
Нормирование (стандартизация) и унификация данных. Методы нормирования труда на предприятиях и в учреждениях - законодательство, задачи и организация
Почему нужна нормировка показателя
Обычно выраженность некоторого качества пытаются описать числом. Чаще всего такое число х формируется как сумма баллов. Насколько это правомерно — вопрос другой. Мы же предположим, что такое число х получено и осмысленно.
Обычно х меняется от некоторого минимального значения x min (отражающего отсутствие качества) до некоторого максимального значения x max (крайняя степень проявления, наличия, выраженности, …).
Его получение решает проблему сравнения двух объектов, но только по этому показателю. Впрочем, и здесь дело не очень хорошо. Надо всегда помнить, в каких пределах меняется показатель. А эти диапазоны — самые разнообразные… Да еще и оценивать, насколько близко конкретное значение к краям диапазона или к его середине. В общем, чистая морока.
Если же речь идет о сравнении по двум различным показателям — дело совсем швах. Конечно, нельзя сравнивать качества непосредственно. Для этого сравниваемые числа должны быть безразмерными. А ведь именно показатель обычно интерпретируется как степень выраженности некоторого качества. И вот это сравнивать можно!!! Но для этого их следует привести к одной шкале так, чтобы начала и концы двух шкал совпадали.
Но почему только этих двух? Давайте сделаем такое преобразование для всех показателей! Оно и называется нормировкой (не путать с нормализацией !). После этого мы можем сравнивать разнообразные показатели, полученные различными методиками.
2. Типы показателей
При всем разнообразии числовых характеристик объектов (или респондентов) из них можно выделить два широких класса:
- униполярные , выражающие только степень наличия (интенсивность, выраженность, …) некоторого качества;
- биполярные , отражающие не только степень наличия качества, но и его «направленность».
3. Нормировка униполярного показателя
Давно сложилось в науке так, что величины нормируются на диапазон от 0 до 1.
Для этого функция преобразования y=f(x) должна обладать следующими свойствами:
y(x min)=0; y(x max)=1; dy/dx>0 (1)
Любая функция с такими свойствами м.б. использована для нормировки. Например, если x max , то можно выбрать функцию
![]()
Легко видеть, что за счёт выбора соответствующей функции можно учесть разнообразные эффекты искажения оценок. Например, склонность респондента к крайним оценкам. При этом, возможно, следует применять для различных респондентов и различные функции преобразования, учитывающие особенности их личности, статуса и т.п. Примерные графики таких функций — на рис. 1.
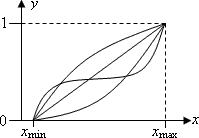
Рис. 1. Графики функции нормировки
Наиболее часто применяется линейное преобразование:
![]() (2)
(2)
Если полагать, что увеличение х описывает как возрастание выраженности качества А, так и убывание степени некоторого другого качества В, то нормированной мерой качества В может служить просто разность y´=1–y. Таковы, например, родственные по смыслу качества ‘близость’ и ‘дистанция’. Их метризация выявляет плохо осознаваемую ранее, но вполне четкую дополнительность и даже противоположность.
4. Нормировка биполярного показателя
Обычно такой показатель представляет собой ‘склейку’ двух взаимопредполагающих и антонимичных униполярных качеств А и В.
Часто В есть просто отрицание А и наоборот. По такому принципу построены, например, шкалы семантического дифференциала. Однако, пары для такого дифференциала следует проверить по словарю антонимов (например, два антонима к слову «веселый» – «грустный» и «мрачный» – вовсе не являются синонимами).
Нормировка соответствующей величины предполагает выбор «положительного » направления оси y. В качестве такового произвольно выбирается тот из полюсов шкалы, увеличение интенсивности которого принимается как возрастание y. Противоположный полюс автоматически становится «отрицательным ». Подчеркнем, что никакой модальности (аксиологической оценки) за этим нет - играть роль могут только сложившиеся смысловые стереотипы, но не более того.
Пусть величина х оценивает степень выраженности обоих качеств (с соответствующим обозначением, например, ‘очень люблю’ или ‘слегка ненавижу’). Нормировку можно проводить при помощи любой функции, удовлетворяющей условиям (1). В частности, это м.б. и линейное преобразование:
 (3)
(3)
Очевидно, что y[–1; +1].
Обе формулы (2) и (3) описывают линейное преобразование вида y=k·x+b. Поэтому все статистические выводы относительно величин x и y полностью совпадают .
5. Особенности балльных шкал
При использовании балльной шкалы имеется несколько тонкостей, которые часто упускаются из виду:
- Иногда нет ответов на все вопросы, относящиеся к данному показателю. Причины разные — ответ просто не дан, ошибка при внесении ответа или его кодировке, … Короче — имеются пропуски ответов.
