
Оптимальный объем представительной выборки. Как определить оптимальный размер выборки массового опроса
При проектировании выборочного наблюдения возникает вопрос о необходимой численности выборки. Эта численность может быть определена на базе допустимой ошибки при выборочном наблюдении, исходя из вероятности, на основе которой можно гарантировать величину устанавливаемой ошибки, и, наконец, на базе способа отбора.
Формулы необходимого объема выборки для различных способов формирования выборочной совокупности могут быть выведены из соответствующих соотношений, используемых при расчете предельных ошибок выборки. Приведем наиболее часто применяемые на практике выражения необходимого объема выборки:
· собственно-случайная и механическая выборки:
(повторный отбор)
![]() (бесповторный отбор)
(бесповторный отбор)
· типическая выборка:
(повторный отбор)
![]() (бесповторный отбор)
(бесповторный отбор)
· серийная выборка:
(повторный отбор)
(бесповторный отбор)
При этом в зависимости от целей исследования дисперсии и ошибки выборки могут быть рассчитаны для средней величины или доли признака.
Рассмотрим примеры определения необходимого объема выборки при различных способах формирования выборочной совокупности.
Пример 5. В 100 туристических агентствах города предполагается провести обследование среднемесячного количества реализованных путевок методом механического отбора. Какова должна быть численность выборки, чтобы с вероятностью 0,683 ошибка не превышала 3 путевок, если по данным пробного обследования дисперсия составляет 225.
Решение . Рассчитаем необходимый объем выборки:
Агентств.
Пример 6. С целью определения доли сотрудников коммерческих банков области в возрасте старше 40 лет предполагается организовать типическую выборку пропорциональную численности сотрудников мужского и женского пола с механическим отбором внутри групп. Общее число сотрудников банков составляет 12 тыс. чел., в том числе 7 тыс. мужчин и 5 тыс. женщин.
На основании предыдущих обследований известно, что средняя из внутригрупповых дисперсий составляет 1600. Определите необходимый объем выборки при вероятности 0,997 и ошибке 5%.
Решение. Рассчитаем общую численность типической выборки:
![]() чел.
чел.
Вычислим теперь объем отдельных типических групп:
![]() чел.
чел.
![]() чел.
чел.
Таким образом, необходимый объем выборочной совокупности сотрудников банков составляет 550 чел., в т.ч. 319 мужчин и 231 женщина.
Пример 7. В акционерном обществе 200 бригад рабочих. Планируется проведение выборочного обследования с целью определения удельного веса рабочих, имеющих профессиональные заболевания. Известно, что межсерийная дисперсия доли равна 225. С вероятностью 0,954 рассчитайте необходимое количество бригад для обследования рабочих, если ошибка выборки не должна превышать 5%.
Решение. Необходимое количество бригад рассчитаем на основе формулы объема серийной бесповторной выборки:
![]() бригад.
бригад.
3.Определение необходимого объема выборки
Очень важное значение имеет определение оптимальной численности выборки, которая с определенной вероятностью обеспечит заданную точность результатов наблюдения. При увеличении численности выборки ошибка выборки уменьшается. Но так как отобранные единицы для обследования часто разрушаются, то нормы отбора единиц в выборку должны быть оптимальными. Оптимальную численность выборки можно получить из формул ошибок выборки.
Таблица 8.4
Формулы определения оптимальной численности выборки
|
Способ отбора |
Для средней |
|
|
Собственно-случайный повторный |
|
|
|
Случайный и механический бесповторный |
|
|
|
Типологический бесповторный |
|
|
|
Серийный бесповторный с равновеликими сериями |
|
|








Формулы показывают, что с увеличением предполагаемой ошибки выборки значительно уменьшается необходимый объём выборки.
Для расчета объёма выборки нужно знать дисперсию. Она может быть заимствована из проводимых ранее обследований данной или аналогичной совокупности или можно провести специальное выборочное обследование небольшого объёма.
Пример 2 : На предприятии в порядке случайной бесповторной выборки были опрошены 100 рабочих из 1000 и получены следующие данные об их доходе за октябрь (табл. 8.5).
Таблица 8.5
Распределение рабочих по размеру среднего месячного дохода
Определить:
1) среднемесячный размер дохода у работников данного предприятия, гарантируя результат с вероятностью 0,997;
2) долю рабочих предприятия, имеющих месячный доход 19 тыс. руб. и выше, гарантируя результат с вероятностью 0,954;
3) необходимую численность выборки при определении среднего месячного дохода работников предприятия, чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 200 руб.
Решение:
1) Определим среднемесячный размер дохода у работников данного предприятия, гарантируя результат с вероятностью 0,997.
|
n = 100 чел. N = 1000 чел. |
Решение
: для определения интервала среднемесячного дохода работников данного предприятия в генеральной совокупности необходимо знать величину предельной ошибки выборки Поскольку P= 0,997, то (по табл. 8.2)t = 3. Был произведен случайный бесповторный отбор, по табл. 8.3 выбираем формулу для расчета средней ошибки выборки для средней:
Размер среднемесячного дохода рабочих по данным выборочного обследования определим по формуле средней арифметической взвешенной: Дополнительные расчеты проведем в следующей таблице:
Зная t
и Тыс. руб. Тогда интервал среднего месячного дохода рабочих данного предприятия будет таким:
|
 и размер среднемесячного дохода рабочих по данным выборочного обследования
и размер среднемесячного дохода рабочих по данным выборочного обследования .
. t
и средней ошибки выборки
t
и средней ошибки выборки .
. , где
, где – дисперсия по выборке.
– дисперсия по выборке. .
.



 тыс. руб.
тыс. руб.
 тыс. руб.
тыс. руб. определим величину предельной ошибки выборки:
определим величину предельной ошибки выборки: ;
; .
.Ответ: среднемесячный размер дохода у работников данного предприятия с вероятностью 0,997 находится в пределах от 18,08 тыс. руб. до 18,92 тыс. руб.
2) Определим долю рабочих предприятия, имеющих месячный доход 19 тыс. руб. и выше, гарантируя результат с вероятностью 0,954.
|
n = 100 чел. N = 1000 чел.
|
Решение
: для определения интервала доли рабочих, имеющих месячный доход 19 тыс. руб. и выше необходимо, знать величину предельной ошибки выборки доли Предельная ошибка выборки определяется по формуле Поскольку P= 0,954, то (по табл. 8.2)t = 2. Был произведен случайный бесповторный отбор, по табл. 8.3 выбираем формулу для расчета средней ошибки выборки для доли:
Выборочная доля определяется отношением числа единиц, обладающих изучаемым признаком m
к общему числу единиц выборочной совокупностиn
, или Тогда средняя ошибка доли равна Зная t и определим величину предельной ошибки выборки для доли: Тогда интервал доли рабочих с месячным доходом 19 тыс. руб. и выше в генеральной совокупности будет таким:
|

 и долю рабочих с таким среднемесячным доходом по данным выборкиW
.
