
Ang pinakamainam na sukat ng isang kinatawan na sample. Paano matukoy ang pinakamainam na laki ng sample para sa isang mass survey
Kapag nagdidisenyo ng isang sample na pagmamasid, ang tanong ay lumitaw tungkol sa kinakailangang laki ng sample. Ang kasaganaan na ito ay maaaring matukoy batay sa margin ng error sa sampling, sa batayan ng posibilidad sa batayan kung saan ang laki ng error na matutukoy ay maaaring matiyak, at, sa wakas, sa batayan ng paraan ng pagpili .
Ang mga formula para sa kinakailangang laki ng sample para sa iba't ibang paraan ng pagbubuo ng sample na populasyon ay maaaring makuha mula sa mga kaukulang ratio na ginamit sa pagkalkula ng mga marginal sampling error. Narito ang mga expression na pinakamadalas na ginagamit sa pagsasanay para sa kinakailangang laki ng sample:
Wastong random at mekanikal na sampling:
(muling pagpili)
![]() (hindi paulit-ulit na pagpili)
(hindi paulit-ulit na pagpili)
Karaniwang sample:
(muling pagpili)
![]() (hindi paulit-ulit na pagpili)
(hindi paulit-ulit na pagpili)
Serial sampling:
(muling pagpili)
(hindi paulit-ulit na pagpili)
Kasabay nito, depende sa mga layunin ng pag-aaral, ang pagkakaiba at mga error sa pag-sample ay maaaring kalkulahin para sa average na halaga o bahagi ng isang tampok.
Isaalang-alang natin ang mga halimbawa ng pagtukoy ng kinakailangang laki ng sample para sa iba't ibang paraan ng pagbuo ng sample na populasyon.
Halimbawa 5. Sa 100 mga ahensya ng paglalakbay ng lungsod, pinlano na magsagawa ng isang survey ng average na buwanang bilang ng mga nabentang voucher sa pamamagitan ng paraan ng mekanikal na pagpili. Ano ang dapat na laki ng sample upang, na may posibilidad na 0.683, ang error ay hindi lalampas sa 3 pass, kung ayon sa pilot survey ang pagkakaiba ay 225.
Solusyon... Kalkulahin natin ang kinakailangang laki ng sample:
Mga ahensya.
Halimbawa 6. Upang matukoy ang proporsyon ng mga empleyado ng mga komersyal na bangko ng rehiyon sa edad na 40, iminumungkahi na ayusin ang isang tipikal na sample na proporsyonal sa bilang ng mga empleyadong lalaki at babae na may mekanikal na pagpili sa loob ng mga grupo. Ang kabuuang bilang ng mga empleyado sa bangko ay 12 libong tao, kabilang ang 7 libong kalalakihan at 5 libong kababaihan.
Batay sa mga nakaraang survey, alam na ang average ng mga pagkakaiba-iba sa loob ng grupo ay 1600. Tukuyin ang kinakailangang laki ng sample na may posibilidad na 0.997 at isang error na 5%.
Solusyon. Kalkulahin natin ang kabuuang sukat ng isang tipikal na sample:
![]() mga tao
mga tao
Kalkulahin natin ngayon ang dami ng mga indibidwal na tipikal na grupo:
![]() mga tao
mga tao
![]() mga tao
mga tao
Kaya, ang kinakailangang dami ng sample na populasyon ng mga empleyado ng mga bangko ay 550 katao, kasama. 319 lalaki at 231 babae.
Halimbawa 7. Ang joint-stock na kumpanya ay mayroong 200 pangkat ng mga manggagawa. Ito ay binalak na magsagawa ng isang sample survey upang matukoy ang proporsyon ng mga manggagawa na may mga sakit sa trabaho. Nabatid na ang pagkakaiba-iba ng inter-serye ng bahagi ay katumbas ng 225. Sa posibilidad na 0.954, kalkulahin ang kinakailangang bilang ng mga koponan para sa pagsusuri sa mga manggagawa kung ang error sa sampling ay hindi dapat lumampas sa 5%.
Solusyon. Kakalkulahin namin ang kinakailangang bilang ng mga koponan batay sa formula para sa dami ng serial na hindi paulit-ulit na sampling:
![]() mga brigada.
mga brigada.
3. Pagpapasiya ng kinakailangang laki ng sample
Napakahalaga na matukoy ang pinakamainam na laki ng sample, na, na may tiyak na posibilidad, ay magbibigay ng isang naibigay na katumpakan ng mga resulta ng pagmamasid. Habang tumataas ang laki ng sample, bumababa ang error sa sampling. Ngunit dahil ang mga yunit na pinili para sa survey ay madalas na nawasak, ang mga rate para sa pagpili ng mga yunit sa sample ay dapat na pinakamainam. Ang pinakamainam na laki ng sample ay maaaring makuha mula sa mga formula ng sample na error.
Talahanayan 8.4
Mga formula para sa pagtukoy ng pinakamainam na laki ng sample
|
Paraan ng pagpili |
Para sa medium |
|
|
Naulit ang hindi sinasadyang sarili |
|
|
|
Random at mekanikal na hindi nauulit |
|
|
|
Typological na hindi nauulit |
|
|
|
Serial na hindi nauulit na may pantay na laki ng serye |
|
|








Ang mga formula ay nagpapakita na sa pagtaas ng tinantyang sampling error, ang kinakailangang laki ng sample ay bumababa nang malaki.
Upang kalkulahin ang laki ng sample, kailangan mong malaman ang pagkakaiba. Maaari itong hiramin mula sa mga nakaraang survey nito o isang katulad na populasyon, o isang espesyal na sample na survey ng isang maliit na dami ay maaaring isagawa.
Halimbawa 2 : Sa enterprise, 100 manggagawa sa 1000 ang kinapanayam sa pagkakasunud-sunod ng isang random, hindi nauulit na sample at ang mga sumusunod na data sa kanilang kita para sa Oktubre ay nakuha (Talahanayan 8.5).
Talahanayan 8.5
Pamamahagi ng mga manggagawa ayon sa average na buwanang kita
tukuyin:
1) ang average na buwanang kita ng mga empleyado ng ibinigay na negosyo, na ginagarantiyahan ang resulta na may posibilidad na 0.997;
2) ang bahagi ng mga manggagawa ng negosyo na may buwanang kita na 19 libong rubles. at mas mataas, ginagarantiyahan ang resulta na may posibilidad na 0.954;
3) ang kinakailangang laki ng sample kapag tinutukoy ang average na buwanang kita ng mga empleyado ng negosyo, upang may posibilidad na 0.954 ang marginal sampling error ay hindi lalampas sa 200 rubles.
Solusyon:
1) Tukuyin ang average na buwanang kita ng mga empleyado ng ibinigay na negosyo, ginagarantiyahan ang resulta na may posibilidad na 0.997.
|
n= 100 tao N= 1000 tao |
Solusyon: upang matukoy ang pagitan ng average na buwanang kita ng mga empleyado ng isang naibigay na negosyo sa pangkalahatang populasyon, kinakailangang malaman ang halaga ng marginal sampling error Dahil P = 0.997, kung gayon (ayon sa Talahanayan 8.2) t= 3. Isang random na hindi paulit-ulit na pagpili ang ginawa, ayon sa talahanayan. 8.3 pumipili kami ng formula para sa pagkalkula ng average na sampling error para sa mean:
Ang laki ng average na buwanang kita ng mga manggagawa ayon sa sample na survey ay tinutukoy ng formula ng arithmetic weighted average: Magsasagawa kami ng mga karagdagang kalkulasyon sa sumusunod na talahanayan:
Alam t at libo. kuskusin. Kung gayon ang agwat ng average na buwanang kita ng mga manggagawa ng negosyong ito ay ang mga sumusunod:
|
 at ang laki ng average na buwanang kita ng mga manggagawa ayon sa sample survey data
at ang laki ng average na buwanang kita ng mga manggagawa ayon sa sample survey data  .
. t at mean sampling error
t at mean sampling error  .
. , saan
, saan  - pagkakaiba para sa sample.
- pagkakaiba para sa sample. .
.



 libong rubles.
libong rubles.
 libong rubles.
libong rubles. tukuyin ang halaga ng marginal sampling error:
tukuyin ang halaga ng marginal sampling error: ;
; .
.Sagot: ang average na buwanang kita ng mga empleyado ng negosyong ito na may posibilidad na 0.997 ay nasa hanay na 18.08 libong rubles. hanggang sa 18.92 libong rubles.
2) Tukuyin ang bahagi ng mga manggagawa ng negosyo na may buwanang kita na 19 libong rubles. at mas mataas, na ginagarantiyahan ang isang resulta na may posibilidad na 0.954.
|
n= 100 tao N= 1000 tao
|
Solusyon: upang matukoy ang agwat para sa proporsyon ng mga manggagawa na may buwanang kita na 19 libong rubles. at sa itaas, kinakailangang malaman ang halaga ng marginal error ng pag-sample ng bahagi Ang marginal sampling error ay tinutukoy ng formula Dahil P = 0.954, kung gayon (ayon sa Talahanayan 8.2) t= 2. Isang random na hindi paulit-ulit na pagpili ang ginawa, ayon sa talahanayan. 8.3 pumipili kami ng formula para sa pagkalkula ng average na sampling error para sa isang bahagi:
Ang sample na bahagi ay tinutukoy ng ratio ng bilang ng mga yunit na may pinag-aralan na katangian m sa kabuuang bilang ng mga yunit ng sample n, o Kung gayon ang average na error sa fraction ay Alam t at tukuyin ang halaga ng marginal sampling error para sa bahagi: Pagkatapos ang pagitan ng bahagi ng mga manggagawa na may buwanang kita na 19 libong rubles. at mas mataas sa pangkalahatang populasyon ay ang mga sumusunod:
|

 at ang bahagi ng mga manggagawa na may ganoong average na buwanang kita ayon sa sample W.
at ang bahagi ng mga manggagawa na may ganoong average na buwanang kita ayon sa sample W. ... Depende ito sa halaga ng coefficient of confidence t at mean sampling error.
... Depende ito sa halaga ng coefficient of confidence t at mean sampling error. , saan W- ang bahagi ng mga manggagawa ng negosyo na may average na buwanang kita na 19 libong rubles. at mas mataas sa sample.
, saan W- ang bahagi ng mga manggagawa ng negosyo na may average na buwanang kita na 19 libong rubles. at mas mataas sa sample. .
. .
.Sagot: ang bahagi ng mga manggagawa ng negosyo na may buwanang kita na 19 libong rubles. at mas mataas, na may posibilidad na 0.954, ito ay nasa hanay mula 19.4% hanggang 36.6%.
Tukuyin natin ang kinakailangang laki ng sample kapag tinutukoy ang average na buwanang kita ng mga empleyado ng negosyo upang may posibilidad na 0.954 ang marginal sampling error ay hindi lalampas sa 200 rubles.
|
N= 1000 tao |
Solusyon: ang kinakailangang laki ng sample upang matukoy ang average na buwanang kita ay tinutukoy ng formula (ayon sa talahanayan 8.4): Sa pamamagitan ng kondisyon ng problema, ito ay kilala: para sa posibilidad na P = 0.954 t= 2 (tingnan ang talahanayan 8.2); 0.2 libong rubles;
|
 (ayon sa data ng nakaraang sample).
(ayon sa data ng nakaraang sample). mga tao
mga taoSagot: upang ang marginal sampling error ay hindi lalampas sa 200 rubles na may posibilidad na 0.954, 189 na tao ang dapat suriin.
4.5. Pagpapasiya ng laki ng sample
Kasama sa pamamaraan ng sampling plan pare-parehong solusyon sa sumusunod na tatlong gawain:
Pagpapasiya ng object ng pananaliksik;
Pagpapasiya ng sample na istraktura;
Pagpapasiya ng laki ng sample.
kadalasan, bagay ng pananaliksik sa marketing ay isang koleksyon ng mga bagay ng pagmamasid, na maaaring maging mga mamimili, empleyado ng kumpanya, tagapamagitan, atbp. Kung ang populasyon na ito ay napakaliit na ang pangkat ng pananaliksik ay may kinakailangang paggawa, pananalapi at oras na mga pagkakataon upang maitaguyod ang pakikipag-ugnay sa bawat isa sa mga elemento nito, kung gayon posible na magsagawa ng patuloy na pag-aaral ng buong populasyon. Sa kasong ito, na natukoy ang object ng pananaliksik, maaari kang magpatuloy sa sumusunod na pamamaraan (ang pagpili ng paraan ng pagkolekta ng data, tool sa pananaliksik at paraan ng komunikasyon sa madla).
Gayunpaman, sa pagsasagawa, madalas na hindi posible o ipinapayong magsagawa ng patuloy na pag-aaral ng buong populasyon. Maaaring may mga sumusunod na dahilan para dito:
Ang kawalan ng kakayahang magtatag ng pakikipag-ugnay sa ilang mga elemento ng pinagsama-samang;
Hindi makatwirang mataas na gastos para sa pagsasagawa ng patuloy na pag-aaral o pagkakaroon ng mga paghihigpit sa pananalapi na hindi nagpapahintulot sa pagsasagawa ng patuloy na pag-aaral;
Ang maikling oras na inilaan para sa pag-aaral, dahil sa pagkawala sa paglipas ng panahon ng kaugnayan ng impormasyon o iba pang mga dahilan, at hindi pinapayagan ang koleksyon, sistematisasyon at pagsusuri ng malawak na data para sa buong populasyon.
Samakatuwid, ang malaki at dispersed na mga populasyon ay madalas na pinag-aaralan gamit ang isang sample, na kilala bilang isang bahagi ng populasyon na idinisenyo upang kumatawan sa populasyon sa kabuuan.
Ang katumpakan kung saan ang isang sample ay sumasalamin sa populasyon sa kabuuan ay nakasalalay istraktura at laki ng sample.
Mayroong dalawang mga diskarte sa sample na disenyo- probabilistiko at deterministiko.
Probabilistic na diskarte sa sample na disenyo Ipinapalagay na ang anumang elemento ng populasyon ay maaaring mapili na may tiyak (hindi zero) na posibilidad. Mayroong iba't ibang uri ng mga sample batay sa probability theory (typical, nested, atbp.). Ang pinakasimple at pinakakaraniwan sa pagsasanay ay ang simpleng random sampling, kung saan ang bawat elemento ng populasyon ay may pantay na posibilidad na mapili para sa pananaliksik.
