощью каких методов нельзя устранить автокорреляцию остатков?
а) Обобщенным методом наименьших квадратов;
Б) Взвешенным методом наименьших квадратов;
В) Методом максимального правдоподобия;
Г) Двухшаговым методом наименьших квадратов.
27. Как называется нарушение допущения о независимости остатков?
а) Мультиколлинеарность;
Б) Автокорреляция;
в) Гетероскедастичность;
г) Гомоскедастичность.
28. Каким методом можно воспользоваться для устранения гетероскедастичности?
А) Обобщенным методом наименьших квадратов;
б) Взвешенным методом наименьших квадратов;
в) Методом максимального правдоподобия;
г) Двухшаговым методом наименьших квадратов.
30. Если по t -критерию большинство коэффициентов регрессии статистически значимы, а модель в целом по F - критерию незначима то это может свидетельствовать о:
а) Мультиколлинеарности;
Б) Об автокорреляции остатков;
в) О гетероскедастичности остатков;
г) Такой вариант невозможен.
31. Возможно ли с помощью преобразования переменных избавиться от мультиколлинеарности?
а) Эта мера эффективна только при увеличении объема выборки;
32. С помощью какого метода можно найти оценки параметра уравнения линейной регрессии:
А) методом наименьшего квадрата;
б) корреляционно-регрессионного анализа;
в) дисперсионного анализа.
33. Построено множественное линейное уравнение регрессии с фиктивными переменными. Для проверки значимости отдельных коэффициентов используется распределение:
а) Нормальное;
б) Стьюдента;
в) Пирсона;
г) Фишера-Снедекора.
34. Если
 и ранг матрицы А больше (К-1) то уравнение:
и ранг матрицы А больше (К-1) то уравнение:
А) сверхиденцифицировано;
б) неидентифицировано;
в) точно идентифицировано.
35. Для оценивания параметров точно идентифицируемой системы уравнений применяется:
а) ДМНК, КМНК;
б) ДМНК, МНК, КМНК;
36. Критерий Чоу основывается на применении:
А) F - статистики;
б) t - статистики;
в) критерии Дарбина –Уотсона.
37. Фиктивные переменные могут принимать значения:
г) любые значения.
39.
По 20 наблюдениям построено уравнение
регрессии:
 .
Для
проверки значимости уравнения вычислено
значение статистики:
4.2.
Выводы:
.
Для
проверки значимости уравнения вычислено
значение статистики:
4.2.
Выводы:
а) Уравнение значимо при a=0.05;
б) Уравнение незначимо при a=0.05;
в) Уравнение незначимо при a=0.01.
40. Какое из следующих утверждений не верно в случае гетероскедастичности остатков?
а) Выводы по tиF- статистикам являются ненадежными;
б) Гетероскедастичность проявляется через низкое значение статистики Дарбина-Уотсона;
в) При гетероскедастичности оценки остаются эффективными;
г) Оценки являются смещенными.
41. Тест Чоу основан на сравнении:
А) дисперсий;
б) коэффициентов детерминации;
в) математических ожиданий;
г) средних.
42.
Если в тесте Чоу
 то считается:
то считается:
А) что разбиение на подынтервалы целесообразно с точки зрения улучшения качества модели;
б) модель является статистически незначимой;
в) модель является статистически значимой;
г) что нет смысла разбивать выборку на части.
43. Фиктивные переменные являются переменными:
а) качественными;
б) случайными;
В) количественными;
г) логическими.
44. Какой из перечисленных методов не может быть применен для обнаружения автокорреляции?
а) Метод рядов;
б) критерий Дарбина-Уотсона;
в) тест ранговой корреляции Спирмена;
Г) тест Уайта.
45. Простейшая структурная форма модели имеет вид:
А)

б)

в)

г)
 .
.
46. С помощью каких мер возможно избавиться от мультиколлинеарности?