и долю рабочих с таким среднемесячным доходом по данным выборкиW
. . Она зависит от величины коэффициента доверияt
и средней ошибки выборки .
. Она зависит от величины коэффициента доверияt
и средней ошибки выборки . , гдеW
– доля рабочих предприятия, имеющих среднемесячный доход 19 тыс. руб. и выше по выборке.
, гдеW
– доля рабочих предприятия, имеющих среднемесячный доход 19 тыс. руб. и выше по выборке. .
. .
.Ответ: доля рабочих предприятия, имеющих месячный доход 19 тыс. руб. и выше, с вероятностью 0,954 находится в пределах от 19,4% до 36,6%.
Определим необходимую численность выборки при определении среднего месячного дохода работников предприятия, чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 200 руб.
|
N = 1000 чел. |
Решение : необходимая численность выборки для определения среднего месячного дохода определяется по формуле (по табл. 8.4): По условию задачи известны: при вероятности Р = 0,954 t = 2 (см. табл. 8.2) ; 0,2 тыс. руб.;
|
 (по данным предыдущей выборки).
(по данным предыдущей выборки). чел.
чел.Ответ: чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 200 руб., должны быть обследованы 189 чел.
4.5. Определение объема выборки
Процедура составления плана выборки включает последовательное решение трех следующих задач:
Определение объекта исследования;
Определение структуры выборки;
Определение объема выборки.
Как правило, объект маркетингового исследования представляет собой совокупность объектов наблюдения, в качестве которых могут выступать потребители, сотрудники компании, посредники и т.д. Если эта совокупность настолько малочисленна, что исследовательская группа располагает необходимыми трудовыми, финансовыми и временными возможностями для установления контакта с каждым из ее элементов, то вполне реально проведение сплошного исследования всей совокупности. В этом случае, определив объект исследования, можно приступать к следующей процедуре (выбору метода сбора данных, орудия исследования и способа связи с аудиторией).
Однако на практике очень часто не представляется возможным или целесообразным проведение сплошного исследования всей совокупности. Для этого могут быть следующие причины:
Невозможность установления контакта с некоторыми элементами совокупности;
Неоправданно большие расходы на проведение сплошного исследования или наличие финансовых ограничений, не позволяющих проведение сплошного исследования;
Сжатые сроки, отведенные для исследования, обусловленные утратой со временем актуальности информации или другими причинами и не позволяющие осуществить сбор, систематизацию и анализ обширных данных для всей совокупности.
Поэтому большие и разбросанные совокупности часто изучаются с помощью выборки, под которой, как известно, понимается часть совокупности, призванная олицетворять совокупность в целом.
Точность, с которой выборка отражает совокупность в целом, зависит от структуры и размера выборки .
Различают два подхода к структуре выборки - вероятностный и детерминированный.
Вероятностный подход к структуре выборки предполагает, что любой элемент совокупности может быть выбран с определенной (не нулевой) вероятностью. Существуют различные виды выборок, основанных на теории вероятностей (типическая, гнездовая и др.). Наиболее простой и распространенной на практике является простая случайная выборка, при которой каждый элемент совокупности имеет равную вероятность выбора для исследования.
Вероятностная выборка более точна, позволяет исследователю оценить степень достоверности собранных им данных, хотя она сложней и дороже, чем детерминированная.
Детерминированный подход к структуре выборки предполагает, что выбор элементов совокупности производится методами, основанными либо на соображениях удобства, либо на решении исследователя, либо на контингентных группах.
на соображениях удобства , состоит в выборе любых элементов совокупности исходя из простоты установления контакта с ними. Несовершенство этого метода обусловлено, возможно, низкой репрезентативностью полученной выборки, т.к. удобные для исследователя элементы совокупности могут быть недостаточно характерными представителями совокупности в силу неслучайного и необоснованного их отбора.
Однако, с другой стороны, простота, экономичность и оперативность исследования, проводимого этим методом, снискали ему довольно широкое распространение на практике и, прежде всего при проведении предварительных исследований, направленных на уточнение основных проблем.
Метод формирования выборки, основанный на решении исследователя , состоит в выборе элементов совокупности, которые, по его мнению, являются ее характерными представителями. Этот метод является более совершенным, чем предыдущий, поскольку в его основе лежит ориентировка на характерных представителей исследуемой совокупности, хотя и подбираемых на основе субъективных представлений исследователей о ней.
Метод формирования выборки, основанный на контингентных нормах , состоит в выборе характерных элементов совокупности в соответствии с полученными ранее характеристиками совокупности в целом. Эти характеристики могут быть получены путем проведения предварительных исследований и в отличие от предыдущего метода не носят субъективного характера. Поэтому данный метод является более совершенным, он позволяет получить выборочные совокупности не менее представительные, чем вероятностные выборки при значительно меньших затратах на проведение обследования.
Выбрав структуру выборки (подход к ее формированию, вид вероятностной или метая формирования детерминированной выборки), исследователю предстоит определить объем, т.е. количество элементов выборочной совокупности.
Объем выборки определяет достоверность информации , полученной в результате ее исследования, а также необходимые для проведения исследования затраты. Объем выборки зависит от уровня однородности или разновидности изучаемых объектов.
Чем больше объем выборки, тем выше ее точность и больше затраты на проведения ее обследования. При вероятностном подходе к структуре выборки ее объем может быть определен с помощью известных статистических формул, на основе заданных требований к ее точности.
На практике используется несколько подходов к определению объема выборки:
1. Произвольный подход основан на применении «правила большого пальца». Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход является простым и легким в исполнении, однако не представляется возможным установить точность полученных результатов. При достаточно большой совокупности он к тому же может быть и весьма дорогим.
Объем выборки может быть установлен исходя из неких заранее оговоренных условий. К примеру, заказчик маркетингового исследования знает, что при изучении общественного мнения выборка обычно составляет 1000-1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры. В случае, если на каком-то рынке проводятся ежегодные исследования, то в каждом году используется выборка одного и того же объема. В отличие от первого подхода здесь при определении объема выборки используется известная логика, которая, однако, является весьма уязвимой.