Ang probability sampling ay mas tumpak, pinapayagan nito ang mananaliksik na masuri ang antas ng pagiging maaasahan ng data na kanyang nakolekta, bagaman ito ay mas kumplikado at mas mahal kaysa sa deterministiko.
Deterministikong diskarte sa sample na istraktura Ipinapalagay na ang pagpili ng mga elemento ng populasyon ay ginawa sa pamamagitan ng mga pamamaraan batay sa alinman sa mga pagsasaalang-alang sa kaginhawahan, o sa desisyon ng mananaliksik, o sa mga grupong magkakaugnay.
para sa kaginhawaan, ay binubuo sa pagpili ng anumang mga elemento ng set batay sa kadalian ng pagtatatag ng pakikipag-ugnay sa kanila. Ang di-kasakdalan ng pamamaraang ito ay dahil, marahil, sa mababang representasyon ng nakuhang sample, dahil Ang mga elemento ng pinagsama-samang maginhawa para sa mananaliksik ay maaaring hindi sapat na katangian ng mga kinatawan ng pinagsama-samang dahil sa kanilang hindi random at hindi makatarungang pagpili.
Gayunpaman, sa kabilang banda, ang pagiging simple, pagiging epektibo sa gastos at kahusayan ng pananaliksik na isinagawa ng pamamaraang ito ay napanalunan ito nang laganap sa pagsasanay at, higit sa lahat, sa panahon ng paunang pananaliksik na naglalayong linawin ang mga pangunahing problema.
Batay sa paraan ng sampling sa desisyon ng mananaliksik, ay binubuo sa pagpili ng mga elemento ng set, na, sa kanyang opinyon, ay ang mga kinatawan ng katangian nito. Ang pamamaraang ito ay mas perpekto kaysa sa nauna, dahil nakabatay ito sa isang oryentasyon patungo sa mga katangiang kinatawan ng pinag-aralan na populasyon, bagaman napili sila batay sa mga pansariling ideya ng mga mananaliksik tungkol dito.
Paraan ng sampling batay sa contingent rates, ay binubuo sa pagpili ng mga elemento ng katangian ng set alinsunod sa mga naunang nakuha na katangian ng set sa kabuuan. Ang mga katangiang ito ay maaaring makuha sa pamamagitan ng paunang pananaliksik at, hindi katulad ng naunang pamamaraan, ay hindi subjective. Samakatuwid, ang pamamaraang ito ay mas perpekto, pinapayagan ka nitong makakuha ng mga sample na frame na hindi gaanong kinatawan kaysa sa mga probabilistikong sample sa isang mas mababang halaga ng pagsasagawa ng isang survey.
Ang pagkakaroon ng napiling istraktura ng sample (ang diskarte sa pagbuo nito, ang uri ng probabilistic o pag-iisip tungkol sa pagbuo ng isang deterministic sample), ang mananaliksik ay kailangang matukoy ang dami, i.e. ang bilang ng mga elemento sa sample.
Laki ng sample tinutukoy ang pagiging maaasahan ng impormasyon, nakuha bilang resulta ng pagsasaliksik nito, gayundin ang mga gastos na kinakailangan para sa pagsasagawa ng pananaliksik. Depende ang laki ng sample sa antas ng homogeneity o pagkakaiba-iba ng mga pinag-aralan na bagay.
Kung mas malaki ang sukat ng sample, mas mataas ang katumpakan nito at mas malaki ang gastos sa pagsasagawa ng survey nito. Sa isang probabilistikong diskarte sa istraktura ng sample, ang laki nito ay maaaring matukoy gamit ang mga kilalang istatistikal na formula, batay sa tinukoy na mga kinakailangan para sa katumpakan nito.
Sa pagsasagawa, maraming mga diskarte ang ginagamit upang matukoy ang laki ng sample:
1. Arbitrary na diskarte batay sa paglalapat ng "rule of the thumb". Halimbawa, ipinapalagay na walang ebidensya na ang sample ay dapat na 5% ng populasyon upang makakuha ng tumpak na mga resulta. Ang diskarte na ito ay simple at madaling ipatupad, ngunit hindi posible na maitatag ang katumpakan ng mga resulta na nakuha. Sa sapat na malaking populasyon, maaari rin itong maging medyo mahal.
Maaaring itakda ang laki ng sample batay sa ilang paunang napagkasunduang kundisyon. Halimbawa, alam ng isang customer ng isang pananaliksik sa marketing na kapag nag-aaral ng opinyon ng publiko, ang sample ay karaniwang 1000-1200 tao, kaya inirerekomenda niya na sumunod ang mananaliksik sa figure na ito. Kung ang taunang mga survey ay isinasagawa sa isang tiyak na merkado, kung gayon ang isang sample ng parehong laki ay ginagamit sa bawat taon. Sa kaibahan sa unang diskarte, dito, sa pagtukoy ng laki ng sample, isang kilalang lohika ang ginagamit, na, gayunpaman, ay lubhang mahina.
Halimbawa, ang pagsasagawa ng ilang partikular na pag-aaral ay maaaring mangailangan ng mas kaunting katumpakan kaysa kapag nag-aaral ng pampublikong opinyon, at ang laki ng populasyon ay maaaring maraming beses na mas maliit kaysa kapag nag-aaral ng pampublikong opinyon. Kaya, ang diskarteng ito ay hindi isinasaalang-alang ang mga kasalukuyang pangyayari at maaaring maging medyo mahal.
Sa ilang mga kaso, ang halaga ng survey ay ginagamit bilang pangunahing argumento sa pagtukoy ng laki ng sample. Kaya, ang badyet ng pananaliksik sa marketing ay nagbibigay para sa mga gastos ng ilang mga survey, na hindi dapat lumampas. Malinaw, ang halaga ng impormasyong natanggap ay hindi isinasaalang-alang. Gayunpaman, sa ilang mga kaso, kahit na ang isang maliit na sample ay maaaring magbigay ng medyo tumpak na mga resulta.
Mukhang maingat na isaalang-alang ang mga gastos hindi sa ganap na mga termino, ngunit may kaugnayan sa pagiging kapaki-pakinabang ng impormasyong nakuha mula sa mga survey. Dapat isaalang-alang ng kliyente at ng mananaliksik ang iba't ibang laki ng sample at pamamaraan ng pagkolekta ng data, mga gastos, isinasaalang-alang ang iba pang mga kadahilanan
2. Ang laki ng sample mula sa antas ng agwat ng kumpiyansa ng tinatanggap na error, na, gaya ng nabanggit na, ay itinakda ng naaangkop na katumpakan ng mga huling paglalahat: mula sa tumaas hanggang sa tinatayang. Gayunpaman, dito namin ibig sabihin ang tinatawag na random na mga error na nauugnay sa likas na katangian ng anumang mga statistical error. Ang mga ito ay kinakalkula bilang mga pagkakamali ng pagiging kinatawan ng mga sample ng probabilidad.
Ibinibigay ng V. I. Paniotto ang mga sumusunod na kalkulasyon ng isang kinatawan na sample na may 5% error (Talahanayan 4.2).
Talahanayan 4.2
Halimbawang talahanayan ng pagkalkula
Para sa populasyon na higit sa 100,000, ang sample ay 400 units. Kung nasa isip natin ang pangkalahatang populasyon na 5 libo at higit pa, kung gayon, ayon sa mga kalkulasyon ng parehong may-akda, posibleng ipahiwatig ang laki ng aktwal na error sa pag-sample depende sa laki nito, na napakahalaga para sa atin, na may kinalaman sa isipin na ang laki ng pinahihintulutang error ay nakasalalay sa layunin ng pananaliksik at hindi kailangang malapit sa 5 porsiyentong antas.
Talahanayan 4.3
Talahanayan ng pagkalkula
Kasama ng mga random na error, posible ang mga sistematikong error. Nakadepende sila sa organisasyon ng sample na survey. Ito ay iba't ibang mga offset ng sample patungo sa isa sa mga pole ng sample na parameter.
3. Sukat ng sample batay sa pagsusuri sa istatistika ... Ang diskarte na ito ay batay sa pagtukoy ng pinakamababang laki ng sample batay sa ilang mga kinakailangan para sa pagiging maaasahan at bisa ng mga resultang nakuha. Ginagamit din ito upang pag-aralan ang mga resultang nakuha para sa mga indibidwal na subgroup na nabuo sa sample ayon sa kasarian, edad, antas ng edukasyon, atbp. Ang mga kinakailangan para sa pagiging maaasahan at katumpakan ng mga resulta para sa mga indibidwal na subgroup ay nagdidikta ng ilang mga kinakailangan para sa laki ng sample sa kabuuan.
Ang pinaka-teoretikal na pinagbabatayan at tamang diskarte sa pagtukoy ng laki ng sample ay batay sa pagkalkula ng maaasahang mga pagitan. Inilalarawan ng konsepto ng variation ang dami ng dissimilarity (similarity) ng mga sagot ng mga respondent sa isang partikular na tanong. Mas mahigpit, ang pagkakaiba-iba sa mga halaga ng isang tampok sa isang set ay ang pagkakaiba sa mga halaga nito para sa iba't ibang mga yunit ng isang naibigay na set sa parehong panahon o sandali ng oras. Ang mga resulta ng mga sagot sa mga tanong sa survey ay karaniwang ipinakita sa anyo ng isang kurba ng pamamahagi (Larawan 4.1). Sa mataas na pagkakapareho ng mga sagot, ang isa ay nagsasalita ng isang maliit na pagkakaiba-iba (makitid na kurba ng pamamahagi) at may mababang pagkakapareho ng mga sagot, isang mataas na pagkakaiba-iba (malawak na kurba ng pamamahagi).
Bilang sukatan ng pagkakaiba-iba, karaniwang kinukuha ang karaniwang paglihis, na nagpapakilala sa average na distansya mula sa average na pagtatasa ng mga sagot ng bawat respondent sa isang tiyak na tanong.

Maliit na pagkakaiba-iba
Mataas na pagkakaiba-iba
kanin. 4.1. Variation at distribution curves
Dahil ang lahat ng mga desisyon sa marketing ay ginawa sa mga kondisyon ng kawalan ng katiyakan, ipinapayong isaalang-alang ang sitwasyong ito kapag tinutukoy ang laki ng sample. Dahil ang pagpapasiya ng mga pinag-aralan na halaga para sa isang populasyon sa isang makitid ay isinasagawa sa batayan ng mga sample na istatistika, kinakailangan upang maitatag ang hanay (confidence interval), kung saan ang mga pagtatantya para sa populasyon sa kabuuan ay inaasahan. mahulog, at ang pagkakamali sa kanilang pagpapasiya.
Ang agwat ng kumpiyansa ay isang hanay, ang mga matinding punto na tumutugma sa isang tiyak na porsyento ng ilang mga sagot sa isang tanong. Ang pagitan ng kumpiyansa ay malapit na nauugnay sa karaniwang paglihis ng pinag-aralan na katangian sa pangkalahatang populasyon: kung mas malaki ito, mas malawak ang agwat ng kumpiyansa upang maisama ang isang tiyak na porsyento ng mga tugon.
Ang agwat ng kumpiyansa na alinman sa 95% o 99% ay pamantayan sa pananaliksik sa marketing. Walang kompanya ang nagsasagawa ng pananaliksik sa marketing gamit ang maraming sample. At ginagawang posible ng mga istatistika ng matematika na makakuha ng ilang impormasyon tungkol sa pamamahagi ng sample, na mayroong data lamang sa pagkakaiba-iba ng isang sample.
Ang isang tagapagpahiwatig ng antas kung saan ang pagtatantya na totoo para sa populasyon sa kabuuan ay naiiba sa pagtatantya na inaasahan para sa isang karaniwang sample ay ang root-mean-square error. Bukod dito, mas malaki ang laki ng sample, mas maliit ang error. Ang mataas na halaga ng variation ay nagreresulta sa mataas na halaga ng error at vice versa.
Kapag mayroon lamang dalawang posibleng sagot sa isang tanong, na ipinahayag bilang isang porsyento (porsiyento ang ginagamit), ang laki ng sample ay tinutukoy ng sumusunod na formula:

kung saan ang n ay ang sample size; z - normalized deviation, tinutukoy batay sa napiling antas ng kumpiyansa; p ay ang natagpuang pagkakaiba-iba para sa sample; g - (100-p); e ay isang katanggap-tanggap na error.
Kapag tinutukoy ang tagapagpahiwatig ng pagkakaiba-iba para sa isang tiyak na populasyon, una sa lahat ay ipinapayong magsagawa ng isang paunang pagsusuri ng husay ng pinag-aralan na populasyon, una sa lahat, upang maitaguyod ang pagkakapareho ng mga yunit ng populasyon sa demograpiko, panlipunan at iba pang mga paggalang na ay interesado sa mananaliksik. Posibleng magsagawa ng pilot study, gamitin ang mga resulta ng mga katulad na pag-aaral na isinagawa noong nakaraan. Kapag ginagamit ang sukat ng porsyento ng pagkakaiba-iba, isinasaalang-alang na ang pinakamataas na pagkakaiba-iba ay nakakamit para sa p = 50%, na siyang pinakamasamang kaso. Bukod dito, ang tagapagpahiwatig na ito ay hindi radikal na nakakaapekto sa laki ng sample. Ang opinyon ng customer ng pag-aaral sa laki ng sample ay isinasaalang-alang din.
Posibleng matukoy ang laki ng sample batay sa paggamit ng mga average sa halip na mga porsyento.

kung saan ang s ay ang standard deviation.
Sa pagsasagawa, kung muling nabuo ang sample at hindi pa naisagawa ang mga katulad na survey, hindi alam ang s. Sa kasong ito, ipinapayong itakda ang error e sa mga fraction ng standard deviation. Ang formula ng pagkalkula ay binago at kinuha ang sumusunod na anyo:
 saan
saan  .
.
Sa itaas, napag-usapan namin ang tungkol sa napakalaking pinagsama-sama. Gayunpaman, sa ilang mga kaso, ang populasyon ay hindi malaki. Karaniwan, kung ang sample ay mas mababa sa limang porsyento ng populasyon, kung gayon ang populasyon ay itinuturing na malaki at ang mga kalkulasyon ay ginawa ayon sa mga panuntunan sa itaas. Kung ang laki ng sample ay lumampas sa 5% ng populasyon, kung gayon ang huli ay itinuturing na maliit at isang kadahilanan ng pagwawasto ay ipinakilala sa mga formula sa itaas.