а) Увеличение объема выборки;
б) Исключения переменных высококоррелированных с остальными;
в) Изменение спецификации модели;
г) Преобразование случайной составляющей.
47. Если
 и ранг матрицы А равен (К-1) то уравнение:
и ранг матрицы А равен (К-1) то уравнение:
а) сверхиденцифицировано;
б) неидентифицировано;
В) точно идентифицировано;
48. Модель считается идентифицированной, если:
а) среди уравнений модели есть хотя бы одно нормальное;
Б) каждое уравнение системы идентифицируемо;
в) среди уравнений модели есть хотя бы одно неидентифицированное;
г) среди уравнений модели есть хотя бы одно сверхидентифицированное.
49. Какой метод применяется для оценивания параметров неиденцифицированного уравнения?
а) ДМНК, КМНК;
б) ДМНК, МНК;
В) параметры такого уравнения нельзя оценить.
50. На стыке каких областей знаний возникла эконометрика:
А) экономическая теория; экономическая и математическая статистика;
б) экономическая теория, математическая статистика и теория вероятности;
в) экономическая и математическая статистика, теория вероятности.
51. В множественном линейном уравнении регрессии строятся доверительные интервалы для коэффициентов регрессии с помощью распределения:
а) Нормального;
Б) Стьюдента;
в) Пирсона;
г) Фишера-Снедекора.
52. По 16 наблюдениям построено парное линейное уравнение регрессии. Для проверки значимости коэффициента регрессии вычислено t на6л =2.5.
а) Коэффициент незначим при a=0.05;
б) Коэффициент значим при a=0.05;
в) Коэффициент значим при a=0.01.
53. Известно, что между величинами X и Y существует положительная связь. В каких пределах находится парный коэффициент корреляции?
а) от -1 до 0;
б) от 0 до 1;
В) от –1 до 1.
54. Множественный коэффициент корреляции равен 0.9. Какой процент дисперсии результативного признака объясняется влиянием всех факторных признаков?
55. Какой из перечисленных методов не может быть применен для обнаружения гетероскедастичности ?
А) Тест Голфелда-Квандта;
б) Тест ранговой корреляции Спирмена;
в) метод рядов.
56. Приведенная форма модели представляет собой:
а) систему нелинейных функций экзогенных переменных от эндогенных;
Б) систему линейных функций эндогенных переменных от экзогенных;
в) систему линейных функций экзогенных переменных от эндогенных;
г) систему нормальных уравнений.
57. В каких пределах меняется частный коэффициент корреляции вычисленный по рекуретным формулам?
а) от
-
 до +
до + ;
;
б) от 0 до 1;
в) от
0 до +
 ;
;
Г) от –1 до +1.
58. В каких пределах меняется частный коэффициент корреляции вычисленный через коэффициент детерминации?
а) от
-
 до +
до + ;
;
Б) от 0 до 1;
в) от
0 до +
 ;
;
г) от –1 до +1.
59. Экзогенные переменные:
а) зависимые переменные;
Б) независимые переменные;
61. При добавлении в уравнение регрессии еще одного объясняющего фактора множественный коэффициент корреляции:
а) уменьшится;
б) возрастет;
в) сохранит свое значение.
62. Построено гиперболическое уравнение регрессии: Y = a + b / X . Для проверки значимости уравнения используется распределение:
а) Нормальное;
Б) Стьюдента;
в) Пирсона;
г) Фишера-Снедекора.
63. Для каких видов систем параметры отдельных эконометрических уравнений могут быть найдены с помощью традиционного метода наименьших квадратов?
а) система нормальных уравнений;
Б) система независимых уравнений;
В) система рекурсивных уравнений;
Г) система взаимозависимых уравнений.
64. Эндогенные переменные:
А) зависимые переменные;
б) независимые переменные;
в) датированные предыдущими моментами времени.
65. В каких пределах меняется коэффициент детерминации?
а) от
0 до + ;
;
б) от
- до +
до + ;
;
В) от 0 до +1;
г) от -l до +1.