Например, при проведении определенных исследований может потребоваться точность меньше, чем при изучении общественного мнения, да и объем совокупности может быть во много раз меньше, нежели при изучении общественного мнения. Таким образом, данный подход не принимает в расчет текущие обстоятельства и может быть достаточно дорогим.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать. Очевидно, что ценность получаемой информации не принимается в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Представляется разумным учитывать затраты не абсолютным образом, а по отношению к полезности информации, полученной в результате проведенных обследований. Заказчик и исследователь должны рассмотреть различные объемы выборки и методы сбора данных, затраты, учесть другие факторы
2. Объем выборки от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки (табл. 4.2).
Таблица 4.2
Расчетная таблица выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расчетам того же автора, можно указать величины фактической ошибки выборки в зависимости от ее объема, что для нас весьма важно, памятуя, что величина допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентному уровню.
Таблица 4.3
Расчетная таблица
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
3. Объем выборки на основе статистического анализа . Этот подход основан на определении минимального объема выборки исходя из определенных требований к надежности и достоверности получаемых результатов. Он также используется при анализе полученных результатов для отдельных подгрупп, формируемых в составе выборки по полу, возрасту, уровню образования и т.п. Требования к надежности и точности результатов для отдельных подгрупп диктуют определенные требования к объему выборки в целом.
Наиболее теоретически обоснованный и корректный подход к определению объема выборки основан на расчете достоверных интервалов. Понятие вариации характеризует величину несхожести (схожести) ответов респондентов на определенный вопрос. В более строгом плане вариацией значений какого-либо признака в совокупности называется различие его значений у разных единиц данной совокупности в один и тот же период или момент времени. Результаты ответов на вопросы опроса обычно представляются в форме кривой распределения (рис. 4.1). При высокой схожести ответов говорят о малой вариации (узкая кривая распределения) и при низкой схожести ответов – о высокой вариации (широкая кривая распределения).
В качестве меры вариации обычно принимается среднее квадратическое отклонение, которое характеризует среднее расстояние от средней оценки ответов каждого респондента на определенный вопрос.

Малая вариация
Высокая вариация
Рис. 4.1. Вариация и кривые распределения
Поскольку все маркетинговые решения принимаются в условиях неопределенности, то это обстоятельство целесообразно учесть при определении объема выборки. Так как определение исследуемых величин для совокупности в узком осуществляется на основе выборочной статистики, то следует установить диапазон (доверительный интервал), в который, как ожидается, попадут оценки для совокупности в целом, и ошибку их определения.
Доверительный интервал – это диапазон, крайним точкам которого соответствует определенный процент определенных ответов на какой-то вопрос. Доверительный интервал тесно связан со средним квадратическим отклонением изучаемого признака в генеральной совокупности: чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав определенный процент ответов.
Доверительный интервал, равный или 95 %, или 99 %, является стандартным при проведении маркетинговых исследований. Ни одна фирма не проводит маркетинговых исследований, формируя несколько выборок. И математическая статистика дает возможность получить некую информацию о выборочном распределении, владея только данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, от оценки, которая ожидается для типичной выборки, является средняя квадратическая ошибка. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Когда на заданный вопрос существует только два варианта ответа, выраженные в процентах (используется процентная мера), объем выборки определяется по следующей формуле:

где n – объем выборки; z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности; p – найденная вариация для выборки; g – (100-р); е – допустимая ошибка.
При определении показателя вариации для определенной совокупности прежде всего целесообразно провести предварительный качественный анализ исследуемой совокупности, в первую очередь установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно проведение пилотного исследования, использование результатов подобных исследований, проведенных в прошлом. При использовании процентной меры изменчивости принимается в расчет то обстоятельство, что максимальная изменчивость достигается для р = 50 %, что является наихудшим случаем. К тому же этот показатель радикальным образом не влияет на объем выборки. Учитывается также мнение заказчика исследования об объеме выборки.
Возможно определение объема выборки на основе использования средних значений, а не процентных величин.

где s – среднее квадратическое отклонение.
На практике, если выборка формируется заново и схожие опросы не проводились, то s не известно. В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
 где
где  .
.
Выше шел разговор о совокупностях очень больших размеров. Однако в ряде случаев совокупности не являются большими. Обычно, если выборка составляет менее пяти процентов от совокупности, то совокупность считается большой и расчеты проводятся по вышеприведенным правилам. Если объем выборки превышает 5 % от совокупности, то последняя считается малой и в вышеприведенные формулы вводится поправочный коэффициент.
Объем выборки в данном случае определяется следующим образом:
 ,
,
Практическая работа № 8. «Определение необходимого объёма выборки»
«Определение необходимого объёма выборки»
Наиболее широко распространенным видом несплошного наблюдения является выборочное наблюдение, при котором обследуются не все единицы изучаемой совокупности, а лишь определенным образом отобранная их часть.
Вся подлежащая изучению совокупность объектов (наблюдений) называется генеральной совокупностью. Выборочной совокупностью или выборкой называется часть генеральной совокупности, отобранная для изучения свойств обеспечивающая репрезентативность.
Отбор из генеральной совокупности проводится таким образом, чтобы на основе выборки можно было получить достаточно точное представление об основных параметрах совокупности в целом. При этом речь идет как о точечной оценке, в качестве которой принимается соответствующее значение средней, доли и т.д., полученное в результате выборки, так и об интервальной оценке, т.е. о тех пределах, в которых с определенной вероятностью может находиться значение искомого параметра в генеральной совокупности. Главное требование, которому должна отвечать выборочная совокупность, - это требование ее репрезентативности, т.е. представительности.
В статистике результаты сплошного наблюдения иногда оцениваются как выборочные характеристики. Такая трактовка полученных данных имеет место в тех случаях, когда число обследованных единиц невелико и нет твердой уверенности в том, что изучаемые характеристики не могут принимать иных значений, кроме выявленных в результате наблюдения. При проведении экспериментов число значений может быть бесконечно большим, поэтому, формулируя выводы на основе ограниченного их числа, необходимо рассматривать полученные данные как выборочные характеристики.
Распространяя результаты выборочного обследования на генеральную совокупность, следует иметь в виду, что между характеристиками генеральной и выборочной совокупности возможно расхождение, обусловленное тем, что обследуется не, вся совокупность, а лишь ее часть.
Ошибкой статистического наблюдения считается величина отклонения между расчетным и фактическим значениями признаков изучаемых объектов.