Ang laki ng sample sa kasong ito ay tinutukoy bilang mga sumusunod:
 ,
,
Praktikal na gawain Blg. 8. "Pagpapasiya ng kinakailangang laki ng sample"
"Pagpapasiya ng kinakailangang laki ng sample"
Ang pinakalaganap na uri ng hindi tuloy-tuloy na pagmamasid ay ang selective observation, kung saan hindi lahat ng unit ng pinag-aralan na populasyon ay sinusuri, ngunit isang bahagi lamang ng mga ito ang napili sa isang tiyak na paraan.
Ang buong hanay ng mga bagay (obserbasyon) na pag-aaralan ay tinatawag pangkalahatang populasyon. Sampol na populasyon o sample ay ang bahagi ng pangkalahatang populasyon na pinili para sa pag-aaral ng mga ari-arian na nagbibigay ng representasyon.
Ang pagpili mula sa pangkalahatang populasyon ay isinasagawa sa paraang, sa batayan ng sample, ang isang sapat na tumpak na ideya ng mga pangunahing parameter ng populasyon sa kabuuan ay maaaring makuha. Sa kasong ito, pinag-uusapan natin ang parehong pagtatantya ng punto, na kinukuha bilang katumbas na halaga ng average, bahagi, atbp., na nakuha bilang resulta ng sample, at tungkol sa pagtatantya ng pagitan, i.e. tungkol sa mga limitasyon kung saan, na may tiyak na posibilidad, ang halaga ng nais na parameter sa pangkalahatang populasyon ay maaaring. Ang pangunahing kinakailangan na dapat matugunan ng isang sample na populasyon ay ang kinakailangan para sa pagiging kinatawan nito, i.e. pagiging kinatawan.
Sa mga istatistika, ang mga resulta ng tuluy-tuloy na pagmamasid ay minsan sinusuri bilang mga sample na katangian. Ang interpretasyong ito ng data na nakuha ay nagaganap sa mga kaso kung saan ang bilang ng mga nasuri na yunit ay maliit at walang matatag na kumpiyansa na ang mga pinag-aralan na katangian ay hindi maaaring kumuha ng mga halaga maliban sa mga natukoy bilang resulta ng pagmamasid. Kapag nagsasagawa ng mga eksperimento, ang bilang ng mga halaga ay maaaring walang hanggan na malaki, samakatuwid, ang pagbabalangkas ng mga konklusyon batay sa isang limitadong bilang ng mga ito, kinakailangang isaalang-alang ang data na nakuha bilang mga sample na katangian.
Kapag pinalawak ang mga resulta ng isang sample na survey sa pangkalahatang populasyon, dapat tandaan na maaaring mayroong pagkakaiba sa pagitan ng mga katangian ng pangkalahatang populasyon at sample na populasyon, dahil sa katotohanan na hindi ang buong populasyon ang sinuri, ngunit bahagi lamang nito.
Error sa pagmamasid sa istatistika ang halaga ng paglihis sa pagitan ng kinakalkula at aktwal na mga halaga ng mga tampok ng mga pinag-aralan na bagay ay isinasaalang-alang.
Ang selektibong paraan ay nagbibigay ng makabuluhang pagtitipid sa materyal at pinansiyal na mga mapagkukunan kapag nagsasagawa ng istatistikal na pagmamasid, na ginagawang posible na palawakin ang programa ng survey at dagdagan ang kahusayan nito. Ang pangalawang bentahe ay ang mataas na pagiging maaasahan ng data na nakuha, dahil sa isang medyo maliit na sukat ng sample, ang epektibong kontrol sa kalidad ng impormasyong nakolekta ay maaaring maisaayos. Kaya, ang posibilidad ng mga error sa pagpaparehistro at ang kanilang hindi pagtuklas sa yugto ng pagsuri sa pangunahing impormasyon ay nabawasan. At sa wakas, sa ilang mga kaso, kapag ang tuluy-tuloy na pagsubaybay ay nauugnay sa pagkasira o pinsala sa mga na-survey na yunit (halimbawa, kapag sinusuri ang kalidad ng mga produktong pagkain na ibinebenta), isang sample na survey lamang ang posible.
Ang katumpakan ng mga pagtatantya na nakuha sa batayan ng paraan ng sampling ay hindi nakasalalay sa proporsyon ng mga yunit na sinuri, ngunit sa kanilang bilang.
Ang mga pangunahing yugto ng pumipili na pagmamasid;
1) pagtukoy sa layunin, layunin at pagbubuo ng isang programa sa pagsubaybay;
2) sampling;
3) pangongolekta ng datos batay sa binuong programa;
4) pagsusuri ng mga resulta na nakuha at pagkalkula ng mga pangunahing katangian ng sample na populasyon;
5) pagkalkula ng error sa sampling at ang pamamahagi ng mga resulta nito sa pangkalahatang populasyon.
Makilala mga uri ng sampling:
1) random(talagang random);
2) mekanikal(halimbawa, tuwing 10, 20, atbp.);
3) tipikal (pinagsasapin-sapin), kapag ang pangkalahatang populasyon ay nahahati sa mga grupo at ilang mga bagay ang sinusuri sa bawat pangkat));
4) serye (pugad) kapag ang buong serye ay random na pinili.
Ang pinakasimpleng paraan upang bumuo ng sample ay wastong random na pagpili. Ang mga teoretikal na pundasyon ng pamamaraan ng sampling, na orihinal na binuo kaugnay ng wastong random sampling, ay ginagamit din upang matukoy ang mga error sa sampling para sa iba pang mga paraan ng pagmamasid.
Ang tunay na random na pagpili ay maaaring ulitin at hindi paulit-ulit. Sa paulit-ulit Sa pamamagitan ng pagpili, ang bawat yunit, na pinili nang random mula sa pangkalahatang populasyon, pagkatapos ng pagmamasid, ay babalik sa populasyon na ito at maaaring muling suriin. Sa pagsasagawa, ang paraan ng pagpili na ito ay bihira. Ang mas karaniwan ay talagang random hindi nauulit pagpili kung saan ang mga na-survey na yunit ay hindi babalik sa pangkalahatang populasyon at hindi na muling masusuri. Kapag muling nagsa-sample, ang posibilidad na ma-sample para sa bawat yunit ng populasyon ay nananatiling hindi nagbabago. Kapag nagsa-sample nang walang pag-uulit, nagbabago ito, ngunit para sa lahat ng mga yunit na natitira sa pangkalahatang populasyon pagkatapos pumili ng ilang mga yunit mula dito, ang posibilidad na maisama sa sample ay pareho.
Ang mga populasyon ay madalas na gaganapin sa malalaking grupo ng mga tao. Kadalasan ay isang maling kuru-kuro na ang pagiging maaasahan ng mga resulta ay magiging mas mataas kung sasagutin ng bawat miyembro ng lipunan ang mga tanong. Dahil sa malaking oras, pera at lakas ng paggawa, hindi katanggap-tanggap ang naturang survey. Habang lumalaki ang bilang ng mga sumasagot, hindi lamang tataas ang mga gastos, ngunit tataas din ang panganib na makatanggap ng maling data. Mula sa praktikal na pananaw, maraming questionnaire at coder ang magbabawas sa posibilidad ng maaasahang pagsubaybay sa kanilang mga aksyon. Ang nasabing survey ay tinatawag na tuloy-tuloy.
Sa sosyolohiya, ang hindi tuloy-tuloy na pananaliksik, o ang paraan ng sampling, ay kadalasang ginagamit. Ang mga resulta nito ay maaaring pahabain sa isang malaking grupo ng mga tao, na tinatawag na pangkalahatan.
Kahulugan at kahalagahan ng sampling
Ang sampling method ay isang quantitative na paraan ng pagpili ng bahagi ng pinag-aralan na unit mula sa kabuuang masa, habang ang mga resulta ng survey ay ilalapat din sa bawat indibidwal na hindi nakibahagi dito.
Ang piling pamamaraan ay parehong paksa ng siyentipikong pananaliksik at isang akademikong disiplina. Ito ay gumaganap bilang isang paraan ng pagkuha ng maaasahang impormasyon tungkol sa pangkalahatang populasyon at tumutulong upang masuri ang lahat ng mga parameter nito. Ang mga kondisyon para sa pagpili ng mga yunit ay kasunod na nakakaimpluwensya sa istatistikal na pagsusuri ng mga resulta. Kung ang mga piling pamamaraan ay ginanap nang hindi maganda, ang paggamit ng kahit na ang pinaka-maaasahang paraan ng pagproseso ng nakolektang impormasyon ay magiging walang silbi.

Mga pangunahing konsepto ng teorya ng pagpili
Ang interrelation ng mga yunit ay tinatawag, na may kaugnayan sa kung saan ang mga konklusyon ng sample na pag-aaral ay nabuo. Maaari itong maging mga residente ng isang bansa, isang tiyak na kasunduan, ang kolektibong gawain ng isang negosyo, atbp.
Ang sample na populasyon (o sample) ay isang bahagi ng pangkalahatang populasyon, na pinili gamit ang mga espesyal na pamamaraan at pamantayan. Halimbawa, sa proseso ng pagbuo, ang mga pamantayan sa istatistika ay isinasaalang-alang.
Ang bilang ng mga indibidwal na kasama sa isang partikular na hanay ay tinatawag na dami nito. Ngunit ito ay maaaring ipahayag hindi lamang sa pamamagitan ng bilang ng mga tao, kundi pati na rin ng mga istasyon ng botohan, mga pamayanan, iyon ay, tiyak ng malalaking yunit na kinabibilangan ng mga yunit ng pagmamasid. Ngunit isa na itong multistage sampling.
Ang yunit ng pagpili ay ang mga bumubuong bahagi ng pangkalahatang populasyon; maaari silang maging direkta sa mga yunit ng pagmamasid (one-stage sampling), o mas malalaking pormasyon.
Ang isang mahalagang papel sa pagkuha ng maaasahang mga resulta ng pananaliksik gamit ang paraan ng sampling ay isang katangian bilang ang pagiging kinatawan ng pagpili. Ibig sabihin, ang bahagi ng pangkalahatang populasyon na naging mga tumutugon ay dapat na ganap na magparami ng lahat ng mga katangian nito. Ang anumang paglihis ay itinuturing na isang error.

Mga yugto ng paglalapat ng paraan ng sampling
Ang bawat empirical ay binubuo ng mga yugto. Sa kaso ng paggamit ng paraan ng pag-sample, ang kanilang pagkakasunud-sunod ay gagawin tulad ng sumusunod:
- Paglikha ng isang sample na proyekto: ang pangkalahatang populasyon ay itinatag, mga pamamaraan ng pagpili, mga volume ay nailalarawan.
- Pagpapatupad ng proyekto: sa kurso ng pagkolekta ng sosyolohikal na impormasyon, ang mga talatanungan ay nagsasagawa ng mga gawain na may indikasyon ng paraan ng pagpili ng mga sumasagot.
- Pagkilala at pagwawasto ng mga pagkakamali sa representasyon.
Mga halimbawang uri sa sosyolohiya
Matapos matukoy ang pangkalahatang populasyon, ang mananaliksik ay nagpapatuloy sa mga piling pamamaraan. Maaari silang hatiin ayon sa dalawang uri (pamantayan):
- Ang papel ng mga probabilistikong batas sa sampling.
- Ang bilang ng mga yugto ng pagpili.
Kung ang unang criterion ay inilapat, pagkatapos ay ang paraan ng random sampling at hindi random na pagpili ay nakikilala. Batay sa huli, maaaring pagtalunan na ang sample ay maaaring single-stage o multi-stage.
Ang mga uri ng mga sample ay direktang makikita hindi lamang sa mga yugto ng paghahanda at pagsasagawa ng pag-aaral, kundi pati na rin sa mga resulta nito. Bago bigyan ng kagustuhan ang isa sa mga ito, dapat mong maunawaan ang nilalaman ng mga konsepto.
Ang kahulugan ng "random" sa pang-araw-araw na paggamit ay nakatanggap ng ganap na kabaligtaran na kahulugan kaysa sa matematika. Ang ganitong pagpili ay isinasagawa ayon sa mahigpit na mga patakaran, walang paglihis mula sa kanila ang pinapayagan, dahil mahalagang tiyakin na ang bawat yunit ng pangkalahatang populasyon ay may parehong pagkakataon na maisama sa sample. Kung hindi matugunan ang mga kundisyong ito, mag-iiba ang posibilidad na ito.
Sa turn, ang random na sample ay nahahati sa:
- simple;
- mekanikal (sistematiko);
- nested (serial, cluster);
- stratified (karaniwan o regionalized).
Ang isang simpleng paraan ng sampling ay isinasagawa gamit ang isang talahanayan ng mga random na numero. Ang laki ng sample ay tinutukoy sa simula; isang kumpletong listahan ng mga may bilang na respondent mula sa pangkalahatang populasyon ay nilikha. Ginagamit para sa pagpili ang mga espesyal na talahanayan na nakapaloob sa mga publikasyong pangmatematika at istatistika. Ang anumang bagay maliban sa kanila ay ipinagbabawal na gamitin. Kung ang laki ng sample ay isang tatlong-digit na numero, ang bilang ng bawat sampling unit ay dapat na tatlong-digit, ibig sabihin: mula 001 hanggang 790. Ang huling numero ay tumutukoy sa kabuuang bilang ng mga tao. Isasama sa pag-aaral ang mga taong nabigyan ng numero sa tinukoy na hanay na makikita sa talahanayan.

Ang sistematikong pagpili ay batay sa mga kalkulasyon. Ang isang alpabetikong listahan ng lahat ng mga elemento ng pangkalahatang populasyon ay paunang pinagsama-sama, ang hakbang ay itinakda, at pagkatapos lamang ay ang laki ng sample. Ang formula para sa hakbang ay ipinakita tulad ng sumusunod:
N: n, kung saan ang N ay ang populasyon at n ang sample.
Halimbawa, 150,000: 5,000 = 30. Kaya, bawat tatlumpung tao ay pipiliin na lumahok sa survey.
Nested entity
Ang nest sampling ay ginagamit sa mga kondisyon kung saan ang populasyon ng mga taong pinag-aaralan ay binubuo ng maliliit na natural na grupo sa mga tuntunin ng bilang ng mga natural na grupo. Sa kasong ito, dapat itong isaalang-alang na sa unang hakbang, ang listahan ng numero ng naturang mga pugad ay tinutukoy. Gamit ang isang talahanayan ng mga random na numero, isang pagpili ay ginawa at isang tuluy-tuloy na survey ng lahat ng mga respondent sa bawat napiling pugad ay isinasagawa. Bukod dito, mas marami sa kanila ang nakibahagi sa pag-aaral, mas maliit ang average na error sa sampling. Gayunpaman, posible na gumamit ng gayong pamamaraan kung may katulad na katangian sa mga pinag-aralan na mga pugad.