- Практически всегда балл приравнивается к номеру ответа среди прочих. И наименьший балл становится равным 1.
- Хотелось бы использовать для некоторых вопросов ответ с числом градаций, отличающимся от остальных. Но тогда его вклад надо учитывать как-то по-другому.
При нормировке балльной шкалы надо всего лишь принять, что х = S, где S сумма набранных баллов по полученным ответам (а не заданных вопросов!). Соответственно, S min и S max — минимальная и максимальная суммы баллов, которые можно набрать при полученных ответах.
В этом параграфе рассматривается техника нормировки, которая полезна при решении практических задач. Для всех задач (кроме простейших) обычно удобнее использовать численные значения заданных параметров, нежели буквенные символы. После того как в задачу введены численные значения, желательно представить выражения в таком виде, чтобы числа входили в эти выражения как постоянные времени, т. е. в виде отношения искомых параметров системы, имеющего размерность времени. Часто оказывается, что постоянные времени, которые определяют динамические свойства системы, велики или малы по сравнению с единицей. Если значения постоянных времени сильно отличаются от единицы, то целесообразно сделать еще один шаг, а именно, изменить масштаб времени таким образом, чтобы наибольшие заданные параметры имели нормированные значения близкими к единице. Это позволяет упростить вычисления.
Часто случается, что удобнее применить нормировку к изображению, а не к самой функции времени. Таким образом, необходимо знать, как для заданной функции определить изображение Фурье, соответствующее нормированному времени, зная изображение Фурье для обычного времени. Как это сделать, становится ясным, если обратиться к определению преобразования Фурье. Пусть - изображение Фурье функции По определению это означает, что

Пусть - изображение Фурье функции относительно нормированного времени Согласно определению, имеем

Обычно вид функции с нормированным временем тот же, что и функции с истинным временем; при этом задан масштаб нормированного времени относительно истинного. Пусть соотношение между временами имеет вид
Здесь величина может иметь любую размерность, но обычно она имеет размерность времени и тогда событие, связанное с будет безразмерным. Символически соотношение между двумя функциями
записывается следующим образом:
После замены на в (2.5-1) получаем

Но, согласно (2.5-4), имеем
![]()
Пусть нормированная комплексная частота (1) связана с ненормированной (s) соотношением
На основании (2.5-6 и 7) формулу (2.5-5) можно переписать в виде

Согласно интеграл в правой части по определению есть нормированное преобразование Фурье Следовательно,
![]()
Таким образом, если необходимо найти нормированное изображение на основании обычного изображения, то необходимо пользоваться формулой
На основании предыдущего можно сказать: если в изображении функции времени заменить на - и полученный результат поделить на то получим изображение функции от переменной Оригинал, соответствующий этому изображению, является функцией Хотя этот результат был получен для изображения по Фурье, он также остается справедливым и для изображения по Лапласу. Нужно отметить, что рассмотренная выше процедура вычисления нормированного (соответствующего измененному масштабу времени) изображения неприменима к вычислению нормированной передаточной функции или весовой функции. Передаточную функцию
можно рассматривать как отношение изображений двух функций времени и, следовательно, множители появляющиеся в результате нормировки, в числителе и знаменателе сокращаются. Таким образом, формула для нормированной передаточной функции получается просто заменой на Делить это выражение на множитель не надо.
В качестве примера рассмотрим вычисление нормированного изображения для следующей функции времени:
![]()
Изображение этой функции имеет вид
![]()
Применяя формулу получим

![]()
Вычисляя обратное преобразование по получаем
Этот результат, очевидно, можно получить сразу из Следующий вопрос состоит в том, как вычислить на основании теоремы Парсеваля величину интегральной квадратичной ошибки, зная нормированное изображение Фурье ошибки. Напомним, что теорема Парсеваля устанавливает следующее равенство:

где I является интегральным квадратичным значением функции . В соответствии с правилом нормировки определяется формулой
Сбор информации и получение оценок показателей
Сбор информации может быть выполнен разными способами. Наиболее популярным способом являются полевые опросы. Однако прежде, чем приступать к сбору информации, необходимо определить аудиторию, на мнение которой можно будет опираться в процессе построения рейтинга. Во-первых, опрашиваемые должны иметь достаточную квалификацию для ответа на вопросы. Во-вторых, их оценка должна быть беспристрастной. При этом может возникнуть ряд неожиданных сложностей. Например, составляя рейтинг вузов, часто опрашивают студентов или выпускников этих организаций. Однако такой подход может быть неверным по следующим причинам. Во-первых, далеко не всегда человек готов признать, что его выбор был ошибочным и что другие университеты лучше того, в который он поступил или который окончил. Во-вторых, студенты редко могут провести сравнительную оценку вузов, ведь обучение они проходят лишь в одном, редко в двух заведениях.