Выборочный метод обеспечивает значительную экономию материальных и финансовых ресурсов при проведении статистического наблюдения, что позволяет расширить программу обследования и повысить его оперативность. Второе преимущество – высокая достоверность получаемых данных, так как при относительно небольшом объеме выборки можно организовать эффективный контроль за качеством собираемой информации. Таким образом, снижается вероятность появления ошибок регистрации и необнаружения их на стадии проверки первичной информации. И наконец, в ряде случаев, когда сплошное наблюдение связано с уничтожением или порчей обследуемых единиц (например, при проверке качества поступающих в продажу продуктов питания), возможно только выборочное обследование.
Точность оценок, полученных на основе выборочного метода, зависит не от доли обследованных единиц, а от их числа.
Основные этапы выборочного наблюдения ;
1) определение цели, задач и составление программы наблюдения;
2) формирование выборки;
3) сбор данных на основе разработанной программы;
4) анализ полученных результатов и расчет основных характеристик выборочной совокупности;
5) расчет ошибки выборки и распространение ее результатов на генеральную совокупность.
Различают виды выборки :
1) случайная (собственно-случайная);
2) механическая (например, каждый 10, 20 и т.д.);
3) типическая (стратифицированная ), когда генеральная совокупность разбита на группы и в каждой группе обследуются по нескольку объектов));
4) серийная (гнездовая ), когда случайным образом отбираются целые серии.
Наиболее простой способ формирования выборочной совокупности – собственно случайный отбор. Теоретические основы выборочного метода, первоначально разработанные применительно к собственно случайному отбору, используют и для определения ошибок выборки при других способах наблюдения.
Собственно случайный отбор может быть повторным и бесповторным. При повторном отборе каждая единица, отобранная в случайном порядке из генеральной совокупности, после проведения наблюдения возвращается в эту совокупность и может быть вновь подвергнута обследованию. На практике такой способ отбора встречается редко. Гораздо более распространен собственно случайный бесповторный отбор, при котором обследованные единицы в генеральную совокупность не возвращаются и не могут быть обследованы повторно. При повторном отборе вероятность попадания в выборку для каждой единицы генеральной совокупности остается неизменной. При бесповторном отборе она меняется, но для всех единиц, оставшихся в генеральной совокупности после отбора из нее нескольких единиц, вероятность попадания в выборку одинакова.
Населения нередко проводятся среди больших групп людей. Зачастую ошибочным является представление о том, что достоверность результатов будет выше, если на вопросы ответит каждый член общества. Вследствие огромных временных, денежных затрат и трудоемкости такое обследование оказывается неприемлемым. С ростом численности респондентов не только увеличатся расходы, но и возрастет риск получения неверных данных. С практической точки зрения множество анкетеров и кодировщиков снизят вероятность достоверного контроля их действий. Такой опрос называется сплошным.
В социологии чаще всего применяется несплошное исследование, или выборочный метод. Результаты его могут распространяться на большую совокупность людей, которая именуется генеральной.
Определение и значение выборочного метода
Выборочный метод- это количественный способ отбора части исследуемых единиц из общей массы, при этом итоги обследования будут распространяться и на каждого индивида, не принявшего участия в этом.
Выборочный метод является и предметом научного исследования, и учебной дисциплиной. Он выступает средством получения достоверной информации о генеральной совокупности и помогает дать оценку всех ее параметров. Условия отбора единиц влияют в последующем на статистический анализ результатов. Если выборочные процедуры осуществлены некачественно, использование даже самых надежных методов обработки собранной информации окажется бесполезным.

Ключевые понятия теории выбора
Называют взаимосвязь единиц, относительно которых формулируются выводы выборочного исследования. В качестве нее могут выступать жители одной страны, конкретного населенного пункта, рабочий коллектив предприятия и т. д.
Выборочную совокупность (или выборку) составляет часть генеральной, которая была выделена с использованием специальных методик и критериев. Например, в процессе формирования учитываются статистические критерии.
Количество индивидов, вошедших в ту или иную совокупность, называют ее объемом. Но он может быть выражен не только числом людей, но и избирательными участками, населенными пунктами, то есть определенно крупными единицами, включающими в себя единицы наблюдения. Но это уже является многоступенчатой выборкой.
Единицей отбора являются составные части генеральной совокупности, ими могут быть как непосредственно единицы наблюдения (одноступенчатая выборка), так и более крупные формирования.
Большую роль в получении достоверных результатов исследования с применением выборочного метода является такое свойство, как репрезентативность отбора. То есть часть генеральной совокупности, ставшая респондентами, должна полностью воспроизводить все ее характеристики. Любое отклонение признается ошибкой.

Этапы применения выборочного метода
Каждое эмпирическое состоит из этапов. В случае применения выборочного метода их очередность будет выстроена следующим образом:
- Создание проекта выборки: устанавливается генеральная совокупность, характеризуются процедуры выбора, объемы.
- Реализация проекта: в ходе сбора социологической информации происходит выполнение анкетерами заданий с указанием способом отбора респондентов.
- Выявление и корректировка ошибок репрезентативности.
Типы выборок в социологии
После определения генеральной совокупности исследователь переходит к выборочным процедурам. Они могут разделяться по двум видам (критериям):
- Роль вероятностных законов в ходе осуществления выборки.
- Количество ступеней отбора.
Если применять первый критерий, то выделяют метод случайной выборки и неслучайный отбор. На основании последнего можно утверждать, что выборка может быть одноступенчатой и многоступенчатой.
Типы выборокпрямым образом отражаются не только на этапах подготовки и проведения исследования, но и на его результатах. Прежде чем отдать предпочтение одному из них, следует разобраться в содержании понятий.
Определение «случайный» в бытовом применении получило совершенно противоположенное значение, чем в математике. Такой отбор осуществляется по строгим правилам, не допускается никакое отступление от них, так как важно обеспечить каждой единице генеральной совокупности одинаковые шансы быть включенной в выборку. При несоблюдении данных условий эта вероятность будет разной.
В свою очередь случайная выборка подразделяется на:
- простую;
- механическую (систематическую);
- гнездовую (серийную, кластерную);
- стратифицированную (типическую или районированную).
Простой выборочный метод осуществляется при помощи таблицыслучайных чисел. Первоначально определяется объем выборки; создается полный перечень пронумерованных респондентов, входящих в генеральную совокупность. Используются для отбора специальные таблицы, содержащиеся в математико-статистических изданиях. Любые отличные от них применять запрещается. Если объем выборкипредставляет трехзначное число, то номер каждой единицы отбора должен быть трехзначным, а именно: от 001 до 790. Последнее число означает общее количество человек. В исследовании примут участие те люди, которым был присвоен номер в указанном диапазоне, встречающийся в таблице.