Ang kakanyahan ng stratified choice
Ang stratified sample ay naiiba sa mga nauna na, sa bisperas ng pagpili, ang pangkalahatang populasyon ay nahahati sa strata, iyon ay, mga homogenous na bahagi na may isang karaniwang tampok. Halimbawa, ang antas ng edukasyon, mga kagustuhan sa elektoral, ang antas ng kasiyahan sa iba't ibang aspeto ng buhay. Ang pinakasimpleng opsyon ay hatiin ang mga paksa ayon sa kasarian at edad. Sa prinsipyo, kinakailangang isagawa ang pagpili sa paraang mula sa bawat stratum ang isang bilang ng mga tao ay inilalaan, proporsyonal sa kabuuang bilang.
Ang laki ng sample sa kasong ito ay maaaring mas maliit kaysa sa sitwasyong may random sampling, ngunit ang pagiging kinatawan ay magiging mas mataas. Dapat aminin na ang isang stratified sample ang magiging pinakamagastos sa mga tuntunin ng pinansyal at impormasyong mapagkukunan, at ang cluster sample ang magiging pinakamakinabang sa bagay na ito.

Non-random na quota sampling
Mayroon ding sample ng quota. Ito ang tanging uri ng hindi random na pagpili na may batayan sa matematika. Ang sample ng quota ay nabuo mula sa mga yunit na dapat ipakita sa mga proporsyon at tumutugma sa pangkalahatang populasyon. Sa ganitong paraan, ang naka-target na pamamahagi ng mga katangian ay isinasagawa. Kung kabilang sa mga pinag-aralan na tampok ay ang mga opinyon at pagtatasa ng mga tao, kung gayon ang mga quota ay kadalasang kasarian, edad, edukasyon ng mga sumasagot.
Sa isang sosyolohikal na pag-aaral, dalawang uri ng pagpili ay nakikilala din: paulit-ulit at hindi paulit-ulit. Sa una, ang napiling yunit pagkatapos ng survey ay babalik sa pangkalahatang populasyon upang higit na makilahok sa pagpili. Sa pangalawang opsyon, pinagbukud-bukod ang mga respondent, na nagpapataas ng pagkakataon na mapili ang natitirang bahagi ng pangkalahatang populasyon.
Binuo ng sosyologong si G.A. Churchill ang sumusunod na panuntunan: ang laki ng sample ay dapat magsikap na magbigay ng hindi bababa sa 100 obserbasyon para sa pangunahin at 20-50 para sa bahagi ng pangalawang pag-uuri. Dapat tandaan na ang ilan sa mga respondent na kasama sa sample, para sa iba't ibang dahilan, ay maaaring hindi makilahok sa survey o tumanggi ito nang buo.

Mga pamamaraan para sa pagtukoy ng laki ng sample
Ang mga sumusunod na pamamaraan ay naaangkop sa sosyolohikal na pananaliksik:
1. Arbitrary, ibig sabihin, ang sample size ay tinutukoy sa loob ng 5-10% ng pangkalahatang populasyon.
2. Ang tradisyonal na paraan ng pagkalkula ay batay sa mga regular na survey, halimbawa, isang beses sa isang taon na may saklaw na 600, 2,000 o 2,500 na mga tumutugon.
3. Statistical - ay upang maitaguyod ang pagiging maaasahan ng impormasyon. Ang mga istatistika bilang isang agham ay hindi bubuo sa paghihiwalay. Ang mga paksa at lugar ng kanyang pananaliksik ay aktibong kasangkot sa iba pang nauugnay na mga industriya: teknikal, pang-ekonomiya at humanitarian. Kaya, ang mga pamamaraan nito ay ginagamit sa sosyolohiya, bilang paghahanda para sa mga survey at, lalo na, sa pagtukoy ng laki ng mga sample. Ang mga istatistika bilang isang agham ay may malawak na baseng pamamaraan.
4. Mahal, kung saan ang pinahihintulutang halaga ng mga gastos sa pananaliksik ay itinatag.
5. Ang laki ng sample ay maaaring katumbas ng bilang ng mga yunit sa pangkalahatang populasyon, kung gayon ang pag-aaral ay magpapatuloy. Ang diskarte na ito ay naaangkop sa maliliit na grupo. Halimbawa, ang mga manggagawa, mga mag-aaral, atbp.
Noong nakaraan, posibleng maitaguyod na ang isang sample ay ituring na kinatawan kapag ang mga katangian nito ay naglalarawan ng mga katangian ng pangkalahatang populasyon na may pinakamababang error.
Ang pagtatantya ng laki ng sample ay nauuna sa panghuling pagkalkula ng bilang ng mga yunit na kukunin mula sa populasyon:
n = Npqt 2: N∆ 2 p + pqt 2, kung saan ang N ay ang bilang ng mga yunit ng pangkalahatang populasyon, p ay ang bahagi ng pinag-aralan na tampok (q = 1 - p), t ay ang koepisyent ng pagsusulatan ng probabilidad ng kumpiyansa P (natukoy ayon sa isang espesyal na talahanayan), ∆ p ay isang wastong error.
Isa lang itong variation kung paano kinakalkula ang laki ng sample. Maaaring magbago ang formula depende sa mga kundisyon at sa napiling pamantayan sa pananaliksik (halimbawa, resampling o hindi resampling).
Mga error sa pag-sample
Ang mga sociological survey ng populasyon ay batay sa paggamit ng isa sa mga uri ng sample na tinalakay natin sa itaas. Gayunpaman, sa anumang kaso, ang gawain ng bawat mananaliksik ay dapat na masuri ang antas ng katumpakan ng mga tagapagpahiwatig na nakuha, iyon ay, kinakailangan upang matukoy kung paano nila ipinapakita ang mga katangian ng pangkalahatang populasyon.
Ang mga error sa pag-sample ay maaaring hatiin sa random at non-random. Ang unang uri ay nagpapahiwatig ng paglihis ng sample indicator mula sa pangkalahatan, na maaaring ipahayag sa pamamagitan ng pagkakaiba sa kanilang mga bahagi (average) at na sanhi lamang ng isang hindi tuloy-tuloy na uri ng survey. At ito ay medyo natural kung ang tagapagpahiwatig na ito ay bumababa laban sa background ng isang pagtaas sa bilang ng mga sumasagot na sinuri.
Ang isang sistematikong error ay isang paglihis mula sa pangkalahatang tagapagpahiwatig, na natagpuan din bilang isang resulta ng pagbabawas ng sample at ang pangkalahatang bahagi at nagmumula sa pagkakaiba sa pagitan ng pamamaraan ng sampling at mga itinatag na panuntunan.
Ang mga uri ng error na ito ay kasama sa pangkalahatang sampling error. Sa isang pag-aaral, isang sample lamang ang maaaring makuha mula sa populasyon. Ang pagkalkula ng maximum na posibleng paglihis ng isang sample indicator ay maaaring isagawa gamit ang isang espesyal na formula. Ito ay tinatawag na marginal sampling error. Mayroon ding isang bagay tulad ng mean sampling error. Ito ang karaniwang paglihis ng sample mula sa pangkalahatang bahagi.
Mayroon ding posterior (post-experience) na uri ng error. Nangangahulugan ito ng paglihis ng mga sample indicator mula sa pangkalahatang bahagi (average). Kinakalkula ito sa pamamagitan ng paghahambing ng pangkalahatang tagapagpahiwatig, impormasyon tungkol sa kung saan nagmula sa mga mapagkakatiwalaang mapagkukunan, at ang sample, na itinatag sa panahon ng survey. Bilang maaasahang mga mapagkukunan ng impormasyon ay madalas na ang mga departamento ng tauhan ng mga negosyo, mga katawan ng istatistika ng estado.
Mayroon ding isang priori error, na kung saan ay din ang paglihis ng sample at pangkalahatang mga tagapagpahiwatig, na maaaring ipahayag sa pamamagitan ng pagkakaiba sa pagitan ng kanilang mga pagbabahagi at kung saan ay maaaring kalkulahin gamit ang isang espesyal na formula.

Sa pananaliksik na pang-edukasyon, ang mga sumusunod na pagkakamali ay kadalasang ginagawa na nauugnay sa pagpili ng mga respondent para sa isang survey:
1. Mga halimbawang hanay ng mga pangkat na kabilang sa iba't ibang pangkalahatang grupo. Kapag ginagamit ang mga ito, nabuo ang mga istatistikal na konklusyon na naaangkop sa buong sample. Malinaw, hindi ito katanggap-tanggap.
2. Ang mga kakayahan sa organisasyon at pananalapi ng mananaliksik ay hindi isinasaalang-alang kapag ang mga uri ng mga sample ay isinasaalang-alang, at isa sa mga ito ay binibigyan ng kagustuhan.
3. Ang istatistikal na pamantayan ng istraktura ng pangkalahatang populasyon ay hindi ganap na ginagamit upang maiwasan ang mga pagkakamali sa sampling.
4. Ang mga pangangailangan ng pagiging kinatawan ng pagpili ng mga respondente sa kurso ng paghahambing na pag-aaral ay hindi isinasaalang-alang.
5. Ang mga tagubilin para sa tagapanayam ay dapat iakma na isinasaalang-alang ang mga detalye ng uri ng pagpili na pinagtibay.
Ang katangian ng partisipasyon ng mga respondente sa pag-aaral ay maaring bukas o anonymous. Dapat itong isaalang-alang sa pagpili ng sample, dahil maaaring mag-drop out ang mga kalahok kung hindi sila sumasang-ayon sa mga tuntunin at kundisyon.
Ang kabuuang bilang ng mga bagay ng pagmamasid (mga tao, sambahayan, negosyo, pamayanan, atbp.) na may isang tiyak na hanay ng mga katangian (kasarian, edad, kita, numero, turnover, atbp.), Limitado sa espasyo at oras. Mga halimbawa ng populasyon
- Lahat ng residente ng Moscow (10.6 milyong tao ayon sa census noong 2002)
- Muscovite men (4.9 milyong tao ayon sa 2002 census)
- Mga legal na entity ng Russia (2.2 milyon sa simula ng 2005)
- Mga retail outlet na nagbebenta ng pagkain (20 thousand sa simula ng 2008), atbp.
Sample (Sample na Populasyon)
Bahagi ng mga bagay mula sa pangkalahatang populasyon na pinili para sa pag-aaral upang makagawa ng konklusyon tungkol sa buong pangkalahatang populasyon. Upang ang konklusyon na nakuha sa pamamagitan ng pagsusuri sa sample ay mapalawak sa buong pangkalahatang populasyon, ang sample ay dapat magkaroon ng pag-aari ng pagiging kinatawan.
Pagkakatawan ng sample
Ang pag-aari ng isang sample upang maipakita nang tama ang pangkalahatang populasyon. Ang parehong sample ay maaaring kinatawan at hindi kinatawan para sa iba't ibang populasyon.
Halimbawa:
- Ang sample na ganap na binubuo ng mga Muscovite na nagmamay-ari ng kotse ay hindi kumakatawan sa buong populasyon ng Moscow.
- Ang sample ng mga negosyong Ruso na may bilang na hanggang 100 katao ay hindi kumakatawan sa lahat ng mga negosyo sa Russia.
- Ang sample ng mga Muscovite na bumibili sa merkado ay hindi kumakatawan sa gawi sa pagbili ng lahat ng Muscovite.
Kasabay nito, ang mga sample na ito (napapailalim sa iba pang mga kundisyon) ay maaaring ganap na kumakatawan sa mga Muscovites-may-ari ng kotse, maliit at katamtamang laki ng mga negosyong Ruso at mga mamimili na bumibili sa mga merkado, ayon sa pagkakabanggit.
Mahalagang maunawaan na ang pagiging kinatawan ng sample at error sa sampling ay magkaibang phenomena. Ang pagiging kinatawan, sa kaibahan sa pagkakamali, ay hindi nakadepende sa anumang paraan sa laki ng sample.
Halimbawa:
Gaano man namin dagdagan ang bilang ng mga na-survey na Muscovites-may-ari ng kotse, hindi namin magagawang katawanin ang lahat ng Muscovite gamit ang sample na ito.
Error sa pag-sample (confidence interval)
Ang paglihis ng mga resulta na nakuha gamit ang selective observation mula sa totoong data ng pangkalahatang populasyon.
Mayroong dalawang uri ng sampling error - istatistika at sistematiko. Ang error sa istatistika ay depende sa laki ng sample. Kung mas malaki ang sample size, mas mababa ito.
Halimbawa:
Para sa isang simpleng random na sample na 400 units, ang maximum na statistical error (na may 95% confidence level) ay 5%, para sa sample na 600 units - 4%, para sa sample na 1100 units - 3% Kadalasan, kapag pinag-uusapan ng mga tao ang tungkol sa error sa sampling, ang ibig nilang sabihin ay ang statistical error ...
Nakadepende ang bias sa iba't ibang salik na may permanenteng epekto sa pag-aaral at pinapakiling ang mga resulta ng pag-aaral sa isang tiyak na direksyon.
Halimbawa:
- Ang paggamit ng anumang probability sample ay minamaliit ang proporsyon ng mga taong may mataas na kita na may aktibong pamumuhay. Nangyayari ito dahil sa ang katunayan na ang mga ganitong tao ay mas mahirap hanapin sa anumang partikular na lugar (halimbawa, sa bahay).
- Ang problema ng mga sumasagot na tumangging sumagot ng mga tanong (ang bahagi ng mga "refuseniks" sa Moscow, para sa iba't ibang mga botohan, ay mula 50% hanggang 80%)
Sa ilang mga kaso, kapag nalaman ang totoong mga distribusyon, maaaring ma-neutralize ang bias sa pamamagitan ng paglalagay ng mga quota o muling pagtimbang sa data, ngunit sa karamihan ng mga tunay na pag-aaral, maaari itong maging medyo may problema kung tantiyahin ito.
