
Normalisering (standardisering) og dataforening. Arbejdsrationeringsmetoder i virksomheder og institutioner - lovgivning, mål og organisation
Hvorfor er det nødvendigt med normalisering af indikatoren
Normalt forsøger de at beskrive manifestationen af en eller anden kvalitet efter antal. Oftest dannes et sådant tal x som summen af punkter. Hvor legitimt dette er, er et andet spørgsmål. Vi antager, at et sådant tal x er modtaget og meningsfuldt.
Normalt skifter x fra en eller anden minimumsværdi x min (hvilket afspejler manglen på kvalitet) til en eller anden maksimal værdi x max (ekstrem grad af manifestation, tilstedeværelse, sværhedsgrad, ...).
At få det løser problemet med at sammenligne to objekter, men kun for denne indikator. Imidlertid er tingene heller ikke særlig gode her. Vi skal altid huske, i hvilket omfang indikatoren ændres. Og disse intervaller er meget forskellige ... Desuden at estimere, hvor tæt en bestemt værdi er på områdets kanter eller i midten. Generelt rent besvær.
Hvis vi taler om en sammenligning af to forskellige indikatorer, er det et spørgsmål om sømme. Naturligvis kan man ikke sammenligne kvaliteter direkte. Til dette skal de sammenlignede tal være dimensionsløse. Men det er indikatoren, der normalt fortolkes som alvorlighed noget kvalitet. Og du kan sammenligne det !!! Men til dette bør de reduceres til en skala, så begyndelsen og enderne af de to skalaer falder sammen.
Men hvorfor kun disse to? Lad os udføre denne transformation for alle målinger! Det kaldes normalisering(ikke at forveksle med normalisering!). Derefter kan vi sammenligne forskellige indikatorer opnået ved forskellige metoder.
2. Typer af indikatorer
Med alle de forskellige numeriske egenskaber ved objekter (eller respondenter) kan der skelnes mellem to brede klasser fra dem:
- unipolar kun udtrykker graden af tilstedeværelse (intensitet, sværhedsgrad, ...) af en bestemt kvalitet;
- bipolar, der afspejler ikke kun graden af tilgængelighed af kvalitet, men også dens "retning".
3. Normalisering af den unipolære eksponent
Det er længe blevet fastslået inden for videnskaben, at værdierne normaliseres til området fra 0 til 1.
Til dette skal transformationsfunktionen y = f (x) have følgende egenskaber:
y (x min) = 0; y (x max) = 1; dy / dx> 0 (1)
Enhver funktion med sådanne egenskaber kan bruges. bruges til normalisering. For eksempel, hvis x max, så kan du vælge funktionen
![]()
Det er let at se, at ved at vælge den passende funktion er det muligt at tage højde for forskellige effekter af fordrejning af estimater. For eksempel respondentens tilbøjelighed til ekstreme skøn. I dette tilfælde kan det være nødvendigt at ansøge om forskellige respondenter og forskellige transformationsfunktioner under hensyntagen til egenskaberne ved deres personlighed, status osv. Omtrentlige grafer over sådanne funktioner er vist i fig. en.
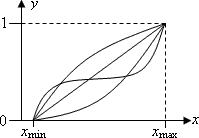
Fig. en. Normaliseringsfunktionsdiagrammer
Den mest anvendte lineære transformation er:
![]() (2)
(2)
Hvis vi antager, at en stigning i x både beskriver en stigning i sværhedsgraden af kvalitet A og et fald i graden af en anden kvalitet B, så kan det normaliserede mål for kvalitet B simpelthen være forskellen y´ = 1 - y. Sådanne er for eksempel de relaterede kvaliteter 'nærhed' og 'afstand'. Deres metrization afslører tidligere dårligt forstået, men ret klar komplementaritet og endda det modsatte.
4. Normalisering af det bipolære indeks
En sådan indikator er typisk en 'limning' af to gensidigt understøttende og antonyme unipolare kvaliteter A og B.
Ofte er B simpelthen negationen af A og omvendt. For eksempel er skalaerne for den semantiske differentiering bygget på dette princip. Parene til en sådan differentiering skal dog kontrolleres i forhold til ordbogen for antonymer (for eksempel er to antonymer for ordet "munter" - "trist" og "dyster" - slet ikke synonymer).