Систематический отбор основан на вычислениях. Предварительно составляется алфавитный список всех элементов генеральной совокупности, устанавливается шаг и только потом - объем выборки. Формула для шагапредставлена следующим образом:
N: n, где N - генеральная совокупность, а n - выборка.
Например, 150 000: 5 000 = 30. Таким образом, каждый тридцатый человек будет отобран для участия в опросе.
Сущность гнездового типа
Гнездовая выборка используется в условиях, если исследуемая совокупность людей состоит из маленьких по числу естественных групп. В таком случае следует учесть, что на первом шаге определяется списочное количество таких гнезд. При помощи таблицы случайных чисел происходит отбор и проводится сплошной опрос всех респондентов, состоящих в каждом отобранном гнезде. При этом чем больше их приняло участие в исследовании, чем меньше средняя ошибка выборки. Однако использовать такую методику возможно при условии наличия схожего признака у изучаемых гнезд.
Сущность стратифицированного выбора
Стратифицированная выборка отличается от предыдущих тем, что накануне отбора генеральная совокупность разбивается на страты, то есть однородные части, имеющие общий признак. Например, уровень образования, электоральные предпочтения, уровень удовлетворенности различными сторонами жизни. Самым простым вариантом является разделение испытуемых по полу и возрасту. Принципиально необходимо провести отбор таким образом, чтобы из каждой страты было выделено число лиц, пропорциональное общему количеству.
Объем выборки в таком случае может быть меньшим, чем в ситуации со случайным отбором, но при этом репрезентативность будет выше. Следует признать, что стратифицированная выборка будет самой затратной в финансовом и информационном плане, а гнездовая - самой выгодной в этом плане.

Неслучайная квотная выборка
Существует также квотная выборка. Она - единственный вид неслучайного отбора, который имеет математическое обоснование. Квотная выборка формируется из единиц, которые должны быть представлены пропорциями и соответствовать генеральной совокупности. В таким виде осуществляется целенаправленное распределение признаков. Если в числе исследуемых признаков выступают мнения, оценки людей, то квотными являются зачастую пол, возраст, образование респондентов.
В социологическом исследовании выделяют также два способа отбора: повторный и бесповторный. При первом избранная единица после обследования возвращается в генеральную совокупность, чтобы дальше участвовать в отборе. Во втором варианте респонденты отсортировываются, что повышает шансы остальных членов генеральной совокупности быть выбранным.
Ученый-социолог Г. А. Черчилль разработал такое правило: размер выборки должен стремиться обеспечить не меньше 100 наблюдений для первостепенных и 20-50 для второстепенной классификационной составляющей. Следует иметь в виду, что часть респондентов, вошедших в выборку, по различным причинам может не принять участие в опросе или вовсе от него отказаться.

Способы определения объема выборки
В социологических исследованиях применимы такие методы:
1. Произвольный, то есть объем выборки определяется в пределах 5-10 % состава генеральной совокупности.
2. Традиционный метод расчета основывается на проведении регулярных исследований, например, один раз в год с охватом 600, 2 000 или 2 500 респондентов.
3. Статистический - заключается в установлении надежности информации. Статистика как наука не развивается изолированно. Предметы и области ее исследования активно задействуются в других смежных отраслях: технических, экономических и гуманитарных. Так, ее методы используются в социологии, при подготовке к опросам и, в частности, при определении объемов выборок. Статистика как наука обладает обширной методологической базой.
4. Затратный, при котором установлена допустимая сумма расходов на исследование.
5. Объем выборки равен может быть числу единиц генеральной совокупности, тогда исследование будет носить сплошной характер. Такой подход применим в малых группах. Например, трудовой коллектив, студенты и т. д.
Ранее удалось установить, что выборка будет считаться репрезентативной, когда ее характеристики описывают свойства генеральной совокупности с минимальной погрешностью.
Оценка объема выборки предваряет окончательные расчеты количества единиц, которые будут выделены из генеральной совокупности:
n = Npqt 2: N∆ 2 p + pqt 2 , в которой N - количество единиц генеральной совокупности, p - доля изучаемого признака (q = 1 - p), t - коэффициент соответствия доверительной вероятности Р (определяется по специальной таблице), ∆ p - допустимая ошибка.
Это только один вариант того, как вычисляется объем выборки. Формула может изменяться в зависимости от условий и выбранных критериев исследования (например, повторная или бесповторная выборка).
Ошибки выборки
Социологические опросы населения основываются на использовании одного из типов выборки, рассмотренных нами выше. Однако в любом случае задачей каждого исследователя должна стать оценка степени точности полученных показателей, то есть нужно определить, насколько они отражают характеристики генеральной совокупности.
Ошибки выборки можно разделить на случайные и неслучайные. Первый вид подразумевает отклонение выборочного показателя от генерального, которое можно выразить разностью их долей (средней) и которое вызвано только не сплошным типом обследования. И совершенно закономерно, если этот показатель снижается на фоне увеличения количества опрошенных респондентов.
Систематической ошибкой называют отклонение от генерального показателя, также найденное в результате вычитания выборочной и генеральной доли и возникшее из-за несоответствия методики формирования выборки установленным правилам.
Данные типы ошибок входят в общую ошибку выборки. В исследовании из генеральной совокупности можно извлечь только одну выборку. Расчет величины максимально возможного отклонения выборочного показателя можно выполнить по специальной формуле. Оно называется предельной ошибкой выборки. Существует также такое понятие, как средняя ошибка выборки. Это среднее квадратическое отклонение выборочных от генеральной долей.
Выделяют также апостериорный (послеопытный) вид ошибки. Под ним подразумевается отклонение показателей выборочной от генеральной доли (средней). Оно вычисляется методом сравнения генерального показателя, информация о котором поступила от надежных источников, и выборочного, который был установлен в ходе опроса. В качестве достоверных источников информации выступают нередко отделы кадров предприятий, государственные органы статистики.
Существует также априорная ошибка, также являющаяся отклонением выборочного и генерального показателей, которой можно выразить разностью их долей и рассчитать которую можно по специальной формуле.

В учебных исследованиях чаще всего совершаются следующие ошибки, связанные с проведением отбора респондентов для опроса:
1. Выборочные совокупности групп, принадлежащие к разным генеральным. При их использовании разрабатываются статистические выводы, которые относятся ко всей выборке. Совершенно очевидно, что это не может быть приемлемо.
2. В расчет не принимаются организационные и финансовые возможности исследователя, когда рассматриваются типы выборок, и одной из них отдается предпочтение.