Mga uri ng sample
Ang mga sample ay nahahati sa dalawang uri:
- probabilistiko
- hindi malamang
1. Mga sample ng probabilidad
1.1 Random sampling (simple random sampling)
Ipinapalagay ng naturang sample ang homogeneity ng pangkalahatang populasyon, ang parehong posibilidad ng pagkakaroon ng lahat ng mga elemento, ang pagkakaroon ng isang kumpletong listahan ng lahat ng mga elemento. Kapag pumipili ng mga elemento, bilang panuntunan, ginagamit ang isang talahanayan ng mga random na numero.
1.2 Mechanical (systematic) sampling
Isang uri ng random na sample, inayos ayon sa ilang criterion (alphabetical order, numero ng telepono, petsa ng kapanganakan, atbp.). Ang unang elemento ay pinili nang random, pagkatapos, sa mga pagdaragdag ng 'n', ang bawat 'k' na elemento ay pinili. Ang laki ng pangkalahatang populasyon, habang - N = n * k
1.3 Stratified (na-zoned)
Ginagamit ito sa kaso ng heterogeneity ng pangkalahatang populasyon. Ang pangkalahatang populasyon ay nahahati sa mga pangkat (strata). Sa bawat stratum, ang pagpili ay isinasagawa nang random o mekanikal.
1.4 Serial (nested o clustered) sampling
Sa serial sampling, ang mga unit ng pagpili ay hindi ang mga bagay mismo, ngunit mga grupo (mga kumpol o pugad). Ang mga pangkat ay random na pinili. Ang mga bagay sa loob ng mga pangkat ay sinusuri sa solidong anyo.
2 hindi malamang sampling
Ang pagpili sa naturang sample ay isinasagawa hindi ayon sa mga prinsipyo ng randomness, ngunit ayon sa subjective na pamantayan - availability, typicality, pantay na representasyon, atbp.
2.1. quota sampling
Sa una, ang isang tiyak na bilang ng mga grupo ng mga bagay ay inilalaan (halimbawa, mga lalaki na may edad na 20-30 taon, 31-45 taong gulang at 46-60 taong gulang; mga taong may kita na hanggang 30 libong rubles, na may kita na 30 hanggang 60 libong rubles at isang kita na higit sa 60 libong rubles ) Para sa bawat pangkat, ang bilang ng mga bagay na susuriin ay nakatakda. Ang bilang ng mga bagay na dapat mahulog sa bawat isa sa mga pangkat ay nakatakda, kadalasan, alinman sa proporsyon sa dating kilalang bahagi ng pangkat sa pangkalahatang populasyon, o pareho para sa bawat pangkat. Sa loob ng mga pangkat, ang mga bagay ay pinipili nang random. Ang mga sample ng quota ay madalas na ginagamit.
2.2. Paraan ng snowball
Ang sample ay itinayo bilang mga sumusunod. Ang bawat respondente, simula sa una, ay hinihingan ng mga contact ng kanyang mga kaibigan, kasamahan, kakilala na akma sa mga kundisyon sa pagpili at maaaring makilahok sa pag-aaral. Kaya, maliban sa unang hakbang, ang sample ay nabuo na may partisipasyon ng mga bagay sa pananaliksik mismo. Ang pamamaraan ay kadalasang ginagamit kapag kinakailangan upang mahanap at makapanayam ang mga mahirap maabot na grupo ng mga respondent (halimbawa, mga respondent na may mataas na kita, mga respondent na kabilang sa parehong propesyonal na grupo, mga respondent na may katulad na libangan / libangan, atbp.)
2.3 Spontaneous sampling
Ang pinaka-naa-access na mga respondente ay kinapanayam. Ang mga karaniwang halimbawa ng spontaneous sampling ay nasa mga pahayagan / magazine, na ibinibigay sa mga respondent para sa sariling pagkumpleto, karamihan sa mga survey sa Internet. Ang laki at komposisyon ng mga kusang sample ay hindi alam nang maaga, at tinutukoy lamang ng isang parameter - ang aktibidad ng mga sumasagot.
2.4 Sample ng mga tipikal na kaso
Pinipili ang mga yunit ng pangkalahatang populasyon na may average (karaniwang) halaga ng katangian. Pinapataas nito ang problema sa pagpili ng isang tampok at pagtukoy sa karaniwang halaga nito.
Kurso ng mga lektura sa teorya ng istatistika
Ang mas detalyadong impormasyon sa mga sample na obserbasyon ay maaaring makuha sa pamamagitan ng pagtingin.
Pagkalkula ng laki ng sample
Sa lahat ng mga tanong na itinatanong sa mga kawani ng sikat na Gallup Institute for Public Opinion, ang pinakasikat ay ito: paano mo, pagkatapos makapanayam ang 1,000 katao, hatulan kung ano ang iniisip ng 250 milyong Amerikano?
Upang masagot ang tanong na ito, dapat banggitin hindi lamang ang mataas na kwalipikasyon at malawak na praktikal na karanasan ng mga empleyado, kundi pati na rin ang kanilang paggamit ng mga istatistika at matematika. Kung ang iyong mga pamamaraan ng survey ay hindi batay sa agham, ang mga resulta ay maaaring mapanlinlang.
Sa mga istatistika, ang sumusunod na delineasyon ng mga laki ng sample ay pinagtibay. Ang laki ng sample, sapat para sa magkaparehong pagkansela ng mga aksidente at pagkuha ng mga istatistikal na katangian ng isang regular na kalikasan, ay katumbas ng 30. Ang isang sample ng ganitong laki ay tinatawag maliit. Ang likas na katangian ng pamamahagi ng mga halaga ng katangian sa maliliit na sample ay lumalapit sa normal na may pagtaas sa bilang ng mga pagsubok. Ang pinakamababang laki ng sample na nagbibigay-daan sa iyo upang makuha ang average na mga halaga ng katangian na may indikasyon ng mga probabilidad ng kumpiyansa ay 5. Ang mga sample ng ganitong laki ay tinatawag napakaliit. Ang pamamahagi ng mga halaga ng katangian sa naturang mga sample ay nailalarawan sa pamamahagi ng Mag-aaral. Ngunit kadalasan sa sosyolohiya ay nakikitungo sila sa mas malaking sukat ng sample.
Kapag nagpaplano ng isang sample na survey, darating ang isang oras na kinakailangan upang magpasya kung gaano karaming tao ang pakikipanayam, i.e. kung ano dapat ang sample size. Ang desisyong ito ay lubhang mahalaga dahil masyadong malaki ang sample ay hindi na kailangan at masyadong maliit ay makakabawas sa kalidad ng mga resulta.
Laki ng sample- ang kabuuang bilang ng mga yunit ng pagmamasid na kasama sa sample.
Dahil ang sample na populasyon ay bahagi ng pangkalahatang populasyon, pinili gamit ang mga espesyal na pamamaraan, mahalaga na ang bahaging ito ay hindi papangitin ang ideya ng kabuuan, i.e. kinakatawan ito. Ang mga sosyologo, na madalas nagsasagawa ng empirical research, ay patuloy na nag-aalala tungkol sa kung gaano karaming tao ang kailangang makapanayam upang makakuha ng maaasahang impormasyon? Ang Gallup Institute sa United States ay nagsasagawa ng mga regular na botohan sa isang pambansang sample ng 1.5 libong tao at nakakamit ng kamangha-manghang katumpakan (mga saklaw ng error sa sampling mula 1 hanggang 1.5%). Ang Socio-Express Center ng Institute of Sociology ng Russian Academy of Sciences ay nagsasagawa ng pananaliksik sa isang sample ng 2 libong tao, habang ang sampling error ay hindi lalampas sa 3% 31.
Naniniwala ang mga eksperto na ang pinakamahusay na sample ay hindi kinakailangang malaki. Siyempre, mas malaki ang sukat ng sample, mas mataas ang katumpakan ng mga resulta nito. Gayunpaman, kahit na ang isang malaking sample ay hindi ginagarantiyahan ang tagumpay kung ang pangkalahatang populasyon ay "mahinang halo-halong", i.e. ay magkakaiba. homogenous ang nasabing set ay isinasaalang-alang kung saan ang kinokontrol na tampok ay pantay na ipinamamahagi, hindi bumubuo ng mga void o condensation. Sa kasong ito, sa pamamagitan ng pakikipanayam sa ilang tao, maaari kang makakuha ng tumpak na impormasyon tungkol sa pamamahagi ng tampok na ito sa pangkalahatang populasyon.
Kaya, ang pagiging kinatawan ng data ay naiimpluwensyahan hindi ng mga quantitative na katangian ng sample (volume nito), ngunit sa pamamagitan ng mga qualitative na katangian ng pangkalahatang populasyon - sa pamamagitan ng antas ng homogeneity nito.
Ang sosyolohiya ay hindi pa nakaimbento ng isang solong at malinaw na pormula na maaaring magamit upang kalkulahin ang pinakamainam na sukat ng sample na populasyon - ang gayong pormula ay hindi umiiral sa kalikasan. At ito ay ipinaliwanag nang napakasimple. Ang katotohanan ay ang pagtukoy sa laki ng sample na populasyon ay hindi isang istatistikal na problema kundi isang malaking problema. Sa madaling salita, ang laki ng sample na populasyon ay nakasalalay sa maraming mga kadahilanan, kabilang ang mga layunin at layunin, ang teoretikal na modelo, mga hypotheses at pamamaraan ng pananaliksik, ang antas ng homogeneity ng pangkalahatang populasyon, at panghuli, ang kinakailangang katumpakan ng impormasyong natanggap.
Laging tandaan na ang bawat porsyento ng pagtaas sa katumpakan ng impormasyon sa isang pag-aaral ay humahantong sa isang matalim na pagtaas sa gastos ng pagsasagawa nito. Ang sikat na Gallup Institute, na nagsasagawa ng mga botohan sa Estados Unidos sa loob ng maraming dekada, ay natagpuan na sa isang pambansang sample na 100 tao, ang sampling error ay nasa loob ng ± 11%; 200 tao - ± 8%; 400 - ± 6%; 600 - ± 5%; 750 - ± 4%; 1000 - ± 4%; 1500 - ± 3%; 4000 tao - ± 2%. Kaya naman nagsasagawa siya ng mga nationwide poll sa Estados Unidos sa sample ng 1,500-2,000 katao. Gaya ng nakikita mo, mas gusto niya ang 1% na pagtaas ng error kaysa sa maraming pagtaas sa gastos sa pananaliksik.
Ipinapakita ng pagsasanay na para sa maraming sosyologo ang pagbibigay-katwiran sa laki ng sample ay isang hadlang, sa kabila ng malaking dami ng literatura sa mga pamamaraan ng sampling at, lalo na, ang pagkalkula ng laki ng sample. Mayroong ilang mga dahilan: 1) ang kakulangan ng espesyal na panitikan sa paligid; 2) kakulangan ng oras para sa pag-aaral sa sarili; 3) kawalan ng kakayahan na gamitin ang mathematical apparatus. Sa pagsasaalang-alang na ito, kinakailangan na balangkasin ang diskarte at taktika ng pagpapatunay ng laki ng sample nang walang kumplikadong mga formula sa matematika.
Ang pamamaraan para sa pagkalkula ng laki ng sample ay isang kadena ng walang katapusang trade-off sa pagitan ng pagtugis ng katumpakan at limitadong mga mapagkukunan, kakulangan ng oras at hindi kumpletong impormasyon tungkol sa hindi pangkaraniwang bagay na pinag-aaralan. Kasabay nito, ito ay isang agham at sining, ang kaalaman na magagamit ng bawat tao. Gayunpaman, para magawa ito, kailangan mong malaman ang mga estratehiya para sa pagkalkula ng laki ng sample (paunang pagkalkula, sunud-sunod at pinagsamang mga diskarte), pati na rin ang mga salik na nakakaapekto sa laki ng sample (laki ng pangkalahatang populasyon, pagkakaiba-iba ng mga sagot ng mga respondent, katumpakan ng pagtatantya , ang likas na katangian ng inaasahang pamamahagi ng mga sagot, pamamaraan ng pananaliksik, pamamaraan ng pagproseso) ...
Diskarte bago ang pagkalkula binubuo sa katotohanan na ang laki ng sample ay tinutukoy bago isagawa ang pangunahing pag-aaral. Sa pinakasimpleng kaso, maaari mong gamitin ang karanasang natamo na, halimbawa, ang Gallup Institute, na gumagamit ng sample na laki ng humigit-kumulang 1500-2000 tao. Para sa isang karaniwang pag-aaral sa Russia, ang laki ng sample ay humigit-kumulang 400-600 katao.
Upang kalkulahin ang dami ng isang random na sample, kailangan mong malaman ang nais na katumpakan ng pagtatantya, ang halaga ng panganib ng tugon at ang antas ng pagkakaiba-iba ng tugon. Ayon sa kaugalian, ang katumpakan ng pagtatantya ay kinukuha bilang 5%, at ang halaga ng panganib - bilang 0.95. Sa madaling salita, kung, ayon sa isang sample na pag-aaral, 60% ng mga sumasagot ay nasiyahan sa kanilang trabaho, kung gayon maaari itong maitalo na sa pangkalahatang populasyon ang bahagi ng mga nasisiyahang tao ay mula 55 hanggang 65% sa 95% ng mga kaso, at sa 5% ng mga kaso ang bahaging ito ay maaaring lumampas sa pagitan na ito. Sa pag-aakalang 5% na katumpakan at isang panganib na halaga na 0.95, ang laki ng sample ay ang mga sumusunod (Talahanayan 2.4).
mesa 2.4 Depende sa laki ng sample sa laki ng pangkalahatang populasyon
Ang mga resulta ay ipinapakita sa talahanayan. 2.4, tumestigo laban sa malawakang maling kuru-kuro na ang laki ng sample ay isang mahigpit na nakapirming porsyento ng pangkalahatang populasyon, katumbas ng 10. Sa katunayan, ang halagang ito ay hindi pare-pareho, ngunit isang variable na nagbabago sa mga partikular na kundisyon. Ang laki ng sample ay depende rin sa kung aling mga tanong ang ginagamit sa talatanungan. Mga figure sa talahanayan. 2.4 ay may bisa lamang para sa isang kaso - pagdating sa isang dichotomous na tanong, kung saan ang maximum na dispersion ng mga sagot ay 50 hanggang 50%. Dahil kulang ang paunang impormasyon tungkol sa hanay ng mga pagtatantya, ang sosyologo ay tila nakaseguro nang maaga at naniniwala na ang saklaw na ito ay magiging 50 hanggang 50%. Kung magagamit ang naturang impormasyon, ang laki ng sample ay magiging tulad ng sumusunod.