Другим способом получения исходные данные является анализ вторичной информации (например, данных Госкомстата). Основная проблема, с которой сталкивается исследователь в этом случае – неполнота информации. Если же рейтинг основывать на данных СМИ, то велика вероятность оценить не сами компании, а работу их PR-отделов.
Разумным подходом представляется использование сводной информации о характеристиках объекта, публикуемой в различных периодических изданиях (журналы «Эксперт», «Коммерсант» и др.).
Под нормированием критериев понимается приведение локальных критериев оптимальности к единому безразмерному виду.
В качестве методов нормирования в домашнем задании применятся наиболее общеупотребляемый способ приведения критериев к безразмерному виду - линейная трансформация.
f 1 предпочтительно максимальное значение, то формула перехода от ненормированного значения показателя x 1 к нормируемому имеет вид:
 ,
,
где f 1 min и f 1 ma x – соответственно минимальное (наихудшее) и максимальное (наилучшее) значение показателя на множестве допустимых альтернатив.
Если для некоторого показателя f 1 предпочтительно минимальное значение, то формула перехода запишется в виде:
 .
.
Нормирование (стандартизация) и унификация данных
Нормированные (стандартизованные) данные. В ряде задач бывает удобно или даже необходимо перейти от исходных наблюдений, где i = 1, 2,.... п, к нормированным (стандартизованным), которые введем далее. Пусть имеются данные, на основании которых получены
![]()
Нормированными (стандартизованными ) называют данные вида
– безразмерные величины, удовлетворяющие условию
Покажем, что средняя арифметическая нормированных данных равна нулю:
а дисперсия равна единице:
При этом если нормированная величина больше нуля (.г* > 0), то наблюдаемое значение больше среднего (х ; > х). Если же х" < 0, то х, < х.
Стандартизация (нормирование) данных является необходимым начальным этапом преобразования данных при использовании многих многомерных статистических методов – снижения размерности признакового пространства (факторный, компонентный анализ, см. гл. 5), классификации объектов (кластерный анализ, см. гл. 6) и др., особенно если переменные измерены в шкалах, существенно различающихся в величинах (микроны единиц – миллиарды единиц).
Вследствие распространенности и востребованности в статистических пакетах процедура нормирования (стандартизации) обычно вынесена в меню (рис. 1.31).

Рис. 1.31. Вызов процедуры нормирования (стандартизации) данных в меню пакета STA TISTICA (StatSoft)
Унификация данных (унифицированная шкала). При построении интегральных обобщающих показателей часто возникает ситуация, когда нормирование данных не дает нужного результата. Например, нам необходимо построить интегральный показатель качества жизни в стране (регионе) , включающий в себя три исходные переменные – продолжительность жизни, младенческую смертность и уровень безработицы. При этом, даже переведя эти три показателя в единую шкалу (например, со значениями от 0 до 1 или от 0 до N), мы будем иметь конфликт в интерпретации переменных следующего плана.
Первая переменная – продолжительность жизни – характеризуется тем, что чем большие значения она принимает, тем выше качество жизни в стране (регионе). Напротив, вторая переменная – младенческая смертность – при повышении значений понижает качество жизни. Третья переменная – безработица – имеет свой некоторый оптимум (примерно 5% обеспечивает нормальное функционирование и развитие экономики ). И, соединив все три признака в один интегральный показатель, мы будем иметь отсутствие адекватной интерпретации полученного показателя. Чем он выше, тем выше продожительность жизни (лучше), выше младенческая смерность (хуже), выше безработица (непонятно). Для разрешения таких проблем и существует при анализе данных способ, позволяющий это сделать, – приведение всех переменных, участвующих в построении интегрального показателя, к единой унифицированной шкале.
Унифицированная шкала – используемая при построении интегральных показателей из различных переменных шкала, принимающая значения от 0 до N имеющая единую систему интерпретации: чем выше значения переменной в унифицированной шкале, тем выше значение интегрального показателя. При N = получаем шкалу от 0 до 1.
Переменные первого типа – чем выше показатель, тем лучше (продолжительность жизни) – приводятся к унифицированной шкале следующим образом:
где Xj – значение переменной для г-го наблюдения; amin и атах – соответственно наименьшее и наибольшее наблюдаемые значения переменной.