Normalisering af den tilsvarende værdi forudsætter valget af “ positiv»Retning af y-aksen. Som sådan vilkårligt en af skalapolerne er valgt, hvis stigning i intensiteten taget som en stigning y. Den modsatte pol bliver automatisk " negativ". Vi understreger, at der ikke er nogen modalitet (aksiologisk vurdering) bag dette - kun de eksisterende semantiske stereotyper kan spille en rolle, men ikke mere.
Lad værdien x estimere ekspressionsgraden for begge kvaliteter (med den passende betegnelse, for eksempel 'Jeg elsker meget' eller 'Jeg hader lidt'). Normalisering kan udføres ved hjælp af en hvilken som helst funktion, der opfylder betingelserne (1). Især kan det være. og lineær transformation:
 (3)
(3)
Det er klart, at y [–1; +1].
Begge formler (2) og (3) beskriver en lineær transformation af formen y = k x + b. Derfor alle statistiske fund med hensyn til x og y helt match.
5. Funktioner i punktskalaer
Der er flere finesser, når du bruger en punktskala, der ofte overses:
- Nogle gange er der ingen svar på alle spørgsmål relateret til denne indikator. Årsagerne er forskellige - svaret er simpelthen ikke givet, der blev lavet en fejl ved indtastning af svaret eller kodning af det ... Kort sagt mangler der svar.
- Næsten altid svarer scoren blandt andet til antallet af svaret. Og den laveste score bliver 1.
- Jeg vil gerne bruge et svar med et andet antal graderinger til nogle spørgsmål. Men så skal hans bidrag tages i betragtning på en anden måde.
Når du normaliserer punktskalaen, skal du bare acceptere, at x = S, hvor S er summen af de scorede point for de modtagne svar (og ikke de stillede spørgsmål!). Følgelig er S min og S max det minimum og det maksimale antal point, der kan opnås med de modtagne svar.
Dette afsnit diskuterer en normaliseringsteknik, der er nyttig til løsning af praktiske problemer. For alle opgaver (undtagen for de enkleste) er det normalt mere praktisk at bruge de numeriske værdier for de givne parametre snarere end alfabetiske tegn. Efter at de numeriske værdier er indtastet i problemet, er det ønskeligt at præsentere udtrykkene i en sådan form, at tallene indtaster disse udtryk som tidskonstanter, det vil sige i form af forholdet mellem de søgte parametre i systemet, som har dimensionens tid. Det viser sig ofte, at de tidskonstanter, der bestemmer systemets dynamiske egenskaber, er store eller små sammenlignet med enhed. Hvis værdierne for tidskonstanterne adskiller sig meget fra enhed, tilrådes det at tage endnu et trin, nemlig at ændre tidsskalaen, så de største specificerede parametre har normaliserede værdier tæt på enhed. Dette giver lettere beregninger.
Det sker ofte, at det er mere praktisk at anvende normalisering på billedet snarere end selve tidsfunktionen. Således er det nødvendigt at vide, hvordan man for en given funktion bestemmer Fourier-billedet svarende til den normaliserede tid, idet man kender Fourier-billedet for den normale tid. Hvordan man gør dette bliver klart, hvis vi vender os til definitionen af Fourier-transformationen. Lad være Fourier-billedet af funktionen Per definition betyder dette, at

Lad være Fourier-billedet af funktionen i forhold til den normaliserede tid. Ifølge definitionen har vi

Typisk er den normaliserede tidsfunktion den samme som den sande tidsfunktion; i dette tilfælde specificeres skalaen for normaliseret tid i forhold til den sande. Lad forholdet mellem tidspunkterne have form
Her kan størrelsen have en hvilken som helst dimension, men normalt har den tidsdimensionen, og derefter vil begivenheden, der er knyttet til, være dimensionsløs. Symbolsk forhold mellem to funktioner
er skrevet som følger:
Efter udskiftning med i (2.5-1) opnår vi

Men ifølge (2.5-4) har vi det
![]()
Lad den normaliserede komplekse frekvens (1) være relateret til den eller de unormaliserede ved hjælp af forholdet
Baseret på (2.5-6 og 7) kan formel (2.5-5) omskrives som

Ifølge integralet på højre side er pr. Definition den normaliserede Fourier-transformation.