Talahanayan 2.5 Depende sa laki ng sample sa pamamahagi ng dichotomous na tugon
mesa Ipinapakita ng 2.5 ang pamamahagi ng mga sagot sa mga tanong na husay. Ang pagkalkula ng sample size para sa quantitative na mga tanong, kabilang ang mga tanong tulad ng "edad" at "sahod", ay batay sa coefficient of variation (Talahanayan 2.6), na nagpapakita kung anong porsyento ang standard deviation mula sa arithmetic mean, at nagbibigay-daan sa iyong ihambing (sa antas ng pagkakaiba-iba) anumang mga palatandaan.
Talahanayan 2.6 Depende sa laki ng sample sa koepisyent ng pagkakaiba-iba
| Ang koepisyent ng pagkakaiba-iba, % | ||||||||||||
| Laki ng sample |
Kung pinag-aaralan ang mga kondisyon sa pagtatrabaho, relasyon sa pangkat, sahod, atbp. gamit ang limang-term na iskala, ang koepisyent ng variation dito ay nag-iiba mula 27 hanggang 62%, at kapag gumagamit ng pitong terminong iskala, mula 78 hanggang 113%. Samakatuwid, kung mas mahaba ang sukat, mas mataas ang koepisyent ng pagkakaiba-iba at mas malaki dapat ang sukat ng sample. Kung nais ng isang sosyologo na makayanan ang isang maliit na sample, kung gayon ang mga tanong ay dapat na mas madaling mabalangkas. Minsan ay iniisip na kung mas mahaba ang sukat, mas tumpak ang pagsukat. Ngunit ang mga bentahe ng seven-point scales sa five-point scales ay hindi pa napatunayan.
Mayroong malawak na opinyon sa mga sosyologo na kung mas malaki ang sukat ng sample, mas tumpak ang resulta, at pinipilit silang dagdagan ang bilang ng mga tumutugon nang hindi makatwiran. Sa katotohanan, iba ang sitwasyon: tab. Ang 2.7, na pinagsama-sama mula sa Gallup Institute, ay nagpapakita ng kaugnayan sa pagitan ng laki ng sample at katumpakan ng porsyento. Ito ay sumusunod mula dito na sa isang pagtaas sa laki ng sample, ang katumpakan ay tumataas, ngunit hanggang sa isang tiyak na threshold. Mayroon nang 600 na tumutugon, ang nais na 5% na antas ng katumpakan ay makakamit. Samakatuwid, ang 600 tao ay isang katanggap-tanggap na laki ng sample.
Walang kontradiksyon sa pagitan ng mga bilang na 400 at 600 katao. Sa unang kaso, ang laki ng sample ay kinakalkula batay sa probisyon sa normal na pamamahagi ng mga sagot ng mga sumasagot, at sa pangalawa - mula sa pagsasanay. Ang pagkakaiba sa pagitan ng teorya at kasanayan ay dahil sa ang katunayan na sa isang tunay na sitwasyon ang pamamahagi ng mga pagtatantya ay naiiba mula sa normal, kaya ang laki ng sample ay dapat kalkulahin na isinasaalang-alang ang mismong pangyayari; ang pinaka-epektibong paraan upang bawasan ang laki ng sample ay upang bawasan ang koepisyent ng pagkakaiba-iba ng mga pagtatantya.
Talahanayan 2.7 Relasyon sa pagitan ng laki ng sample at katumpakan ng pagtatantya
Kapag kinakalkula ang laki ng sample, madalas na nagkakamali ang mga sosyologo: na nakalkula ang kinakailangang laki ng sample sa kabuuan para sa populasyon gamit ang mga umiiral na formula, pagkatapos ay proporsyonal na ilalaan ito sa hiwalay na mga subdivision ng sample, halimbawa, sa pamamagitan ng mga workshop, negosyo, distrito. , lungsod, at mga uri ng pamilya. Pagkatapos nito, sa yugto ng pagpoproseso ng data, ang mismong mga pagkakaiba sa pagitan ng mga departamento ay sinusuri. Gayunpaman, mas tama na kalkulahin ang laki ng sample nang hiwalay para sa bawat dibisyon, at pagkatapos ay ibuod ang mga indibidwal na volume. Halimbawa, ang mga kalkulasyon ng laki ng sample para sa tatlong mga tindahan (isinasaalang-alang ang laki ng sukat, ang bilang ng mga empleyado, ang likas na katangian ng tinantyang pamamahagi ng mga pagtatantya) ay naging posible upang maitatag na sa unang tindahan ay kinakailangan upang magtanong sa 384 na tao, sa pangalawa - 222, at sa pangatlo - 600. Pagkatapos ang kabuuang sukat ng sample ay magiging 384 + 222 + 600 = 1206 na tao.
Kung ang isang sosyologo ay kailangang makapanayam ng anumang kategorya ng mga manggagawa (halimbawa, mga driver ng bus), tungkol sa kung saan ito ay kilala lamang na ito ay kabilang, halimbawa, ang ikasampung empleyado ng negosyo, at nagpasya siyang magtanong sa 139 na mga driver ng bus, at ang kabuuang sukat ng sample para sa negosyo ay magiging 1390 katao, iyon. sa madaling salita, sa pamamagitan ng random na pagpili ng 1,390 respondents sa enterprise, alinsunod sa teorya ng sampling, umaasa kaming matukoy ang 139 na tao ng espesyalidad na interesado sa amin.
Kapag nagkalkula ng sample ng quota, kadalasang arbitraryong tinutukoy ng mga sosyologo ang laki nito sa 1000, batay sa kaginhawahan ng pagkalkula ng mga quota. Ngunit maaari ka ring kumuha ng anumang iba pang round number. Ang mas makatwiran ay ang diskarte kung saan ang laki ng sample ng quota ay kinakalkula bilang para sa isang random na sample. Ang isa pang opsyon para sa pagkalkula ng laki ng sample ng quota ay ang paggamit ng teorya ng maliliit na sample. Ang kakanyahan nito: kung ang layunin ay hindi magbigay ng pagkakaiba-iba ng pagsusuri ng mga grupo ng mga manggagawa, kung gayon ang bilang ng mga gradasyon ng mga tanong na pag-aaralan ay i-multiply sa 25 (ang pinakamababang laki ng pangkat na makabuluhang istatistika). Halimbawa, tatlong mga variable ang pinag-aaralan: kasarian - dalawang kategorya, edad - dalawang kategorya (sa ilalim ng 30 at higit sa 30), kasiyahan sa trabaho - sinusukat sa limang-puntong sukat. Pagkatapos ang kinakailangang laki ng sample para sa halimbawang ito ay magiging 2x2x5x25 = 500 tao. Ang laki ng sample ay tumataas ng 2.5 beses. Ito ay malinaw na sa pagpapalawak ng bilang ng mga variable at ang bilang ng mga gradasyon, ang laki ng sample ay maaaring maging malaking sakuna. Mayroon lamang isang paraan: isang detalyadong pag-aaral ng orihinal na problema, na magpapahintulot sa iyo na tanggihan ang mga hindi kinakailangang tanong sa palatanungan, na iniiwan ang pinakamahalaga. Kung ang isang pag-aaral ay sumusubok ng ilang hypothesis, kung gayon ang laki ng sample para sa pagsubok sa bawat hypothesis ay kinakalkula nang hiwalay. Kaya, kapag gumagamit ng sample, ang bilang ng mga tanong sa questionnaire at hypotheses ay dapat na minimal.
Kaya, kinakalkula namin ang kinakailangang laki ng sample. Ngayon, at ngayon lamang, kinakailangan upang suriin kung ang nakuha na halaga ay tugma sa mga inilalaan na mapagkukunan. Ang isang tipikal na pagkakamali ng maraming inilapat na mga sosyologo ay kapag kinakalkula ang laki ng sample, ang mga magagamit na mapagkukunan ay nasa unahan, o, mas masahol pa, ang sosyologo ay passive na tinatanggap ang lahat ng mga kundisyon na idinidikta ng kliyente. Sa panimula ito ay mali para sa ilang kadahilanan. Una, ang pagkalkula ng laki ng sample ay nagbibigay-daan sa isang mas malalim na pananaw sa kakanyahan ng paksang pinag-aaralan at ang mga detalye ng mga pamamaraan ng pananaliksik, na nangangahulugan na maaari itong makatuwirang humingi ng higit pang mga mapagkukunan o gumawa ng tamang desisyon upang bawasan ang laki ng sample. Kung ang administrasyon ay tumanggi sa karagdagang mga mapagkukunan, at ang mga layunin ng pag-aaral ay hindi nagpapahintulot na bawasan ang laki ng sample (i.e., ang sosyologo ay hindi maaaring gumawa ng desisyon ng administrasyon), kung gayon kinakailangan na lumipat sa ibang pamamaraan ng pananaliksik. Pangalawa, ang isang makatwirang pagkalkula ng laki ng sample ay nagpapakita ng propesyonalismo ng sosyologo at ginagawang higit na paggalang ang kliyente.
Sequential settlement strategy laki ng sample. Kapag kinakalkula ang laki ng sample, kanais-nais na malaman ang scatter ng mga pagtatantya at ilang iba pang mga parameter. Gayunpaman, kadalasan ay hindi sila kilala. Upang maiwasan ang mga pagkakamali, mas mahusay na ipagpalagay na ang mga ito ay maximum. Ang kabayaran para sa ating kamangmangan ay ang paglaki ng sample size na lampas sa kinakailangan at karagdagang gastos sa pananalapi at oras (kailangan nating mag-interview ng mas malaking bilang ng mga tao). Upang makatipid ng mga gastos, ginagamit ang isang pare-parehong diskarte - ang laki ng sample ay hindi kinakalkula nang maaga, ngunit ginawang nakadepende sa mga huling resulta ng pag-aaral. Halimbawa, 100 tao ang kinapanayam, pagkatapos ay itinakda ang halaga ng scatter ng mga pagtatantya at, depende dito, kinakalkula ang kinakailangang laki ng sample. Kung lumalabas na sapat na ang 100 tao, pagkatapos ay matatapos ang pag-aaral. Kung hindi, ang kinakailangang bilang ng mga tumutugon ay makakarating doon, ngunit hindi nang walang katiyakan. Mayroong isang halimbawa mula sa pagsasanay ni J. Gallup, na sa simula ng kanyang karera ay aktibong nag-eksperimento sa mga laki ng sample. Noong 1936, tinanong ang mga Amerikano ng tanong na: "Gusto mo bang i-renew ang batas sa pagpapanumbalik ng pambansang industriya?" Isang kakaibang kabalintunaan ang lumitaw: Si J. Gallup ay unang nakipagpanayam sa 500 katao at sinukat ang sampling error, at pagkatapos ay patuloy na nadagdagan ang bilang ng mga sumasagot sa 30 libo. Sa kasamaang palad, nalaman niya na ang pagdaragdag ng 29.5 libong mga sumasagot ay nagpapataas ng katumpakan ng impormasyon nang mas mababa sa 1 %. Dahil dito, ang botohan ay maaaring itinigil na nang may 500 respondents. Ipinapakita ng halimbawang ito na sa pamamagitan ng paggamit ng isang sunud-sunod na diskarte, posibleng makamit ang isang makabuluhang pagbawas sa bilang ng mga obserbasyon na kinakailangan kumpara sa paunang pagkalkula ng laki ng sample.
Gayunpaman, ang diskarte ng sunud-sunod na pagkalkula ng laki ng sample ay nagdudulot lamang ng nais na resulta kung ang sosyologo ay maaaring gumawa ng mga kinakailangang kalkulasyon sa kurso ng survey mismo, halimbawa, telepono, gamit ang mga computer system. Ipinapasok ng sosyologo ang mga sagot ng respondent sa kanyang personal na computer, kung saan ang mga resulta ay agad na ipinadala sa computer ng manager ng pananaliksik, naproseso, at ang display screen ay nagpapakita ng impormasyon hindi lamang tungkol sa mga one-dimensional na frequency na ibinahagi sa isang partikular na isyu, kundi pati na rin tungkol sa kinakailangang laki ng sample.
Kung may panganib na ang laki ng sample ay maaaring maging malaking sakuna, kinakailangan na pagsamahin ang parehong uri ng diskarte - paunang at sunud-sunod, i.e. mag-apply pinagsamang diskarte. Ang pagkalkula ng sample ayon sa paunang diskarte, nakuha namin ang itaas na tinatanggap na mga halaga para sa sunud-sunod na diskarte, o, sa madaling salita, ang halaga ng laki ng sample, kapag naabot kung saan huminto ang botohan ayon sa sunud-sunod na diskarte.
Ang pinaka-makatwiran at tamang diskarte sa pagtukoy ng laki ng sample ay batay sa pagkalkula ng mga pagitan ng kumpiyansa, na batay sa isang bilang ng mga pangunahing konsepto ng mga istatistika ng matematika (variation, standard deviation, confidence interval, standard error).
Upang kalkulahin ang kinakailangang laki ng sample sa quantitative na pananaliksik, dalawang konsepto ng istatistika ang kadalasang ginagamit - ang agwat ng kumpiyansa at ang posibilidad ng kumpiyansa. Agwat ng kumpiyansa kumakatawan sa sampling error na iyong tinukoy nang maaga. Halimbawa, kung nagtakda ka ng agwat ng kumpiyansa na 3% at ang tiyak na sagot sa isang partikular na tanong sa pananaliksik ay 48%, nangangahulugan ito na kahit na survey mo ang buong populasyon, ang aktwal na halaga ay mahuhulog sa pagitan ng 45 (48 - 3). ) at 51% (48 + 3). Posibilidad ng kumpiyansa nagpapakita kung gaano ka kumpiyansa sa mga resultang nakuha, na ang mga katangian ng sample ay tumutugma sa mga katangian ng buong pangkalahatang populasyon - sa madaling salita, kung ano ang posibilidad na ang random na sagot ay mahuhulog sa loob ng agwat ng kumpiyansa. Karaniwang ginagamit ang 95% at 99% na antas ng kumpiyansa. Kadalasan, 95% ang ginagamit - ito ay sapat na sa karamihan ng mga pag-aaral. Kung pagsasamahin mo ang antas ng kumpiyansa at ang pagitan ng kumpiyansa, maaari nating sabihin na ang mga sagot sa tanong na may 95% na posibilidad ay mahuhulog sa pagitan ng 45 at 51%.