66. Построено множественное линейное уравнение регрессии. Для проверки значимости отдельных коэффициентов используется распределение:
а) Нормальное;
б) Стьюдента;
в) Пирсона;
Г) Фишера-Снедекора.
67. При добавлении в уравнение регрессии еще одного объясняющего фактора коэффициент детерминации:
а) уменьшится;
Б) возрастет;
в) сохранит свое значение;
г) не уменьшится.
68. Суть метода наименьших квадратов заключается в том, что:
А) оценка определяется из условия минимизации суммы квадратов отклонений выборочных данных от определяемой оценки;
б) оценка определяется из условия минимизации суммы отклонений выборочных данных от определяемой оценки;
в) оценка определяется из условия минимизации суммы квадратов отклонений выборочной средней от выборочной дисперсии.
69. К какому классу нелинейных регрессий относится парабола:
73. К какому классу нелинейных регрессий относится экспоненциальная кривая:
74. К какому классу
нелинейных регрессий относится функция
вида ŷ :
:
А) регрессии, нелинейные относительно включенных в анализ переменных, но линейных по оцениваемым параметрам;
б) нелинейные регрессии по оцениваемым параметрам.
78. К какому классу
нелинейных регрессий относится функция
вида ŷ
 :
:
а) регрессии, нелинейные относительно включенных в анализ переменных, но линейных по оцениваемым параметрам;
Б) нелинейные регрессии по оцениваемым параметрам.
79.
В уравнении регрессии в форме гиперболы
ŷ
 если величина
b
>0
,
то:
если величина
b
>0
,
то:
А) при увеличении факторного признака х значения результативного признака у замедленно уменьшаются, и при х→∞ средняя величина у будет равна а;
б)
то значение результативного признака
у
возрастает с замедленным ростом при
увеличении факторного признака х
,
и при х→∞

81. Коэффициент
эластичности определяется по формуле

А) Линейной функции;
б) Параболы;
в) Гиперболы;
г) Показательной кривой;
д) Степенной.
82. Коэффициент
эластичности определяется по формуле
 для модели регрессии в форме:
для модели регрессии в форме:
а) Линейной функции;
Б) Параболы;
в) Гиперболы;
г) Показательной кривой;
д) Степенной.
86. Уравнение
 называется:
называется:
А) линейным трендом;
б) параболическим трендом;
в) гиперболическим трендом;
г) экспоненциальным трендом.
89. Уравнение
 называется:
называется:
а) линейным трендом;
б) параболическим трендом;
в) гиперболическим трендом;
Г) экспоненциальным трендом.
90. Система виды
 называется:
называется:
А) системой независимых уравнений;
б) системой рекурсивных уравнений;
в) системой взаимозависимых (совместных, одновременных) уравнений.
93. Эконометрику можно определить как:
А) это самостоятельная научная дисциплина, объединяющая совокупность теоретических результатов, приемов, методов и моделей, предназначенных для того, чтобы на базе экономической теории, экономической статистики и математико-статистического инструментария придавать конкретное количественное выражение общим (качественным) закономерностям, обусловленным экономической теорией;
Б) наука об экономических измерениях;
В) статистический анализ экономических данных.
94. К задачам эконометрики можно отнести:
А) прогноз экономических и социально-экономических показателей, характеризующих состояние и развитие анализируемой системы;
Б) имитация возможных сценариев социально-экономического развития системы для выявления того, как планируемые изменения тех или иных поддающихся управлению параметров скажутся на выходных характеристиках;
в) проверка гипотез по статистическим данным.
95. По характеру различают связи:
А) функциональные и корреляционные;
б) функциональные, криволинейные и прямолинейные;
в) корреляционные и обратные;
г) статистические и прямые.
96. При прямой связи с увеличением факторного признака:
а) результативный признак уменьшается;
б) результативный признак не изменяется;
В) результативный признак увеличивается.