Согласно этой формуле если x t – amin, то а" =0, а если.г, – апт, то х] = N, т.е. чем больше значение переменной а, тем выше (лучше) ее значение в унифицированной шкале а*.
2. Переменные второго типа – чем выше показатель, тем хуже (младенческая смертность) – приводятся к унифицированной шкале следующим образом:
Согласно этой формуле если а, = ат|1), го х = N, а если а,- = а„их, то а* = 0, т.е. чем больше значение переменной а, тем ниже (хуже) ее значение в унифицированной шкале X/.
3. Переменные третьего типа – показатель имеет некий оптимум аопт, это значение наилучшее, чем больше отклонения от него, тем хуже (уровень безработицы) – приводятся к унифицированной шкале следующим образом:
Согласно этой формуле если x t = аопт, то х] = N. Если же а, имеет максимально возможное отклонение оташп, то а," =0. Например, если (ашах – а,шт) > > (aOMT-amin) и а, = атах, то а" =0. Таким образом, чем больше значение переменной а, отклоняется от оптимального, тем ниже (хуже) значение а* в унифицированной шкале, а чем ближе значение а, к этому аопт, тем лучше.
- Айвазян С. А. Анализ качества и образа жизни населения // ЦЭМИ РАН. М.: Наука, 2012. (Экономическая наука современной России).
- Там же.
Проиллюстрируем значение использования норм на примере широко известной методики К.Томаса. Напомним, что в ней вывод о доминирующей стратегии поведения в конфликтной ситуации делается с опорой на числовые данные. А именно, после подсчета суммарных баллов по каждой шкале, нужно выявить шкалу имеющую наибольший балл. Соответствующая шкале стратегия интерпретируется как доминирующая в конфликтной ситуации. Подсчитанные статистики показывают, что средние величины шкальных оценок по абсолютной величине различны. Они варьируют у мужчин от 5,25 балла до 7,25 балла и у женщин от 3,71 до 7,65 баллов (см. табл. 11).
Табл. 11. Первичные статистики шкальных оценок методики Томаса
|
Мужчины (n=56) |
Женщины (n=71) |
|||||||
|
Стратегия | ||||||||
|
Напористость | ||||||||
|
Сотрудничество | ||||||||
|
Компромисс | ||||||||
|
Избегание | ||||||||
|
Уступчивость | ||||||||
Примечание.
Средн. - средние величины;
950% и +95.0% - доверительные интервалы средних величин;
Выделены наибольшие средние величины.
Таким образом, если не учитывать нормативные данные, полученные на российской выборке (или проверенные на российской выборке), то в интерпретации результатов можно придти к неверным выводам. В самом деле, мужчинам и женщинам свойственно предпочтение стратегии избегания. В руководстве к методике не говорится о том, что доминирование одной из пяти стратегий является транскультуральной характеристикой личности. По контексту можно понять, что автор исходит из предположения о равной вероятности предпочтения каждой из пяти стратегий. Поскольку между шкальными показателями существуют статистически значимые корреляционные связи, вряд ли можно говорить о равной вероятности следования каждой из пяти стратегий. В такой ситуации, когда отсутствуют нормативные данные и сведения о характере распределения величин, надежнее опираться на подсчитанные для своей выборки статистики. В частности - для оценки выраженности доминирования одной из стратегий использовать сигму и доверительные интервалы. Добавим, что нормы целесообразно рассчитать отдельно для мужчин и женщин. По представленным данным видно, что в двух шкалах из пяти показатели значимо различаются у разных полов. При сравнении групп или подгрупп, эта половая специфичность может оказаться переменной, влияние которой нельзя не учитывать.
Вычислять нормы целесообразно и в других случаях. Полученные при сборе данных начальные (первичные) оценки выполнения экспериментальных заданий далеко не всегда удобно использовать в дальнейшей работе. Их тем или иным способом преобразуют. Наиболее частыми преобразованиями являются центрирование и нормирование среднеквадратическими отклонениями. Под центрированием понимается линейная трансформация величин признака, при которой средняя величина распределения определенного признака становится равной нулю. Направление шкалы и ее единицы остаются при этом неизменными.
Суть нормирования состоит в переходе к другому масштабу - стандартизированным единицам измерения. При стандартизировании результатов тестовых испытаний нормирование чаще всего осуществляется с помощью среднеквадратических отклонений. Стандартизирование производится при нормальном распределении тестовых оценок или близком к нему по виду.