![]()
Således, hvis det er nødvendigt at finde et normaliseret billede baseret på et almindeligt billede, er det nødvendigt at bruge formlen
Baseret på den forrige kan vi sige: hvis tidsfunktionen i billedet erstattes af - og resultatet divideres med, får vi billedet af funktionen fra variablen. Originalen svarende til dette billede er en funktion Selvom dette resultatet blev opnået for Fourier-billedet, det forbliver også sandt for billedet ifølge Laplace. Det skal bemærkes, at ovenstående procedure til beregning af det normaliserede (svarende til den ændrede tidsskala) billede ikke kan anvendes til beregning af den normaliserede overføringsfunktion eller vægtfunktion. Overførselsfunktion
kan betragtes som forholdet mellem billederne af to tidsfunktioner, og derfor annulleres de faktorer, der vises som et resultat af normalisering i tælleren og nævneren. Formlen for den normaliserede overførselsfunktion opnås således blot ved at erstatte den med. Det er ikke nødvendigt at dele dette udtryk med en faktor.
Som et eksempel skal du overveje beregningen af det normaliserede billede for følgende tidsfunktion:
![]()
Denne funktion vises som
![]()
Anvendelse af formlen får vi

![]()
Beregning af den omvendte transformation med hensyn til, hvad vi opnår
Dette resultat kan naturligvis opnås direkte fra det næste spørgsmål, hvordan man beregner værdien af den integrerede kvadratiske fejl baseret på Parseval's sætning, idet man kender det normaliserede Fourier-billede af fejlen. Husk at Parsevals sætning skaber følgende ligestilling:

hvor I er funktionens integrerede kvadratiske værdi. I overensstemmelse med normaliseringsreglen bestemmes den af formlen
Indsamling af information og opnåelse af skøn over indikatorer
Indsamling af information kan ske på en række måder. Feltinterview er den mest populære metode. Inden du fortsætter med indsamlingen af oplysninger, er det imidlertid nødvendigt at bestemme publikum, på hvis mening det vil være muligt at stole på i processen med at oprette vurderingen. For det første skal interviewpersonerne være kvalificerede til at besvare spørgsmålene. For det andet skal deres vurdering være upartisk. Dette kan føre til en række uventede komplikationer. For eksempel, når man udarbejder en vurdering af universiteter, interviewes studerende eller kandidater fra disse organisationer ofte. Denne tilgang kan dog være forkert af følgende grunde. For det første er en person ikke altid klar til at indrømme, at hans valg var forkert, og at andre universiteter er bedre end den, han kom ind på eller tog eksamen fra. For det andet er studerende sjældent i stand til at foretage en sammenlignende vurdering af universiteterne, fordi de kun er uddannet i en, sjældent i to institutioner.
En anden måde at få indledende data på er at analysere sekundær information (for eksempel data fra Goskomstat). Det største problem, som forskeren står over for i dette tilfælde, er ufuldstændigheden af oplysningerne. Hvis vurderingen er baseret på mediedataene, er det meget sandsynligt, at det ikke vurderer virksomhederne selv, men deres PR-afdelingers arbejde.
En rimelig tilgang synes at være brugen af resumeoplysninger om objektets karakteristika, der er offentliggjort i forskellige tidsskrifter (magasiner "Expert", "Kommersant" osv.).
Standardisering af kriterier forstås som at bringe de lokale kriterier for optimalitet til en enkelt dimensionsløs form.
Som metoder til standardisering i hjemmearbejde anvendes den mest almindelige metode til at bringe kriterierne til en dimensionsløs form - lineær transformation.
f 1 fortrinsvis den maksimale værdi, derefter formlen for overgangen fra indikatorens unormaliserede værdi x 1 til den normaliserede har formen:
 ,
,
Hvor f 1 min. Og f 1 ma x- henholdsvis minimum (værste) og maksimale (bedste) værdi af indikatoren på sættet med tilladte alternativer.
Hvis der er en indikator f 1 er fortrinsvis minimumsværdien, så overgangsformlen skrives som:
 .
.
Normalisering (standardisering) og dataforening
Normaliserede (standardiserede) data. I en række problemer er det bekvemt eller endda nødvendigt at gå fra de indledende observationer, hvor i = 1, 2, ... n, til normaliserede (standardiserede), som vi vil introducere nedenfor. Lad der være data på baggrund af hvilke vi har fået
![]()
Normaliseret (standardiseret) kalde data i formularen
- dimensionsløse mængder, der opfylder betingelsen
Lad os vise, at det aritmetiske gennemsnit af de normaliserede data er lig med nul:
og variansen er lig med en:
Desuden, hvis den normaliserede værdi er større end nul (r *> 0), så er den observerede værdi større end gennemsnittet (x; > x). Hvis x " < 0, то x,< х.