97. Какие методы используются для выявления наличия, характера и направления связи в статистике?
а) средних величин;
Б) сравнения параллельных рядов;
В) метод аналитической группировки;
г) относительных величин;
Д) графический метод.
98. Какой метод используется для выявления формы воздействия одних факторов на другие?
а) корреляционный анализ;
Б) регрессионный анализ;
в) индексный анализ;
г) дисперсионный анализ.
99. Какой метод используется для количественной оценки силы воздействия одних факторов на другие:
А) корреляционный анализ;
б) регрессионный анализ;
в) метод средних величин;
г) дисперсионный анализ.
100. Какие показатели по своей величине существуют в пределах от минус до плюс единицы:
а) коэффициент детерминации;
б) корреляционной отношение;
В) линейный коэффициент корреляции.
101. Коэффициент регрессии при однофакторной модели показывает:
А) на сколько единиц изменяется функция при изменении аргумента на одну единицу;
б) на сколько процентов изменяется функция на одну единицу изменения аргумента.
102. Коэффициент эластичности показывает:
а) на сколько процентов изменяется функция с изменением аргумента на одну единицу своего измерения;
Б) на сколько процентов изменяется функция с изменением аргумента на 1%;
в) на сколько единиц своего измерения изменяется функция с изменением аргумента на 1%.
105. Величина индекса корреляции, равная 0,087, свидетельствует:
А) о слабой их зависимости;
б) о сильной взаимосвязи;
в) об ошибках в вычислениях.
107. Величина парного коэффициента корреляции, равная 1,12, свидетельствует:
а) о слабой их зависимости;
б) о сильной взаимосвязи;
В) об ошибках в вычислениях.
109. Какие из приведенных чисел могут быть значениями парного коэффициента корреляции:
111. Какие из приведенных чисел могут быть значениями множественного коэффициента корреляции:
115. Отметьте правильную форму линейного уравнения регрессии:
а) ŷ
 ;
;
б) ŷ
 ;
;
в) ŷ
 ;
;
Г) ŷ .
.
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, коэффициент регрессии равен нулю, то есть b=0, и, следовательно, фактор х не оказывает влияния на результат у. Непосредственному расчету F-критерия предшествует анализ дисперсии. Центральное место в нем занимает разложение общей суммы квадратов отклонений переменной у от среднего значения у на две части - «объясненную» и «необъясненную» (приложение 2).
Общая сумма квадратов отклонений индивидуальных значений результативного признака у от среднего значения у вызвана влиянием множества причин. Условно всю совокупность причин можно разделить на две группы:
- · изучаемый фактор х
- · прочие факторы
Если фактор не оказывает влияния на результат, то линия регрессии на графике параллельна оси охи у = y. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной. Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объясненная регрессией, совпадает с общей суммой квадратов.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс как обусловленный влиянием фактора х, то есть регрессией у по х, так и вызванный действием прочих величин (необъясненная вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на объясненную вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное влияние на результат у. Это равносильно тому, что коэффициент детерминации r 2 xy будет приближаться к единице.
Любая сумма квадратов отклонений связана с числом степеней свободы (df - degrees of freedom), то есть с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из n возможных [(y 1 -y), (y 2 -y),…,(y n -y)] требуется для образования данной суммы квадратов. Так, для общей суммы квадратов?(y-y) 2 требуется (n-1) независимых отклонений.
При расчете объясненной или факторной суммы квадратов?(y x -y) 2 используются теоретические (расчетные) значения результативного признака y x , найденные по линии регрессии: y x =а+b*x.
В линейной регрессии сумма квадратов отклонений, обусловленных линейной регрессией, составит: ?(y x -y) 2 =b 2 *?(x -x) 2 .