Ang sumusunod na magaspang na pagtatantya ng pagiging maaasahan ng mga resulta ng sample na survey ay lubhang kapaki-pakinabang. Ang pagtaas ng pagiging maaasahan ay nagbibigay-daan para sa isang error sa sampling ng hanggang sa 3%, karaniwan - mula 3 hanggang 10% (pagtitiwala sa pagitan ng mga pamamahagi sa antas ng 0.03 hanggang 0.1), tinatayang - mula 10 hanggang 20%, tinatayang - mula 20 hanggang 40%, at tinatayang - higit sa 40%.
Batay sa mga konseptong ito, na isinasaalang-alang ang isang bilang ng mga pagpapalagay, ang mga formula para sa pagkalkula ng laki ng sample ay hinango, na ipinapalagay na ang pagiging kinatawan ay ginagarantiyahan sa pamamagitan ng paggamit ng mga tamang probabilistic sampling na pamamaraan.
Sa ilang mga kaso, ang halaga ng survey ay ginagamit bilang pangunahing argumento sa pagtukoy ng laki ng sample. Kaya, ang badyet sa pananaliksik sa marketing ay nagbibigay para sa mga gastos ng ilang mga survey, na hindi dapat lumampas, at ito ay malinaw na ang halaga ng impormasyon na natanggap ay hindi isinasaalang-alang. Gayunpaman, sa ilang mga kaso, kahit na ang isang maliit na sample ay maaaring magbigay ng medyo tumpak na mga resulta.
Iminumungkahi ng kasanayan sa pananaliksik ang sumusunod na panuntunan: ang laki ng sample ay dapat magbigay ng hindi bababa sa 100 obserbasyon para sa bawat pangunahin at hindi bababa sa 20-50 obserbasyon para sa bawat bahagi ng pangalawang pag-uuri. 11 ang mga pangunahing bahagi ng pag-uuri ay tumutugma sa pinaka kritikal, at ang mga pangalawa ay tumutugma sa hindi bababa sa kritikal na mga cell ng cross-classification na pinagtibay sa pag-aaral na ito 34. Ang mga teoretikal na kalkulasyon at kasanayan ay nagpapatunay na upang makakuha ng maaasahang data sa opinyon at kagustuhan ng populasyon ng isang malaking lungsod tulad ng St. Petersburg, sapat na upang makapanayam ang 700-800 katao. Gayunpaman, karamihan sa mga survey ng populasyon dito ay isinasagawa sa mga sample na hanggang 1.5 libong tao.
Error sa pag-sample
Tulad ng alam na natin, ang pagiging kinatawan ay ang pag-aari ng isang sample upang kumatawan sa isang katangian ng pangkalahatang populasyon. Kung walang laban, pinag-uusapan nila pagkakamali ng pagiging kinatawan- ang lawak kung saan ang istatistikal na istraktura ng sample ay lumihis mula sa istruktura ng kaukulang pangkalahatang populasyon. Ipagpalagay na ang average na buwanang kita ng pamilya ng mga pensiyonado sa pangkalahatang populasyon ay 2 libong rubles, at sa sample - 6 na libong rubles. Nangangahulugan ito na ang sosyologo ay nakapanayam lamang ang may-kaya na bahagi ng mga pensiyonado, at isang pagkakamali sa pagiging representatibo ang pumasok sa kanyang pananaliksik. Sa madaling salita, ang pagkakamali ng pagiging kinatawan ay tinatawag pagkakaiba sa pagitan ng dalawang populasyon- pangkalahatan, kung saan ang teoretikal na interes ng sosyolohista ay nakadirekta at isang ideya ng mga katangian na nais niyang makuha sa dulo, at pumipili, kung saan ang praktikal na interes ng sosyolohista ay nakadirekta, na kumikilos nang sabay-sabay bilang isang bagay ng pagsusuri at isang paraan ng pagkuha ng impormasyon tungkol sa pangkalahatang populasyon.
Kasama ang terminong "error of representativeness" sa domestic literature, makakahanap ka ng isa pa - "sampling error". Minsan ginagamit ang mga ito nang magkasingkahulugan, at kung minsan ang "sampling error" ay ginagamit sa halip na "representativeness error" bilang isang quantitatively mas tumpak na konsepto.
Error sa pag-sample- ang paglihis ng average na katangian ng sample mula sa average na katangian ng pangkalahatang populasyon.
Sa pagsasagawa, ang sampling error ay tinutukoy sa pamamagitan ng paghahambing ng mga kilalang katangian ng pangkalahatang populasyon sa sample na paraan. Sa sosyolohiya, kapag sinusuri ang populasyon ng nasa hustong gulang, kadalasang ginagamit ang data mula sa mga census ng populasyon, kasalukuyang mga rekord ng istatistika, at ang mga resulta ng mga nakaraang survey. Ang mga katangiang sosyo-demograpiko ay karaniwang ginagamit bilang mga parameter ng kontrol. Paghahambing ng mga paraan ng pangkalahatan at sample na populasyon, batay dito, ang pagpapasiya ng error sa sampling at ang pagbawas nito ay tinatawag pagkontrol sa pagiging kinatawan. Dahil ang paghahambing ng data mo at ng ibang tao ay maaaring gawin sa pagtatapos ng pag-aaral, ang pamamaraang ito ng kontrol ay tinatawag isang posterior, mga. natupad pagkatapos ng eksperimento.
Sa mga botohan ng J. Gallup Institute, ang pagiging kinatawan ay kinokontrol ayon sa data na makukuha sa mga pambansang census sa pamamahagi ng populasyon ayon sa kasarian, edad, edukasyon, kita, propesyon, lahi, lugar ng paninirahan, at laki ng paninirahan. . Gumagamit ang All-Russian Center for the Study of Public Opinion (VTsIOM) para sa mga layuning tulad ng mga indicator gaya ng kasarian, edad, edukasyon, uri ng paninirahan, marital status, sphere of employment, job status ng respondent, na hiniram mula sa Estado. Komite sa Istatistika ng Russian Federation. Sa parehong mga kaso, ang pangkalahatang populasyon ay kilala. Ang sampling error ay hindi maitatag kung ang mga halaga ng variable sa sample at ang pangkalahatang populasyon ay hindi alam.
Kapag sinusuri ang data, tinitiyak ng mga espesyalista ng VTsIOM ang isang masusing pag-aayos ng sample upang mabawasan ang mga deviation na lumitaw sa yugto ng field work. Ang mga partikular na malakas na displacement ay sinusunod sa mga tuntunin ng kasarian at edad. Ito ay ipinaliwanag sa pamamagitan ng katotohanan na ang mga kababaihan at mga taong may mas mataas na edukasyon ay gumugugol ng mas maraming oras sa bahay at mas madaling makipag-ugnayan sa tagapanayam, i.e. ay isang madaling maabot na grupo kumpara sa mga lalaki at mga taong "walang pinag-aralan".
Ang sampling error ay sanhi ng dalawang salik: ang paraan ng sampling at ang laki ng sample.
Ang mga sampling error ay inuri sa dalawang uri - random at sistematiko. Random na error - ito ay ang posibilidad na ang sample mean ay lalampas (o hindi lalampas) sa tinukoy na agwat. Kasama sa mga random na error ang mga statistical error na likas sa mismong paraan ng sampling. Bumababa ang mga ito sa pagtaas ng laki ng sample (Talahanayan 2.8).
Talahanayan 2.8
Pagdepende sa laki ng sample sa error 36 nito (ang laki ng pangkalahatang populasyon ay 20 libong mga yunit)
| Sampling error,% | |||||||||||||
| Laki ng sample, mga yunit |
Ang pangalawang uri ng sampling error ay sistematikong mga pagkakamali. Kung ang isang sosyologo ay nagpasya na alamin ang opinyon ng lahat ng mga residente ng lungsod tungkol sa patakarang panlipunan na itinataguyod ng mga lokal na awtoridad, at nakapanayam lamang ang mga may telepono, kung gayon mayroong isang sadyang pagkiling sa sample na pabor sa may-kaya gumawa ng strata, ibig sabihin sistematikong pagkakamali.
Kaya, ang mga sistematikong pagkakamali ay resulta ng mga aktibidad ng mismong mananaliksik. Ang mga ito ang pinaka-mapanganib dahil humahantong sila sa medyo makabuluhang pagkiling sa mga resulta ng pananaliksik. Ang mga sistematikong error ay itinuturing din na mas malala kaysa sa mga random na error dahil hindi sila makokontrol at masusukat.
Ang mga ito ay lumitaw kapag, halimbawa: 1) ang sample ay hindi tumutugma sa mga layunin ng pag-aaral (nagpasya ang sosyologo na pag-aralan lamang ang mga nagtatrabaho na pensiyonado, ngunit nakapanayam ang lahat ng magkakasunod); 2) may kakulangan ng kaalaman sa likas na katangian ng pangkalahatang populasyon (naisip ng sosyologo na 70% ng lahat ng mga pensiyonado ay hindi nagtatrabaho, ngunit 10% lamang ang hindi gumagana); 3) tanging ang mga "panalong" elemento ng pangkalahatang populasyon ang napili (halimbawa, mga mayayamang pensiyonado lamang).
Pansin!Hindi tulad ng mga random na error, hindi bumababa ang mga sistematikong error sa pagtaas ng laki ng sample.
Binubuod ang lahat ng mga kaso kapag nangyari ang mga sistematikong pagkakamali, pinagsama-sama ng mga metodologo ang kanilang rehistro. Naniniwala sila na ang mga sumusunod na salik ay maaaring pagmulan ng hindi nakokontrol na pagkiling sa pamamahagi ng mga sample na kaso:
♦ ang metodolohikal at metodolohikal na mga tuntunin para sa pagsasagawa ng sosyolohikal na pananaliksik ay nilabag;
♦ hindi sapat na paraan ng pagbubuo ng sample na populasyon, mga paraan ng pagkolekta at pagkalkula ng data ang napili;
♦ ang mga kinakailangang yunit ng pagmamasid ay pinalitan ng iba, mas madaling ma-access;
♦ Napansin ang hindi kumpletong saklaw ng sample (kakulangan ng mga talatanungan, hindi kumpletong pagpuno, hindi naa-access ng mga yunit ng pagmamasid).
Ang sosyologo ay bihirang gumawa ng sinasadyang mga pagkakamali. Mas madalas, ang mga pagkakamali ay lumitaw dahil sa ang katunayan na ang sosyologo ay hindi alam ng mabuti ang istraktura ng pangkalahatang populasyon: ang pamamahagi ng mga tao ayon sa edad, propesyon, kita, atbp.
Ang mga sistematikong error ay mas madaling pigilan (kumpara sa mga random na error), ngunit napakahirap alisin. Pinakamainam na maiwasan ang mga sistematikong pagkakamali sa pamamagitan ng tumpak na paghula sa kanilang mga mapagkukunan nang maaga - sa pinakadulo simula ng pag-aaral.
Narito ang ilan mga paraan upang maiwasan ang mga pagkakamali:
♦ bawat yunit ng pangkalahatang populasyon ay dapat magkaroon ng pantay na posibilidad na mapabilang sa sample;
♦ kanais-nais na pumili mula sa magkakatulad na populasyon;
♦ kailangan mong malaman ang mga katangian ng pangkalahatang populasyon;
♦ kapag nag-iipon ng sample, kinakailangang isaalang-alang ang mga random at sistematikong pagkakamali.
Kung ang sample na populasyon (o simpleng sample) ay binubuo ng tama, kung gayon ang sosyologo ay makakakuha ng maaasahang mga resulta na nagpapakilala sa buong pangkalahatang populasyon. Kung ito ay iginuhit nang hindi tama, kung gayon ang error na lumitaw sa yugto ng sampling, sa bawat kasunod na yugto ng sosyolohikal na pananaliksik, ay dumarami at kalaunan ay umaabot sa ganoong halaga na higit sa halaga ng pananaliksik. Sinasabing mas marami ang masama kaysa mabuti sa naturang pananaliksik.
Ang mga ganitong error ay maaari lamang mangyari sa isang sample na populasyon. Upang maiwasan o mabawasan ang posibilidad na magkamali, ang pinakasimpleng paraan ay dagdagan ang mga laki ng sample (at mas mabuti sa laki ng pangkalahatang populasyon: kapag ang parehong mga populasyon ay nag-tutugma, ang sampling error ay tuluyang mawawala). Sa ekonomiya, imposible ang pamamaraang ito. May nananatiling isa pang paraan - upang mapabuti ang mga pamamaraan ng matematika ng sampling. Ginagamit ang mga ito sa pagsasanay. Ito ang unang channel ng pagtagos sa sosyolohiya ng matematika. Ang pangalawang channel ay mathematical data processing.
Ang problema ng mga error ay nagiging lalong mahalaga sa pananaliksik sa marketing, kung saan hindi masyadong malalaking sample ang ginagamit. Kadalasan ay bumubuo sila ng ilang daan, mas madalas - isang libong mga sumasagot. Dito, ang panimulang punto para sa pagkalkula ng sample ay ang tanong ng pagtukoy sa laki ng sample na populasyon. Ang laki ng sample ay nakasalalay sa dalawang salik: I) ang halaga ng pagkolekta ng impormasyon at 2) pagsusumikap para sa isang tiyak na antas ng istatistikal na pagiging maaasahan ng mga resulta na inaasahan ng mananaliksik na makuha. Siyempre, kahit na ang mga taong hindi nakaranas sa mga istatistika at sosyolohiya ay madaling maunawaan na mas malaki ang laki ng sample, i.e. mas malapit sila sa laki ng pangkalahatang populasyon sa kabuuan, mas maaasahan at maaasahan ang mga pinahirapang data. Gayunpaman, sa itaas ay napag-usapan na natin ang tungkol sa praktikal na imposibilidad ng tuluy-tuloy na mga survey sa mga kasong iyon kapag isinasagawa ang mga ito sa mga bagay, ang bilang nito ay lumampas sa sampu, daan-daang libo at kahit milyon-milyon. Malinaw na ang halaga ng pagkolekta ng impormasyon (kabilang ang pagbabayad para sa pagkopya ng toolkit, paggawa ng mga talatanungan, mga tagapamahala ng field at mga operator ng pag-input ng computer) ay nakasalalay sa halaga na handang ilaan ng customer, at kaunti lamang ang nakasalalay sa mga mananaliksik. Tulad ng para sa pangalawang kadahilanan, tatalakayin natin ito nang kaunti pa.