Standardisering (normalisering) af data er en nødvendig indledende fase af datatransformation, når man bruger mange multidimensionelle statistiske metoder - reducerer dimensionen af attributområdet (faktor, komponentanalyse, se kapitel 5), klassificering af objekter (klyngeanalyse, se kapitel 6), osv., især hvis variablerne måles på skalaer, der adskiller sig markant i størrelse (mikron enheder - milliarder enheder).
På grund af udbredelsen og efterspørgslen i statistiske pakker placeres standardiseringsproceduren (standardisering) normalt i menuen (figur 1.31).

Fig. 1.31. Henter datanormaliseringsproceduren (standardisering) i pakkemenuenSTA TISTICA (StatSoft)
Dataforening (samlet skala). Når der konstrueres integrerede generaliserende indikatorer, opstår der ofte en situation, når datarationering ikke giver det ønskede resultat. For eksempel er vi nødt til at konstruere en integreret indikator for livskvaliteten i et land (region), som inkluderer tre indledende variabler - forventet levealder, spædbarnsdødelighed og ledighed. På samme tid, selv ved at oversætte disse tre indikatorer til en enkelt skala (for eksempel med værdier fra 0 til 1 eller fra 0 til N), vi vil have en konflikt i fortolkningen af variablerne i den næste plan.
Den første variabel - forventet levetid - er kendetegnet ved, at jo højere værdier det tager, jo højere livskvalitet i landet (regionen). Tværtimod nedsætter den anden variabel - spædbarnsdødelighed - livskvaliteten med stigende værdier. Den tredje variabel - arbejdsløshed - har sit eget bestemte optimale (ca. 5% sikrer den normale funktion og udvikling af økonomien). Og ved at kombinere alle tre funktioner i en integreret indikator, mangler vi tilstrækkelig fortolkning af den resulterende indikator. Jo højere det er, jo højere forventet levetid (bedre), højere spædbarnsdødelighed (værre), højere arbejdsløshed (uforståelig). For at løse sådanne problemer er der en måde i dataanalyse, der giver dig mulighed for at gøre dette - bringe alle de variabler, der er involveret i konstruktionen af den integrerede indikator, til en samlet skala.
Samlet skala- skalaen, der anvendes til konstruktionen af integrale indikatorer fra forskellige variabler, der tager værdier fra 0 til N og har et samlet fortolkningssystem: jo højere værdierne for variablen i den samlede skala, jo højere er værdien af integralen indikator. Hvornår N = vi får en skala fra 0 til 1.
Variabler af den første type - jo højere indikator, jo bedre (forventet levetid) - reduceres til en samlet skala som følger:
Hvor Xj - værdien af variablen til den i-observation; amin og ataks er henholdsvis de mindste og største observerede værdier for variablen.
Ifølge denne formel, hvis x t – amin, så er "= 0, og hvis ,, er passende, så x] = N, de der. jo større værdien af variablen a, jo højere (bedre) dens værdi i den samlede skala a *.
2. Variabler af den anden type - jo højere indikator, jo værre (spædbarnsdødelighed) - reduceres til en samlet skala som følger:
I henhold til denne formel, hvis a = am | 1), så x = N, og hvis a, - = a „dem, så er * * 0, dvs. jo større værdien af variablen a, jo lavere (dårligere) dens værdi i den samlede skala X /.
3. Variabler af den tredje type - indikatoren har en vis optimal aopt, denne værdi er den bedste, jo større afvigelse derfra, jo værre (ledigheden) - reduceres til en samlet skala som følger:
Ifølge denne formel, hvis x t = aopt, så x] = N. Hvis a, har den maksimalt mulige afvigelse otashp, så er a, "= 0. F.eks. Hvis (asax - a, pc) >> (aOMT-amin) og a, = atax, så er a" = 0. Jo mere værdien af variablen a afviger fra den optimale, jo lavere (værre) er værdien af a * i den samlede skala, og jo tættere værdien på a er, jo bedre.
- Ayvazyan S.A. Analyse af befolkningens kvalitet og livsstil // TsEMI RAN. M.: Nauka, 2012. (Økonomisk videnskab i det moderne Rusland).
- På samme sted.