Поскольку при заданном объеме наблюдений по х и у факторная сумма квадратов при линейной регрессии зависит только от одной константы коэффициента регрессии b, то данная сумма квадратов имеет одну степень свободы. К тому же выводу придем, если рассмотрим содержательную сторону расчетного значения признака у, то есть y x . Величина y x определяется по уравнению линейной регрессии: y x =а+b*x. Параметр а можно определить как: a=y-b*x. Подставив выражение параметра а в линейную модель получим:
y x = y-b*x+b*x= y-b*(х-х).
Отсюда видно, что при заданном наборе переменных у и х расчетное значение y x является в линейной регрессии функцией только одного параметра - коэффициента регрессии. Соответственно и факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет n-2. Число степеней свободы для общей суммы квадратов определяется числом единиц, и поскольку используется средняя вычисленная по данным выборки, то теряем одну степень свободы, то есть df общ = n-1.
Итак, имеется два равенства:
?(у-у) 2 =?(y x -у) 2 +?(у- y x) 2 ,
Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или, что то же самое, дисперсию на одну степень свободы D.
D общ =?(у-у) 2 /(n-1);
D факт =?(y x -у) 2 /1;
D ост =?(у- y x) 2 /(n-1).
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-отношения (F-критерия):
F= D факт / D ост, где
F - критерий для проверки нулевой гипотезы Н 0: D факт =D ост.
Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для Н 0 необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз.
Английским статистиком Снедекором разработаны таблицы критических значений F-отношений при разных уровнях существенности нулевой гипотезы и различимом числе степеней свободы.
Табличное значение F-критерия - это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы.
Вычисленное значение F-отношения признается достоверным (отличным от единицы), если оно больше табличного.
В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи: F факт >F табл. Н 0 отклоняется.
Если же величина окажется меньше табличной F факт Оценку качества модели дает коэффициент детерминации. Коэффициент детерминации (R
2) -- это квадрат множественного коэффициента корреляции. Он показывает, какая доля дисперсии результативного признака объясняется влиянием независимых переменных. Формула для вычисления коэффициента детерминации: y
i
-- выборочные данные, а f
i
-- соответствующие им значения модели. Также это квадрат корреляции Пирсона между двумя переменными. Он выражает количество дисперсии, общей между двумя переменными. Коэффициент принимает значения из интервала . Чем ближе значение к 1 тем ближе модель к эмпирическим наблюдениям. В случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции, то есть R
2 = r
2 . Иногда показателям тесноты связи можно дать качественную оценку (шкала Чеддока) (приложение 3). Функциональная связь возникает при значении равном 1, а отсутствие связи -- 0. При значениях показателей тесноты связи меньше 0,7 величина коэффициента детерминации всегда будет ниже 50 %. Это означает, что на долю вариации факторных признаков приходится меньшая часть по сравнению с остальными неучтенными в модели факторами, влияющими на изменение результативного показателя. Построенные при таких условиях регрессионные модели имеют низкое практическое значение. После того как уравнение регрессии построено и с помощью коэффициента детерминации оценена его точность, остается открытым вопрос за счет чего достигнута эта точность и соответственно можно ли этому уравнению доверять. Дело в том, что уравнение регрессии строилось не по генеральной совокупности, которая неизвестна, а по выборке из нее. Точки из генеральной совокупности попадают в выборку случайным образом, по этому в соответствии с теорией вероятности среди прочих случаев возможен вариант, когда выборка из “широкой” генеральной совокупности окажется “узкой” (рис. 15). Рис. 15. Возможный вариант попадания точек в выборку из генеральной совокупности. В этом случае: а) уравнение регрессии, построенное по выборке, может значительно отличаться от уравнения регрессии для генеральной совокупности, что приведет к ошибкам прогноза; б) коэффициент детерминации и другие характеристики точности окажутся неоправданно высокими и будут вводить в заблуждение о прогнозных качествах уравнения. В предельном случае не исключен вариант, когда из генеральной совокупности представляющей собой облако с главной осью параллельной горизонтальной оси (отсутствует связь между переменными) за счет случайного отбора будет получена выборка, главная ось которой окажется наклоненной к оси. Таким образом, попытки прогнозировать очередные значения генеральной совокупности опираясь на данные выборки из нее чреваты не только ошибками в оценке силы и направления связи между зависимой и независимой переменными, но и опасностью найти связь между переменными там, где на самом деле ее нет. В условиях отсутствия информации обо всех точках генеральной совокупности единственный способ уменьшить ошибки в первом случае заключается в использовании при оценке коэффициентов уравнения регрессии метода, обеспечивающего их несмещенность и эффективность. А вероятность наступления второго случая может быть значительно снижена благодаря тому, что априори известно одно свойство генеральной совокупности с двумя независимыми друг от друга переменными – в ней отсутствует именно эта связь. Достигается это снижение за счет проверки статистической значимости полученного уравнения регрессии. Один из наиболее часто используемых вариантов проверки заключается в следующем. Для полученного уравнения регрессии определяется -статистика - характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. Уравнение для определения -статистики в случае многомерной регрессии имеет вид: где: - объясненная дисперсия - часть дисперсии зависимой переменной Y которая объяснена уравнением регрессии; Остаточная дисперсия - часть дисперсии зависимой переменной Y которая не объяснена уравнением регрессии, ее наличие является следствием действия случайной составляющей; Число точек в выборке; Число переменных в уравнении регрессии. Как видно из приведенной формулы, дисперсии определяются как частное от деления соответствующей суммы квадратов на число степеней свободы. Число степеней свободы это минимально необходимое число значений зависимой переменной, которых достаточно для получения искомой характеристики выборки и которые могут свободно варьироваться с учетом того, что для этой выборки известны все другие величины, используемые для расчета искомой характеристики. Для получения остаточной дисперсии необходимы коэффициенты уравнения регрессии. В случае парной линейной регрессии коэффициентов два, по этому в соответствии с формулой (принимая ) число степеней свободы равно . Имеется в виду, что для определения остаточной дисперсии достаточно знать коэффициенты уравнения регрессии и только значений зависимой переменной из выборки. Оставшиеся два значения могут быть вычислены на основании этих данных, а значит, не являются свободно варьируемыми. Для вычисления объясненной дисперсии значений зависимой переменной вообще не требуются, так как ее можно вычислить, зная коэффициенты регрессии при независимых переменных и дисперсию независимой переменной. Для того чтобы убедиться в этом, достаточно вспомнить приводившееся ранее выражение В результате -критерий для уравнения парной линейной регрессии определяется по формуле: В теории вероятности доказано, что -критерий уравнения регрессии, полученного для выборки из генеральной совокупности у которой отсутствует связь между зависимой и независимой переменной имеет распределение Фишера, достаточно хорошо изученное. Благодаря этому для любого значения -критерия можно рассчитать вероятность его появления и наоборот, определить то значение -критерия которое он не сможет превысить с заданной вероятностью. Для осуществления статистической проверки значимости уравнения регрессии формулируется нулевая гипотеза об отсутствии связи между переменными (все коэффициенты при переменных равны нулю) и выбирается уровень значимости . Уровень значимости – это допустимая вероятность совершить ошибку первого рода – отвергнуть в результате проверки верную нулевую гипотезу. В рассматриваемом случае совершить ошибку первого рода означает признать по выборке наличие связи между переменными в генеральной совокупности, когда на самом деле ее там нет. Обычно уровень значимости принимается равным 5% или 1%. Чем выше уровень значимости (чем меньше ), тем выше уровень надежности теста, равный , т.е. тем больше шанс избежать ошибки признания по выборке наличия связи у генеральной совокупности на самом деле несвязанных между собой переменных. Но с ростом уровня значимости возрастает опасность совершения ошибки второго рода – отвергнуть верную нулевую гипотезу, т.