3. Не в полном объеме используются статистические критерии структуры генеральной совокупности при предотвращении ошибок выборки.
4. Не учитываются требования репрезентативности отбора респондентов в ходе сравнительных исследований.
5. Инструкция для интервьюера должна быть адаптирована с учетом специфики принятого типа отбора.
Характер участия респондентов в исследовании может быть открытым или анонимным. Это следует учитывать про формировании выборки, так как, не согласившись с условиями, участники могут выбыть.
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – в газетах/журналах, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев .
Расчет объема выборки
Из всех вопросов, которые задают сотрудникам знаменитого Института опросов общественного мнения Гэллапа, самым популярным является такой: как вы можете, проинтервьюировав 1000 человек, судить о том, что думают 250 млн американцев?
Для ответа на этот вопрос нужно упомянуть не только высокую квалификацию и огромный практический опыт сотрудников, но и использование ими статистики и математики. Если методы опроса не основаны на науке, результаты могут ввести вас в заблуждение.
В статистике приняты следующие разграничения объемов выборки. Объем выборки, достаточный для взаимопогашения случайностей и.получения статистических характеристик закономерного характера, равен 30. Выборка такого объема называется малой. Характер распределения значений признака в малых выборках приближается к нормальному с ростом числа испытаний. Минимальный объем выборки, позволяющий получить средние значения признака с указанием доверительных вероятностей, равен 5. Выборки такого объема называются сверхмалыми. Распределение значений признака в таких выборках характеризуется распределением Стьюдента. Но чаще всего в социологии имеют дело с гораздо большим объемом выборки.
При планировании выборочного обследования наступает момент, когда нужно решить, сколько человек опрашивать, т.е. каким должен быть объем выборки. Это решение чрезвычайно важно, поскольку слишком большая выборка потребует излишних затрат, а слишком маленькая понизит качество результатов.
Объем выборки - общее число единиц наблюдения, включенных в выборочную совокупность.
Поскольку выборочная совокупность - это часть генеральной совокупности, отобранная с помощью специальных методов, - важно, чтобы эта часть не искажала представления о целом, т.е. репрезентировала его. Социологов, часто проводящих эмпирические исследования, постоянно волнует вопрос о том, как много надо опрашивать человек, чтобы получить достоверную информацию? Институт Гэллапа в США проводит регулярные опросы по национальной выборке объемом в 1,5 тыс. человек и достигает поразительной точности (ошибка выборки составляет от 1 до 1,5%). Центр «Социо-Экспресс» Института социологии РАН проводит исследования на выборке объемом в 2 тыс. человек, при этом ошибка выборки не превышает 3% 31 .
Специалисты считают, что наилучшая выборка - не обязательно большая. Конечно, чем больше объем выборки, тем выше точность ее результатов. Однако даже огромная выборка не гарантирует успеха, если генеральная совокупность «плохо перемешана», т.е. является неоднородной. Однородной считается такая совокупность, в которой контролируемый признак распределен равномерно, не образует пустот или сгущений. В этом случае, опросив нескольких человек, можно получить точную информацию о распределении этого признака в генеральной совокупности.
Таким образом, на репрезентативность данных влияют не количественные характеристики выборочной совокупности (ее объем), а качественные характеристики генеральной совокупности - степень ее однородности.
В социологии еще не придумано единой и четкой формулы, используя которую можно рассчитать оптимальный объем выборочной совокупности, - такой формулы просто не существует в природе. И объясняется это весьма просто. Дело в том, что определение объема выборочной совокупности - проблема не столько статистическая, сколько содержательная. Иными словами, объем выборочной совокупности зависит от множества факторов, в том числе от целей и задач, теоретической модели, гипотез и методов исследования, степени однородности генеральной совокупности, наконец, требующейся точности получаемой информации.
Надо всегда помнить, что каждый процент прироста точности информации в исследовании приводит к резкому увеличению расходов на его проведение. Знаменитый институт Гэллапа, на протяжении многих десятилетий проводящий опросы в США, выявил, что при общенациональной выборке в 100 человек - ошибка выборки будет в пределах ±11%; 200 человек - ±8%; 400 - ±6%; 600 - ±5%; 750 -±4%; 1000 - ±4%; 1500 - ±3%; 4000 человек - ±2%. Именно поэтому он проводит общенациональные опросы в США на выборке в 1500- 2000 человек. Как видно, он предпочитает увеличение ошибки на 1% многократному увеличению стоимости исследования.
Практика показывает, что для многих социологов обоснование объема выборки является камнем преткновения, несмотря на значительное количество литературы, посвященной выборочным методам и, в частности, расчету объема выборки. Причин несколько: 1) дефицит специальной литературы на периферии; 2) нехватка времени для самообразования; 3) неумение пользоваться математическим аппаратом. В связи с этим возникает необходимость без сложных математических формул изложить стратегию и тактику обоснования объема выборки.
Процедура расчета объема выборки - цепь бесконечных компромиссов между стремлением к точности и ограниченностью ресурсов, дефицитом времени и неполнотой сведений об изучаемом явлении. Вместе с тем это наука и искусство, познание которых доступно каждому человеку. Однако для этого нужно знать стратегии расчета объема выборки (предварительного расчета, последовательной и комбинированной стратегии), а также факторы, влияющие на объем выборки (объем генеральной совокупности, варьирование ответов респондентов, точность оценивания, характер предполагаемого распределения ответов, метод исследования, процедура обработки).
Стратегия предварительного расчета состоит в том, что объем выборки определяется до проведения основного исследования. В наиболее простом случае можно воспользоваться уже наработанным опытом, например, института Гэллапа, где используется объем выборки приблизительно в 1500-2000 человек. Для среднестатистического отечественного исследования объема выборки - примерно 400-600 человек.
Для расчета объема случайной выборки надо знать желаемую точность оценивания, величину риска получаемого ответа и степень изменчивости ответа. Традиционно точность оценивания принимают за 5%, а величину риска - за 0,95. Иными словами, если по данным выборочного исследования 60% опрошенных удовлетворены работой, то можно утверждать, что в генеральной совокупности доля удовлетворенных составит от 55 до 65% в 95% случаев, а в 5% случаев такая доля может выйти за этот интервал. Если исходить из 5%-ной точности и величины риска в 0,95, объем выборки будет следующим (табл. 2.4).