Kaya, mas malaki ang sample size, mas maliit ang posibleng error. Gayunpaman, dapat tandaan na kung nais mong doblehin ang katumpakan, kailangan mong dagdagan ang sample hindi dalawang beses, ngunit apat na beses. Halimbawa, upang gawing mas tumpak ang iyong pagtatantya ng data na nakuha mula sa isang survey ng 400 tao, hindi 800 ang kailangan mong interbyuhin, kundi 1600 tao. Gayunpaman, hindi malamang na ang pananaliksik sa marketing ay nangangailangan ng isang daang porsyento na katumpakan. Kung kailangang malaman ng isang brewer kung anong bahagi ng mga mamimili ng beer ang mas pinipili ang kanyang tatak kaysa sa tatak ng kanyang katunggali - 60% o 40%, kung gayon ang pagkakaiba sa pagitan ng 57%, 60 o 63% ay hindi makakaapekto sa kanyang mga plano sa anumang paraan.
Ang error sa pag-sample ay maaaring depende hindi lamang sa laki nito, kundi pati na rin sa antas ng mga pagkakaiba sa pagitan ng mga indibidwal na yunit sa loob ng pangkalahatang populasyon na aming pinag-aaralan. Halimbawa, kung kailangan nating malaman kung gaano karaming beer ang natupok, makikita natin na sa loob ng ating pangkalahatang populasyon, ang mga rate ng pagkonsumo para sa iba't ibang tao ay malaki ang pagkakaiba. (magkakaiba pangkalahatang populasyon). Sa isa pang kaso, pag-aaralan natin ang pagkonsumo ng tinapay at matutuklasan na para sa iba't ibang tao ito ay naiiba nang mas kaunti. (homogeneous pangkalahatang populasyon). Kung mas malaki ang pagkakaiba (o heterogeneity) sa loob ng pangkalahatang populasyon, mas malaki ang magnitude ng posibleng error sa sampling. Kinukumpirma lang ng pattern na ito kung ano ang sinasabi sa atin ng simpleng common sense. Kaya, tulad ng tamang iginiit ni V. Yadov, "Ang laki (laki) ng sample ay depende sa antas ng homogeneity o heterogeneity ng mga bagay na pinag-aaralan. Kung mas homogenous ang mga ito, mas maliit ang bilang na maaaring magbigay ng maaasahang mga konklusyon sa istatistika."
Ang pagpapasiya ng laki ng sample ay nakasalalay din sa antas ng agwat ng kumpiyansa ng tinatanggap na error sa istatistika. Ito ay tumutukoy sa tinatawag na random mga error na nauugnay sa katangian ng anumang error sa istatistika. SA AT. Ibinibigay ng Paniotto ang mga sumusunod na kalkulasyon para sa isang kinatawan na sample na may 5% na error (Talahanayan 2.9):
Talahanayan 2.9
Mga kalkulasyon ng sample ng kinatawan
Nangangahulugan ito na kung nag-poll ka, sabihin nating, 400 katao sa isang distritong lungsod kung saan ang adult solvent na populasyon ay 100 libong tao, nalaman mong 33% ng mga na-survey na mamimili ay mas gusto ang mga produkto ng isang lokal na planta ng pagproseso ng karne, pagkatapos ay may 95% 39 probabilidad na maaari mong sabihin na 33 ± 5% (i.e. mula 28 hanggang 38%) ng mga naninirahan sa lungsod na ito ay mga regular na mamimili ng mga produktong ito.
Maaari mo ring gamitin ang mga kalkulasyon ng Gallup upang tantyahin ang ratio ng laki ng sample sa error sa pag-sample (tingnan sa itaas).
Ngayon, maraming mahirap na mga kalkulasyon ang ginagawa ng mga technician, at ang mga programa sa istatistika ay maaaring makuha mula sa Internet. Kaya sa pagkalkula ng sample, ang tamad na sociologist ay binigyan ng ganoong pagkakataon sa website ng Analytical Center na "Negosyo at Marketing" (http://www.bma.ru/enter.htm), kung saan kailangan lang ng user na ipasok ang kinakailangang data, at pagkatapos ay mag-click sa pindutan ng Kalkulahin.
Pagtatantya ng pagitan ng posibilidad ng isang kaganapan. Mga formula para sa pagkalkula ng laki ng sample na may wastong random na paraan ng pagpili.Upang matukoy ang mga probabilidad ng mga kaganapan na interesado sa amin, ginagamit namin ang paraan ng sampling: isinasagawa namin n mga independiyenteng eksperimento, kung saan ang bawat isa ay ang kaganapan A (probability R ang paglitaw ng kaganapan A sa bawat eksperimento ay pare-pareho). Pagkatapos ay ang relatibong dalas p * ng mga paglitaw ng mga kaganapan A sa isang serye ng n Ang pagsusulit ay kinuha bilang pagtatantya ng punto para sa posibilidad p paglitaw ng isang pangyayari A sa isang hiwalay na pagsubok. Sa kasong ito, ang dami ng p * ay tinatawag piling bahagi mga pagpapakita ng kaganapan A, at p - pangkalahatang bahagi .
Sa bisa ng isang corollary mula sa central limit theorem (ang Moivre-Laplace theorem), ang relatibong dalas ng isang kaganapan para sa isang malaking sukat ng sample ay maaaring ituring na normal na ipinamamahagi sa mga parameter na M (p *) = p at
Samakatuwid, para sa n> 30, ang agwat ng kumpiyansa para sa pangkalahatang fraction ay maaaring mabuo gamit ang mga formula:

kung saan ang u cr ay matatagpuan ayon sa mga talahanayan ng Laplace function na isinasaalang-alang ang ibinigay na posibilidad ng kumpiyansa γ: 2Ф (u cr) = γ.
Sa maliit na laki ng sample n≤30, ang marginal error ε ay tinutukoy mula sa talahanayan ng pamamahagi ng Estudyante: ![]() kung saan ang t cr = t (k; α) at ang bilang ng mga antas ng kalayaan k = n-1 probabilidad α = 1-γ (two-sided region).
kung saan ang t cr = t (k; α) at ang bilang ng mga antas ng kalayaan k = n-1 probabilidad α = 1-γ (two-sided region).
Ang mga formula ay wasto kung ang pagpili ay isinagawa sa isang random na paulit-ulit na paraan (ang pangkalahatang populasyon ay walang katapusan), kung hindi, ito ay kinakailangan upang gumawa ng isang susog para sa hindi pag-uulit ng pagpili (talahanayan).
Average na sampling error para sa pangkalahatang bahagi
| Pangkalahatang populasyon | Walang katapusang | Ultimate volume N |
| Uri ng pagpili | Paulit-ulit | Hindi na mauulit |
| Average na sampling error |
Mga formula para sa pagkalkula ng laki ng sample na may wastong random na paraan ng pagpili
| Paraan ng pagpili | Mga formula ng sample na laki | ||
| para sa gitna | para ibahagi | ||
| Paulit-ulit | |||
| Hindi na mauulit | |||
Pangkalahatang pagbabahagi ng mga problema
Sa tanong na "Sakop ba ng confidence interval ang ibinigay na halaga ng p 0?" - maaaring masagot sa pamamagitan ng pagsuri sa istatistikal na hypothesis H 0: p = p 0. Sa kasong ito, ipinapalagay na ang mga eksperimento ay isinasagawa ayon sa Bernoulli test scheme (independyente, ang posibilidad p paglitaw ng isang pangyayari A pare-pareho). Sa dami ng sample n tukuyin ang relatibong dalas p * ng paglitaw ng kaganapan A: kung saan m- ang bilang ng mga paglitaw ng kaganapan A sa isang serye ng n mga pagsubok. Upang subukan ang hypothesis H 0, ginagamit ang mga istatistika na may karaniwang normal na distribusyon para sa isang sapat na laki ng sample (Talahanayan 1).Talahanayan 1 - Mga hypotheses tungkol sa pangkalahatang bahagi
Hypothesis | H 0: p = p 0 | H 0: p 1 = p 2 |
| Mga pagpapalagay | Bernoulli Test Scheme | Bernoulli Test Scheme |
| Mga sample na pagtatantya |  |
|
| Mga istatistika K | 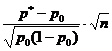 | 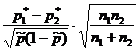 |
| Pamamahagi ng mga istatistika K | Karaniwang normal N (0,1) |
Halimbawa # 1. Gamit ang random re-sampling, nagsagawa ang management ng sample survey ng 900 sa mga empleyado nito. Sa mga respondente ay mayroong 270 kababaihan. I-plot ang confidence interval na sumasaklaw sa tunay na proporsyon ng kababaihan sa buong kumpanya na may probabilidad na 0.95.
Solusyon. Ayon sa kundisyon, ang sample na bahagi ng kababaihan ay (ang relatibong dalas ng kababaihan sa lahat ng mga respondent). Dahil inuulit ang sampling, at malaki ang sample size (n = 900), ang marginal sampling error ay tinutukoy ng formula ![]()
Ang halaga ng u cr ay matatagpuan mula sa talahanayan ng Laplace function mula sa kaugnayan 2Ф (u cr) = γ, i.e. ![]() Ang Laplace function (Appendix 1) ay kumukuha ng value na 0.475 sa u cr = 1.96. Samakatuwid, ang marginal error
Ang Laplace function (Appendix 1) ay kumukuha ng value na 0.475 sa u cr = 1.96. Samakatuwid, ang marginal error ![]() at ang nais na pagitan ng kumpiyansa
at ang nais na pagitan ng kumpiyansa
(p - ε, p + ε) = (0.3 - 0.18; 0.3 + 0.18) = (0.12; 0.48)
Kaya, na may posibilidad na 0.95, maaari naming ginagarantiyahan na ang bahagi ng kababaihan sa buong pangkat ng kumpanya ay nasa hanay mula 0.12 hanggang 0.48.
Halimbawa Blg. 2. Itinuturing ng may-ari ng parking lot na "maganda" ang araw kung ang parking lot ay higit sa 80% na puno. Sa panahon ng taon, 40 inspeksyon ng parking lot ang isinagawa, kung saan 24 ay "matagumpay". Hanapin ang agwat ng kumpiyansa na may posibilidad na 0.98 upang matantya ang tunay na proporsyon ng "matagumpay" na mga araw sa loob ng isang taon.
Solusyon... Ang piling bahagi ng "matagumpay" na mga araw ay
Gamit ang talahanayan ng Laplace function, makikita natin ang halaga ng u cr para sa isang naibigay
antas ng kumpiyansa
Ф (2.23) = 0.49, u cr = 2.33.
Isinasaalang-alang na ang pagpili ay hindi nauulit (ibig sabihin, dalawang pagsusuri ang hindi isinagawa sa isang araw), nakita namin ang marginal error: ![]()
kung saan n = 40, N = 365 (araw). Mula rito ![]()
at ang pagitan ng kumpiyansa para sa pangkalahatang bahagi: (p - ε, p + ε) = (0.6 - 0.17; 0.6 + 0.17) = (0.43; 0.77)
Sa posibilidad na 0.98, maaari nating asahan na ang bahagi ng "matagumpay" na mga araw sa taon ay nasa hanay mula 0.43 hanggang 0.77.
Halimbawa Blg. 3. Pagkatapos suriin ang 2500 item sa isang batch, nalaman namin na 400 item ang may pinakamataas na grado, at n – m ay hindi. Ilang produkto ang kailangan mong suriin upang matukoy nang may 95% na katiyakan ang proporsyon ng pinakamataas na grado na may katumpakan na 0.01?
Naghahanap kami ng solusyon ayon sa formula para sa pagtukoy ng laki ng sample para sa muling pagpili.
Ф (t) = γ / 2 = 0.95 / 2 = 0.475 at ang halagang ito ayon sa talahanayan ng Laplace ay tumutugma sa t = 1.96
Sample fraction w = 0.16; error sa sampling ε = 0.01
Halimbawa Blg. 4. Maraming mga produkto ang tinatanggap kung ang posibilidad na ang produkto ay sumunod sa pamantayan ay hindi bababa sa 0.97. Sa mga random na napiling 200 aytem ng nasubok na batch, 193 ang natagpuang nakakatugon sa pamantayan. Posible bang tumanggap ng isang partido sa antas ng kahalagahan α = 0.02?
Solusyon... Bumuo tayo ng pangunahin at alternatibong hypotheses.
H 0: p = p 0 = 0.97 - hindi kilalang pangkalahatang bahagi p katumbas ng ibinigay na halaga p 0 = 0.97. Tungkol sa kondisyon - ang posibilidad na ang isang bahagi mula sa nasubok na batch ay magiging pare-pareho sa pamantayan ay 0.97; mga. maaaring tanggapin ang batch ng mga produkto.
H 1: p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Naobserbahang halaga ng istatistika K(talahanayan) kinakalkula namin para sa mga ibinigay na halaga p 0 = 0.97, n = 200, m = 193

Nahanap namin ang kritikal na halaga mula sa talahanayan ng Laplace function mula sa pagkakapantay-pantay
![]()
Sa pamamagitan ng kundisyon, α = 0.02, kaya Ф (Ккр) = 0.48 at Ккр = 2.05. Ang kritikal na rehiyon ay nasa kaliwang bahagi, i.e. ay ang pagitan (-∞; -K kp) = (-∞; -2.05). Ang naobserbahang halaga ng K obs = -0.415 ay hindi kabilang sa kritikal na rehiyon, samakatuwid, sa antas na ito ng kahalagahan ay walang dahilan upang tanggihan ang pangunahing hypothesis. Maaari kang tumanggap ng isang batch ng mga produkto.
Halimbawa Blg. 5. Dalawang pabrika ang gumagawa ng parehong uri ng mga bahagi. Upang masuri ang kanilang kalidad, ang mga sample ay kinuha mula sa mga produkto ng mga pabrika na ito at ang mga sumusunod na resulta ay nakuha. Sa 200 napiling produkto ng unang planta, 20 ang may depekto, sa 300 produkto ng pangalawang planta - 15 ang may depekto.
Sa antas ng kabuluhan na 0.025, alamin kung may makabuluhang pagkakaiba sa kalidad ng mga bahagi na ginawa ng mga pabrika na ito.
Sa pamamagitan ng kundisyon α = 0.025, kaya Ф (Ккр) = 0.4875 at Ккр = 2.24. Sa isang dalawang panig na alternatibo, ang hanay ng mga tinatanggap na halaga ay (-2.24; 2.24). Ang naobserbahang halaga ng K obs = 2.15 ay nasa loob ng pagitan na ito, i.e. sa antas na ito ng kahalagahan, walang dahilan upang tanggihan ang pangunahing hypothesis. Ang mga pabrika ay gumagawa ng mga produkto ng parehong kalidad.