е. не заметить по выборке имеющуюся на самом деле связь переменных в генеральной совокупности. По этому, в зависимости от того, какая ошибка имеет большие негативные последствия, выбирают тот или иной уровень значимости. Для выбранного уровня значимости по распределению Фишера определяется табличное значение вероятность превышения, которого в выборке мощностью , полученной из генеральной совокупности без связи между переменными, не превышает уровня значимости. сравнивается с фактическим значением критерия для регрессионного уравнения . Если выполняется условие , то ошибочное обнаружение связи со значением -критерия равным или большим по выборке из генеральной совокупности с несвязанными между собой переменными будет происходить с вероятностью меньшей чем уровень значимости. В соответствии с правилом “очень редких событий не бывает”, приходим к выводу, что установленная по выборке связь между переменными имеется и в генеральной совокупности, из которой она получена. Если же оказывается , то уравнение регрессии статистически не значимо. Иными словами существует реальная вероятность того, что по выборке установлена не существующая в реальности связь между переменными. К уравнению, не выдержавшему проверку на статистическую значимость, относятся так же, как и к лекарству с истекшим сроком годнос- Ти – такие лекарства не обязательно испорчены, но раз нет уверенности в их качестве, то их предпочитают не использовать. Это правило не уберегает от всех ошибок, но позволяет избежать наиболее грубых, что тоже достаточно важно. Второй вариант проверки, более удобный в случае использования электронных таблиц, это сопоставление вероятности появления полученного значения -критерия с уровнем значимости. Если эта вероятность оказывается ниже уровня значимости , значит уравнение статистически значимо, в противном случае нет. После того как выполнена проверка статистической значимости регрессионного уравнения в целом полезно, особенно для многомерных зависимостей осуществить проверку на статистическую значимость полученных коэффициентов регрессии. Идеология проверки такая же как и при проверке уравнения в целом но в качестве критерия используется -критерий Стьюдента, определяемый по формулам: где: , - значения критерия Стьюдента для коэффициентов и соответственно; Число точек в выборке; Число переменных в выборке, для парной линейной регрессии . Полученные фактические значения критерия Стьюдента сравниваются с табличными значениями Для переменных, чьи коэффициенты оказались статистически не значимы, велика вероятность того, что их влияние на зависимую переменную в генеральной совокупности вообще отсутствует. По этому или необходимо увеличить число точек в выборке, тогда возможно коэффициент станет статистически значимым и заодно уточнится его значение, или в качестве независимых переменных найти другие, более тесно связанные с зависимой переменной. Точность прогнозирования при этом в обоих случаях возрастет. В качестве экспрессного метода оценки значимости коэффициентов уравнения регрессии можно применять следующее правило – если критерий Стьюдента больше 3, то такой коэффициент, как правило, оказывается статистически значим. А вообще считается, что для получения статистически значимых уравнений регрессии необходимо, чтобы выполнялось условие . Стандартная ошибка прогнозирования по полученному уравнению регрессии неизвестного значения при известном оценивают по формуле: Таким образом прогноз с доверительной вероятностью 68% может быть представлен в виде: В случае если требуется иная доверительная вероятность , то для уровня значимости необходимо найти критерий Стьюдента и доверительный интервал для прогноза с уровнем надежности будет равен Прогнозирование многомерных и нелинейных зависимостей В случае если прогнозируемая величина зависит от нескольких независимых переменных, то в этом случае имеется многомерная регрессия вида: где: - коэффициенты регрессии, описывающие влияние переменных на прогнозируемую величину. Методика определения коэффициентов регрессии не отличается от парной линейной регрессии, особенно при использовании электронной таблицы, так как там применяется одна и та же функция и для парной и для многомерной линейной регрессии. При этом желательно чтобы между независимыми переменными отсутствовали взаимосвязи, т.