Таблица 2.4 Зависимость объема выборки от объема генеральной совокупности
Результаты, приведенные в табл. 2.4, свидетельствуют против распространенного заблуждения, будто бы объем выборки - жестко фиксированный процент от генеральной совокупности, равный 10. На самом же деле эта величина - не постоянная, а переменная, изменяющаяся в конкретных условиях. Объем выборки зависит также от того, какие вопросы используются в анкете. Цифры в табл. 2.4 действительны только для одного случая - когда речь идет о дихотомическом вопросе, у которого максимальный разброс ответов - 50 на 50%. Не имея предварительной информации о разбросе оценок, социолог как бы заранее страхуется и считает, что этот разброс составит 50 на 50%. Если же такая информация имеется, то объем выборки будет следующим.
Таблица 2.5 Зависимость объема выборки от распределения дихотомического ответа
В табл. 2.5 показано распределение ответов на качественные вопросы. Расчет объема выборки для количественных вопросов, включающих вопросы типа «возраст» и «заработная плата», строится исходя из коэффициента вариации (табл. 2.6), который показывает, какой процент составляет среднее квадратическое отклонение от средней арифметической, и позволяет сравнивать между собой (по степени варьирования) любые признаки.
Таблица 2.6 Зависимость объема выборки от коэффициента вариации
| Коэффициент вариации, % | ||||||||||||
| Объем выборки |
Если изучаются условия труда, взаимоотношения в коллективе, заработная плата и т.д. с помощью пятичленной шкалы, то коэффициент вариации изменяется здесь от 27 до 62%, а при использовании семичленной - от 78 до 113%. Стало быть, чем длиннее шкала, тем выше коэффициент вариации и больше должен быть объем выборки. Если социолог хочет обойтись небольшой выборкой, то и вопросы должен формулировать проще. Иногда думают, что чем длиннее шкала, тем точнее измерение. Но преимущества семибалльных шкал над пятибалльными не доказаны.
Среди социологов распространено мнение, согласно которому чем больше объем выборки, тем точнее результат, и это заставляет их непомерно увеличивать количество опрошенных. В реальности дело обстоит иначе: табл. 2.7, составленная по данным Института Гэллапа, показывает зависимость между объемом выборки и точностью оценивания в процентах. Из нее следует, что с увеличением объема выборки точность возрастает, но до определенного порога. Уже при 600 опрошенных достигается желанный для всех 5%-ный уровень точности. Стало быть, 600 человек - приемлемый объем выборки.
Между цифрами 400 и 600 человек противоречия нет. В первом случае объем выборки рассчитывался, исходя из положения о нормальном распределении ответов респондентов, а во втором - из практики. Расхождение между теорией и практикой обусловлено тем, что в реальной ситуации распределение оценок отличается от нормального, поэтому объем выборки надо рассчитывать с учетом именно этого обстоятельства; наиболее эффективным способом уменьшения объема выборки является снижение коэффициента вариации оценок.
Таблица 2.7 Зависимость между объемом выборки и точностью оценивания
При расчете объема выборки социологи часто совершают такую ошибку: рассчитав по существующим формулам необходимый объем выборки в целом для совокупности, в дальнейшем пропорционально размещают его по отдельным подразделениям выборки, например по цехам, предприятиям, районам, городам, типам семей. После чего на этапе обработки данных - анализируют уже сами различия между подразделениями. Однако правильнее вычислить объем выборки отдельно для каждого подразделения, а)атем суммировать отдельные объемы. Допустим, расчеты объема выборки по трем цехам (с учетом размерности шкалы, численности работающих, характера предполагаемого распределения оценок) позволили установить, что в первом цехе необходимо спросить 384 человека, во втором - 222, а в третьем - 600. Тогда общий объем выборки составит 384 + 222 + 600 = 1206 человек.
Если социологу необходимо опросить какую-либо категорию работников (допустим, водителей автобусов), о которой известно лишь, что к ней принадлежит, например, десятый работник предприятия, и он решил спросить 139 водителей автобусов, а общий объем выборки для предприятия составит 1390 человек, т.е. иными словами, отбирая случайным образом 1390 респондентов на предприятии, мы в соответствии с теорией выборки надеемся выявить 139 человек интересующей нас специальности.
При расчете квотной выборки социологи часто произвольно определяют ее объем в 1000 человек, исходя из удобства вычисления квот. Но с таким же успехом можно взять любое другое круглое число. Более обоснованным является подход, при котором объем квотной выборки рассчитывается как для случайной. Другим вариантом расчета объема квотной выборки является использование теории малых выборок. Ее суть: если не ставится цель дать дифференцированный анализ по группам работников, то умножают количество градаций вопросов, подлежащих изучению, на 25 (минимальный статистический значимый размер группы). Например, изучают три переменные: пол - две категории, возраст - две категории (до 30 лет и свыше 30 лет), удовлетворенность трудом - измеряется пятибалльной шкалой. Тогда необходимый объем выборки для данного примера составит 2x2x5x25 = 500 человек. Объем выборки увеличивается в 2,5 раза. Ясно, что с расширением числа переменных и числа градаций объем выборки может стать катастрофически большим. Выход только один: детальная проработка исходной проблемы, которая позволит отбраковать лишние вопросы в анкете, оставив самые важные. Если в исследовании проверяется несколько гипотез, то объем выборки для проверки каждой гипотезы вычисляется отдельно. Таким образом, при использовании выборки количество вопросов в анкете и гипотез должно быть минимальным.
Итак, мы рассчитали требуемый объем выборки. Теперь, и только теперь необходимо проверить, совместима ли полученная величина с выделенными ресурсами. Типичная ошибка многих социологов-прикладников состоит в том, что при расчете объема выборки во главу угла ставятся наличные ресурсы или, хуже того, социолог пассивно принимает все условия, диктуемые заказчиком. Это в корне неверно по нескольким причинам. Во-первых, расчет объема выборки позволяет глубже проникнуть в суть изучаемого предмета и специфику методов исследования, а значит, аргументированно требовать получения больших ресурсов или принять правильное решение о снижении объема выборки. Если администрация отказала в дополнительных ресурсах, а цели исследования не позволяют сократить объем выборки (т.е. социолог не может принять решение администрации), то надо переходить к другой схеме исследования. Во-вторых, обоснованный расчет объема выборки показывает профессионализм социолога и заставляет заказчика относится к нему более уважительно.