Lad os illustrere vigtigheden af at bruge standarder ved hjælp af eksemplet på den velkendte metode til K. Thomas. Husk, at konklusionen om den dominerende adfærdsstrategi i en konfliktsituation i den er lavet på basis af numeriske data. Efter beregning af de samlede point for hver skala er det nemlig nødvendigt at identificere skalaen med den højeste score. Strategien svarende til skalaen fortolkes som dominerende i en konfliktsituation. Den beregnede statistik viser, at gennemsnitsværdierne for skalaoverslaget i absolutte tal er forskellige. De varierer hos mænd fra 5,25 point til 7,25 point og hos kvinder fra 3,71 til 7,65 point (se tabel 11).
Tab. 11. Primære statistikker over skalavurderinger af Thomas-metoden
|
Mænd (n = 56) |
Kvinder (n = 71) |
|||||||
|
Strategi | ||||||||
|
Selvhævdelse | ||||||||
|
Samarbejde | ||||||||
|
Kompromis | ||||||||
|
Undgåelse | ||||||||
|
Overholdelse | ||||||||
Bemærk.
Gennemsnit - gennemsnitlige værdier
950% og + 95,0% er konfidensintervallerne for middelværdierne;
De største gennemsnitsværdier er fremhævet.
Således, hvis du ikke tager højde for de normative data, der er opnået på den russiske prøve (eller verificeret i den russiske prøve), kan man i fortolkningen af resultaterne komme til de forkerte konklusioner. Faktisk har både mænd og kvinder en præference for undgåelsesstrategier. Manualen til metodologien siger ikke, at dominansen af en af de fem strategier er et transkulturelt personlighedstræk. Fra sammenhængen kan det forstås, at forfatteren går ud fra den antagelse, at sandsynligheden for præference for hver af de fem strategier er lig. Da der er statistisk signifikante sammenhænge mellem skalaindikatorerne, er det næppe muligt at tale om en lige sandsynlighed for at følge hver af de fem strategier. I en sådan situation, hvor der ikke er normative data og oplysninger om arten af fordelingen af værdier, er det mere pålideligt at stole på de statistikker, der er beregnet til din prøve. For at vurdere sværhedsgraden af dominans af en af strategierne skal du især bruge sigma og konfidensintervaller. Lad os tilføje, at det tilrådes at beregne normerne separat for mænd og kvinder. Ifølge de præsenterede data kan det ses, at indikatorerne i to ud af fem skalaer adskiller sig markant for forskellige køn. Når man sammenligner grupper eller undergrupper, kan denne kønsspecificitet være en variabel, hvis indflydelse ikke kan ignoreres.
Det tilrådes også at beregne normerne i andre tilfælde. De indledende (primære) skøn over udførelsen af eksperimentelle opgaver opnået under dataindsamlingen er langt fra altid praktiske at bruge i videre arbejde. De transformeres på en eller anden måde. De mest almindelige konverteringer er centrering og rationering standardafvigelser. Centrering forstås som en lineær transformation af værdierne for en funktion, hvor den gennemsnitlige værdi af fordelingen af en bestemt funktion bliver lig med nul. Skalaens retning og dens enheder forbliver uændrede.
Essensen af standardisering er overgangen til en anden skala - standardiserede måleenheder. Ved standardisering af testresultater udføres normalisering oftest ved hjælp af standardafvigelser. Standardisering udføres med en normal fordeling af testresultater eller tæt på den i natura.
I psykologi er der et antal skalaer baseret på en normalfordeling og med forskellige værdier på M og . For eksempel i skalaen for intelligensafvigelser IQ: M = 100, = 15; i Wechsler-skalaen M = 10, = 3. Fordelingerne af forskellige eksperimentelt målte træk har forskellige værdier på M og . Ved at oversætte de opnåede primære estimater af forskellige funktioner til en distribution med samme M og får vi flere muligheder for at vurdere og sammenligne deres variation. Brug af standardafvigelse giver os mulighed for at gøre dette. Den normaliserede afvigelse viser, hvor meget sigma afviger en eller anden mulighed fra det gennemsnitlige niveau for det forskellige tegn (aritmetisk gennemsnit) og udtrykkes med formlen:
hvor V er funktionens værdi (i indledende punkter).