е. изменение одной переменной не сказывалось на значениях других переменных. Но это требование не является обязательным, важно чтобы между переменными отсутствовали функциональные линейные зависимости. Описанные выше процедуры проверки статистической значимости полученного уравнения регрессии и его отдельных коэффициентов, оценка точности прогнозирования остается такой же как и для случая парной линейной регрессии. В тоже время применение многомерных регрессий вместо парной обычно позволяет при надлежащем выборе переменных существенно повысить точность описания поведения зависимой переменной, а значит и точность прогнозирования. Кроме этого уравнения многомерной линейной регрессии позволяют описать и нелинейную зависимость прогнозируемой величины от независимых переменных. Процедура приведения нелинейного уравнения к линейному виду называется линеаризацией. В частности если эта зависимость описывается полиномом степени отличной от 1, то, осуществив замену переменных со степенями отличными от единицы на новые переменные в первой степени, получаем задачу многомерной линейной регрессии вместо нелинейной. Так, например если влияние независимой переменной описывается параболой вида то замена позволяет преобразовать нелинейную задачу к многомерной линейной вида Так же легко могут быть преобразованы нелинейные задачи у которых нелинейность возникает вследствие того, что прогнозируемая величина зависит от произведения независимых переменных. Для учета такого влияния необходимо ввести новую переменную равную этому произведению. В тех случаях, когда нелинейность описывается более сложными зависимостями, линеаризация возможна за счет преобразования координат. Для этого рассчитываются значения превращается в линейную вида Полученные коэффициенты регрессии для преобразованного уравнения остаются несмещенными и эффективными, но проверка статистической значимости уравнения и коэффициентов невозможна Проверка обоснованности применения метода наименьших квадратов Применение метода наименьших квадратов обеспечивает эффективность и несмещенность оценок коэффициентов уравнения регрессии при соблюдении следующих условий (условий Гауса-Маркова): 3. значения не зависят друг от друга 4. значения не зависят от независимых переменных Наиболее просто можно проверить соблюдение этих условий путем построения графиков остатков в зависимости от , затем от независимой (независимых) переменных. Если точки на этих графиках расположены в коридоре расположенном симметрично оси абсцисс и в расположении точек не просматриваются закономерности, то условия Гауса-Маркова выполнены и возможности повысить точность уравнения регрессии отсутствуют. Если это не так, то существует возможность существенно повысить точность уравнения и для этого необходимо обратиться к специальной литературе.
![]() . По этому число степеней свободы для остаточной дисперсии равно числу независимых переменных в уравнении регрессии (для парной линейной регрессии ).
. По этому число степеней свободы для остаточной дисперсии равно числу независимых переменных в уравнении регрессии (для парной линейной регрессии ). .
. и
и 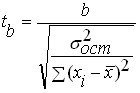
 - остаточная дисперсия уравнения регрессии;
- остаточная дисперсия уравнения регрессии;![]() , полученными из распределения Стьюдента. Если оказывается, что , то соответствующий коэффициент статистически значим, в противном случае нет. Второй вариант проверки статистической значимости коэффициентов – определить вероятность появления критерия Стьюдента и сравнить с уровнем значимости .
, полученными из распределения Стьюдента. Если оказывается, что , то соответствующий коэффициент статистически значим, в противном случае нет. Второй вариант проверки статистической значимости коэффициентов – определить вероятность появления критерия Стьюдента и сравнить с уровнем значимости .
![]() .
.![]()
![]()
![]() и строятся графики зависимости исходных точек в различных комбинациях преобразованных переменных. Та комбинация преобразованных координат или преобразованных и не преобразованных координат, в которой зависимость ближе всего к прямой линии подсказывает замену переменных которая приведет к преобразованию нелинейной зависимости к линейному виду. Например, нелинейная зависимость вида
и строятся графики зависимости исходных точек в различных комбинациях преобразованных переменных. Та комбинация преобразованных координат или преобразованных и не преобразованных координат, в которой зависимость ближе всего к прямой линии подсказывает замену переменных которая приведет к преобразованию нелинейной зависимости к линейному виду. Например, нелинейная зависимость вида