Стратегия последовательного расчета объема выборки. При расчете объема выборки желательно знать разброс оценок и некоторые другие параметры. Однако они-то, как правило, неизвестны. Для того чтобы не допустить ошибки, лучше предположить, что они максимальны. Плата за наше незнание - разбухание объема выборки сверх необходимого и дополнительные финансовые и временные затраты (приходится опрашивать большее число людей). Для сохранения затрат применяется последовательная стратегия - объем выборки не рассчитывается заранее, а ставится в зависимость от конечных результатов исследования. Например, опрашивают 100 человек, затем устанавливают величину разброса оценок и уже в зависимости от этого рассчитывают необходимый объем выборки. Если оказывается, что 100 человек достаточно, то исследование заканчивается. В противном случае добирается необходимое количество респондентов, но не до бесконечности. Известен пример из практики Дж. Гэллапа, который в начале своей карьеры активно экспериментировал с объемами выборки. В 1936 г. американцам был задан вопрос: «Хотели бы вы возобновления закона о восстановлении национальной промышленности?» Выяснился странный парадокс: Дж. Гэллап вначале опросил 500 человек и замерил ошибку выборки, а затем последовательно наращивал число респондентов до 30 тыс. К своему сожалению, он обнаружил, что прибавление 29,5 тыс. опрошенных увеличило точность информации менее чем на 1%. Следовательно, опрос можно было прекращать уже при 500 опрошенных. Этот пример показывает, что, применяя последовательную стратегию, можно добиваться значительного снижения необходимого числа наблюдений по сравнению с предварительным расчетом объема выборки.
Однако стратегия последовательного расчета объема выборки приносит желаемый результат лишь в том случае, если социолог может производить необходимые расчеты в ходе самого опроса, например телефонного, с применением компьютерных систем. Социолог вводит ответы респондента в свой персональный компьютер, с него результаты сразу поступают на компьютер руководителя исследования, обрабатываются, и на экране дисплея выдается информация не только об одномерных частотах, распределенных по тому или иному вопросу, но и о требуемом объеме выборки.
Если существует опасность, что объем выборки может оказаться катастрофически большим, надо совместить оба вида стратегии - предварительную и последовательную, т.е. применить комбинированную стратегию. Рассчитывая выборку по предварительной стратегии, получаем верхние допустимые значения для последовательной стратегии или, иначе говоря, ту величину объема выборки, при достижении которой прекращается опрос по последовательной стратегии.
Наиболее обоснованный и корректный подход к определению объема выборки основан на расчете доверительных интервалов, в основе которого лежит ряд базовых понятий математической статистики (вариация, среднее квадратическое отклонение, доверительный интервал, средняя квадратическая ошибка).
Для расчета необходимого размера выборки в количественном исследовании чаще всего используют два статистических понятия - доверительный интервал и доверительную вероятность. Доверительный интервал представляет собой заранее задаваемую вами погрешность выборки. Например, если вы задаете доверительный интервал в 3% и конкретный ответ на конкретный вопрос исследования составит 48%, это значит, что даже при проведении опроса всей генеральной совокупности реальное значение попадет в интервал между 45 (48 - 3) и 51% (48 + 3). Доверительная вероятность показывает, насколько вы можете быть уверены в полученных результатах, в том, что характеристики выборки соответствуют характеристикам всей генеральной совокупности - иными словами, с какой вероятностью случайный ответ попадет в доверительный интервал. Обычно используют доверительную вероятность 95 и 99%. Чаще всего используется 95% - этого вполне достаточно в подавляющем большинстве исследований. Если объединить доверительную вероятность и доверительный интервал, то можно сказать, что ответы на вопрос с 95%-ной вероятностью попадут в интервал между 45 и 51%.
Весьма полезна следующая приблизительная оценка надежности результатов выборочного обследования. Повышенная надежность допускает ошибку выборки до 3%, обыкновенная - от 3 до 10% (доверительный интервал распределений на уровне 0,03- 0,1), приближенная - от 10 до 20%, ориентировочная - от 20 до 40%, а прикидочная - более 40%.
На основе этих понятий с учетом ряда предположений выводятся формулы расчета объема выборки, которые предполагают, что репрезентативность гарантируется путем использования корректных вероятностных процедур формирования выборки.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать, и очевидно, что ценность получаемой информации не принимается при этом в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Исследовательская практика подсказывает следующее правило: объем выборки должен обеспечивать не менее 100 наблюдений для каждой первостепенной и не менее 20-50 наблюдений для каждой второстепенной классификационной составляющей. 11ервостепенные классификационные составляющие соответствуют наиболее критичным, а второстепенные - наименее критичным ячейкам перекрестной классификации, принятой в данном исследовании 34 . Теоретические расчеты и практика доказывают, что для получения достоверных данных о мнении и предпочтениях населения такого крупного города, как Санкт-Петербург, достаточно опросить 700-800 человек. Однако большинство опросов населения здесь проходят на выборках объемом до 1,5 тыс. человек.
Ошибка выборки
Как мы уже знаем, репрезентативность - свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности - мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной - 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями - генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой - «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки - отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными».
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа - случайные и систематические. Случайная ошибка - это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности (табл. 2.8).
Таблица 2.8
Зависимость объема выборки от ее ошибки 36 (размер генеральной совокупности составляет 20 тыс. ед.)
| Ошибка выборки, % | |||||||||||||
| Объем выборки, ед. |
Второй тип ошибок выборки - систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки - результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например: 1) выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд); 2) налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%); 3) отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
♦ нарушены методические и методологические правила проведения социологического исследования;
♦ выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
♦ произошла замена требуемых единиц наблюдения другими, более доступными;
♦ отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее - в самом начале исследования.
Вот некоторые способы избежать ошибок:
♦ каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
♦ отбор желательно производить из однородных совокупностей;
♦ надо знать характеристики генеральной совокупности;
♦ при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, характеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностью. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ - увеличивать размеры выборки (и идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь - совершенствовать математические методы составления выборки. Они-то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал - математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже - тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов: I) стоимости сбора информации и 2) стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь. Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны помученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, - 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно (гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки (табл. 2.9):
Таблица 2.9
Расчеты репрезентативной выборки
Это означает, что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной 39 вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33±5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки (см. выше).
Сегодня многие трудные расчеты берет на себя техника, а статистические программы можно получить по Интернету. Вот и с расчетом выборки ленивому социологу предоставили такую возможность на веб-сайте Аналитического центра «Бизнес и маркетинг» (http://www.bma.ru/enter.htm), где пользователю надо лишь внести необходимые данные, а затем нажать на кнопку «Рассчитать».
Интервальное оценивание вероятности события. Формулы расчета численности выборки при собственно-случайном способе отбора.Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:

где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K | 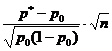 | 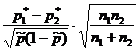 |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.