Ved hjælp af den normaliserede afvigelse kan du evaluere enhver opnået værdi i forhold til gruppen som helhed, afveje dens afvigelse og samtidig slippe af med de navngivne værdier. For at slippe af med negative tal kan du tilføje en konstant til den opnåede værdi af t. Det er praktisk, hvis alle de numre, som du arbejder med, har det samme antal tegn. Under hensyntagen til disse overvejelser er T-klassificeringsskalaen meget praktisk. For denne skala vedtages en normalfordeling, som har M = 0, = 10. Til konvertering tages en konstant lig med 50. Formlen for konvertering af startpunkter til T-scores er som følger:
t = 50 + 10 -------
Lad os overveje betydningen af standardiseringsproceduren ved hjælp af et eksempel. Antag, at vi er interesserede i nogle forbindelser mellem den sædvanlige kommunikationsevne hos sælgerne og det særegne ved placeringen af en butik i en stor by. For at foretage en integreret vurdering af en bestemt sælgers kommunikative færdigheder kan vi gennem observation opnå hvert antal emner et antal parametre, der karakteriserer hans kommunikation med køberen. For eksempel kan vi måle den gennemsnitlige varighed af øjenkontakt, det gennemsnitlige antal smil ved et fast tidsinterval, antallet af uhøflige, uvelkomne opkald osv. Du kan karakterisere fordele og ulemper ved butikens placering i byen (hvor "travlt sted" osv.). For at gøre dette kan du beregne antallet af offentlige transportruter, der stopper i umiddelbar nærhed af butikken, estimere afstanden til metrostationer, tage højde for antallet af nærliggende butikker med en anden profil osv.
For at udlede en generel kommunikativ indikator er det umuligt at tilføje antallet af smil med varigheden af øjenkontakt og trække fra denne sum antallet af udtryk, der indikerer en lav talekultur. Det giver ingen mening at tilføje antallet af busruter med antallet af nærliggende butikker og trække afstanden til den nærmeste metro fra summen. Det er bedre at samle det nødvendige antal kvantitative data ved at udføre forskning i en række butikker, beregne den primære statistik for alle disse indikatorer og derefter, efter at have transformeret de oprindelige data, opnå T-scores for hver indikator.
Ved normalisering trækkes det aritmetiske gennemsnit fra hver værdi opnået under dataindsamlingen i indledende enheder, og forskellen divideres med sigma. Den resulterende værdi ganges med 10, derefter tilføjes til 50 eller trækkes fra 50. Ved at vælge den sidste aritmetiske operation (addition eller subtraktion) kan vi indstille retningen for det bidrag, som denne parameter giver til det beregnede integrale estimat, dvs. Vi kan indstille retningen for transformation under hensyntagen til detaljerne i denne parameter. Hvis en bestemt værdi i indledende enheder overstiger det aritmetiske gennemsnit, kan vi tilføje den normaliserede afvigelse (forskellen divideret med sigma) til 50. Dette svarer til en større sværhedsgrad af den vurderede mentale kvalitet i dette emne end gennemsnittet for vores prøve .
For eksempel vil det største antal smil pr. Sigma for en bestemt sælger (end i gennemsnit) nu udtrykkes kvantitativt: 60 T-point. Den kvantitative vurdering af tegn på kultur med høj tale i normaliserede afvigelser skal tilføjes til 50 T-punkter og lav talekultur - trækkes fra 50 T-punkter. Hvis for eksempel den kvantitative vurdering af et eller andet tegn på negativ orientering (i indledende punkter) overstiger gennemsnitsværdien med en halv sigma, vil den i T-point være lig med 45. Efter denne form for transformationer beregnes den integrale indikator af kommunikativ dygtighed til et bestemt emne, kan vi tilføje nogle T-scores til andre.
Det tilrådes at vælge form for datastandardisering under hensyntagen til rækkevidden af de opnåede oprindelige estimater og antallet af graderinger. Hvis antallet af graderinger i de indledende punkter er 7-15, kan stenterne være ret passende 2 ... Hvis antallet af graderinger når 30 eller mere med en let fordrejning (asymmetri), så konvertering af disse indikatorer til stenter vil vi grove punkterne, dvs. mister noget af målingens nøjagtighed. Hvis der er grund til at tro, at dine målinger er tilstrækkeligt effektive (for eksempel er der tegn på god retestpålidelighed, høje korrelationer af de målte indikatorer med klare og pålidelige eksterne valideringskriterier osv.), Så er det berettiget at bruge standardiseret enheder, der har det samme eller endda et lidt større antal graderinger.