В психологии существует целый ряд шкал, основанных на нормальном распределении и имеющих разные значения М и . Например, в шкале отклонений интеллекта IQ: М=100, =15; в шкале Векслера М=10, = 3. Распределения различных измеренных в эксперименте признаков имеют разные величины М и . Переводя полученные первичные оценки разных признаков к распределению с одними и теми же М и , мы получаем больше возможностей для оценки и сопоставления их варьирования. Сделать это нам позволяет использование нормированного отклонения. Нормированное отклонение показывает, на сколько сигм отклоняется та или иная варианта от среднего уровня варьирующего признака (средней арифметической), и выражается формулой:
где V - значение признака (в начальных баллах).
С помощью нормированного отклонения можно оценить любое полученное значение по отношению к группе в целом, взвесить его отклонение и одновременно освободиться от именованных величин. Для того чтобы избавиться от отрицательных чисел к полученной величине t можно прибавить какую-либо константу. Удобно, если все числа, с которыми вы оперируете имеют одинаковое количество знаков. С учетом этих соображений весьма удобна шкала Т-оценок. Для этой шкалы принято нормальное распределение, имеющее М=0, =10. Для пересчета берется константа равная 50. Формула преобразования начальных баллов в Т-оценки следующая:
t = 50 + 10 -------
Смысл процедуры нормирования рассмотрим на примере. Предположим, нас интересуют некоторые связи коммуникативной умелости продавцов с особенностями расположения магазина в крупном городе. Чтобы составить некоторую интегральную оценку коммуникативной умелости конкретного продавца, мы можем через наблюдение получить по каждому испытуемому ряд параметров, характеризующих его общение с покупателем. Например, мы можем измерить среднюю длительность контакта глазами, среднее количество улыбок в фиксированный интервал времени, количество грубых, неприветливых обращений и т.д. Можно охарактеризовать преимущества и недостатки расположения магазина в городе (насколько "бойкое место" и т.п.). Для этого можно подсчитать количество маршрутов городского транспорта, имеющих остановки в непосредственной близости от магазина, оценить его удаленность от станций метро, учесть число расположенных поблизости магазинов другого профиля и т.д.
Для того чтобы вывести некоторый обобщенный коммуникативный показатель невозможно складывать число улыбок с длительностью контакта глазами и вычитать из этой суммы количество выражений, свидетельствующих о низкой речевой культуре. Бессмысленно складывать число автобусных маршрутов с числом соседних магазинов и вычитать из суммы величину расстояния до ближайшего метро. Лучше собрать необходимый массив количественных данных, проводя исследование в ряде магазинов, подсчитать первичные статистики для всех этих показателей, а затем, после преобразования начальных данных, получить Т-баллы по каждому показателю.
При нормировании из каждого полученного при сборе данных значения в начальных единицах вычитают среднюю арифметическую, а разность делят на сигму. Полученную величину умножают на 10, затем прибавляют к 50 или вычитают из 50. Выбором последнего арифметического действия (сложение или вычитание) мы можем задать направление вклада, который делает этот параметр в высчитываемую интегральную оценку, т.е. можем задавать направленность преобразования, учитывая специфику данного параметра. Если конкретное значение в начальных единицах превышает среднюю арифметическую, мы можем нормированное отклонение (разность, деленную на сигму) приплюсовать к 50. Это будет соответствовать большей выраженности оцениваемого психического качества у данного испытуемого, чем в среднем по нашей выборке.
Например, большее у конкретного продавца количество улыбок на одну сигму (чем в среднем) количественно теперь будет выражено: 60 Т-баллами. Количественную оценку признаков высокой речевой культуры в нормированных отклонениях следует прибавлять к 50 Т-баллам, а низкой речевой культуры - вычитать из 50 Т-баллов. Если, например, количественная оценка некоторого признака отрицательной направленности (в начальных баллах), превышает среднюю величину на полсигмы, то в Т-баллах она будет равна 45. После такого рода преобразований, подсчитывая интегральный показатель коммуникативной умелости для конкретного испытуемого, мы можем прибавлять одни Т-баллы к другим.
Форму стандартизирования данных целесообразно выбирать с учетом размаха полученных начальных оценок и числа градаций. Если в начальных баллах число градаций 7-15, то могут оказаться вполне подходящими стенайны 2 . Если же число градаций достигает 30 и более при небольшой скошенности распределения (асимметрии), то переводя эти показатели в стенайны мы будем огрублять баллы, т.е. терять некоторую долю точности произведенного измерения. Если есть основания считать, что ваши измерения достаточно эффективны (например, есть данные о хорошей ретестовой надежности, обнаружены высокие корреляции полученных в измерениях показателей с ясными и надежными внешними критериями валидизации и т.д.), то оправданным будет использование стандартизированых единиц имеющее такое же или даже несколько большее число градаций.