
Den optimale størrelse af en repræsentativ prøve. Sådan bestemmes den optimale stikprøvestørrelse til en masseundersøgelse
Når man designer en stikprøveobservation, opstår spørgsmålet om den nødvendige stikprøvestørrelse. Denne abundance kan bestemmes på grundlag af fejlmarginen i stikprøven, på grundlag af den sandsynlighed, ud fra hvilken størrelsen af den fejl, der skal bestemmes, kan garanteres, og endelig på grundlag af udvælgelsesmetoden .
Formlerne for den krævede stikprøvestørrelse for forskellige metoder til at danne stikprøvepopulationen kan udledes af de tilsvarende forhold, der bruges til at beregne de marginale stikprøvefejl. Her er de udtryk, der oftest bruges i praksis for den nødvendige stikprøvestørrelse:
Korrekt tilfældig og mekanisk prøveudtagning:
(genvalg)
![]() (ikke-gentaget valg)
(ikke-gentaget valg)
Typisk prøve:
(genvalg)
![]() (ikke-gentaget valg)
(ikke-gentaget valg)
Seriel prøveudtagning:
(genvalg)
(ikke-gentaget valg)
Samtidig kan varians og stikprøvefejl beregnes for gennemsnitsværdien eller andelen af en funktion, afhængigt af undersøgelsens mål.
Lad os overveje eksempler på at bestemme den nødvendige stikprøvestørrelse for forskellige metoder til at danne prøvepopulationen.
Eksempel 5. I 100 rejsebureauer i byen er det planlagt at gennemføre en undersøgelse af det gennemsnitlige månedlige antal solgte kuponer ved hjælp af metoden til mekanisk udvælgelse. Hvad skal stikprøvens størrelse være, så fejlen med en sandsynlighed på 0,683 ikke overstiger 3 passeringer, hvis variansen ifølge pilotundersøgelsen er 225.
Løsning... Lad os beregne den nødvendige prøvestørrelse:
Agenturer.
Eksempel 6. For at fastlægge andelen af ansatte i regionens forretningsbanker over 40 år foreslås det at organisere en typisk stikprøve proportional med antallet af mandlige og kvindelige medarbejdere med mekanisk udvælgelse inden for grupperne. Det samlede antal bankansatte er 12 tusinde mennesker, herunder 7 tusinde mænd og 5 tusinde kvinder.
Baseret på tidligere undersøgelser er det kendt, at gennemsnittet af afvigelser inden for gruppe er 1600. Bestem den nødvendige stikprøvestørrelse med en sandsynlighed på 0,997 og en fejl på 5 %.
Løsning. Lad os beregne den samlede størrelse af en typisk prøve:
![]() mennesker
mennesker
Lad os nu beregne volumen af individuelle typiske grupper:
![]() mennesker
mennesker
![]() mennesker
mennesker
Den nødvendige mængde af stikprøvepopulationen af bankers ansatte er således 550 personer, inkl. 319 mænd og 231 kvinder.
Eksempel 7. Aktieselskabet har 200 teams af arbejdere. Det er planlagt at gennemføre en stikprøveundersøgelse for at bestemme andelen af arbejdstagere med erhvervssygdomme. Det er kendt, at andelens interserievarians er lig med 225. Med en sandsynlighed på 0,954 beregnes det nødvendige antal hold til undersøgelse af arbejdere, hvis stikprøvefejlen ikke bør overstige 5 %.
Løsning. Vi vil beregne det nødvendige antal hold baseret på formlen for mængden af seriel ikke-gentagende prøvetagning:
![]() brigader.
brigader.
3. Bestemmelse af den nødvendige prøvestørrelse
Det er meget vigtigt at bestemme den optimale stikprøvestørrelse, som med en vis sandsynlighed vil give en given nøjagtighed af observationsresultater. Når stikprøvestørrelsen øges, falder stikprøvefejlen. Men da de enheder, der er udvalgt til undersøgelsen, ofte bliver ødelagt, burde satserne for udvælgelse af enheder i stikprøven være optimale. Den optimale stikprøvestørrelse kan fås fra prøvefejlformlerne.
Tabel 8.4
Formler til bestemmelse af den optimale prøvestørrelse
|
Udvælgelsesmetode |
Til medium |
|
|
Selvtilfælde gentaget |
|
|
|
Tilfældig og mekanisk ikke-gentagelig |
|
|
|
Typologisk ikke-gentagelig |
|
|
|
Seriel ikke-gentagelig med serier af samme størrelse |
|
|








Formlerne viser, at med en stigning i den estimerede stikprøvefejl falder den nødvendige stikprøvestørrelse betydeligt.
For at beregne stikprøvestørrelsen skal du kende variansen. Det kan lånes fra tidligere undersøgelser af denne eller en lignende population, eller der kan udføres en særlig stikprøveundersøgelse af et lille omfang.
Eksempel 2 : På virksomheden blev 100 arbejdere ud af 1000 interviewet i rækkefølgen af en tilfældig, ikke-gentagelig stikprøve, og følgende data om deres indkomst for oktober blev indhentet (tabel 8.5).
Tabel 8.5
Fordeling af arbejdere efter gennemsnitlig månedlig indkomst
Definere:
1) den gennemsnitlige månedlige indkomst for de ansatte i den givne virksomhed, der garanterer resultatet med en sandsynlighed på 0,997;
2) andelen af arbejdere i virksomheden med en månedlig indkomst på 19 tusind rubler. og højere, hvilket garanterer resultatet med en sandsynlighed på 0,954;
3) den krævede størrelse af prøven ved bestemmelse af den gennemsnitlige månedlige indkomst for ansatte i virksomheden, så den marginale prøveudtagningsfejl med en sandsynlighed på 0,954 ikke overstiger 200 rubler.
Løsning:
1) Bestem den gennemsnitlige månedlige indkomst for de ansatte i den givne virksomhed, hvilket garanterer resultatet med en sandsynlighed på 0,997.
|
n= 100 mennesker N= 1000 mennesker |
Løsning: for at bestemme intervallet for den gennemsnitlige månedlige indkomst for ansatte i en given virksomhed i den generelle befolkning, er det nødvendigt at kende værdien af den marginale stikprøvefejl Da P = 0,997, så (ifølge tabel 8.2) t= 3. Der blev foretaget et tilfældigt ikke-gentaget valg ifølge tabellen. 8.3 vælger vi en formel til at beregne den gennemsnitlige prøveudtagningsfejl for middelværdien:
Størrelsen af den gennemsnitlige månedlige indkomst for arbejdere ifølge stikprøveundersøgelsen bestemmes af formlen for det aritmetiske vægtede gennemsnit: Vi vil udføre yderligere beregninger i følgende tabel:
At vide t og Tusind. gnide. Så vil intervallet for den gennemsnitlige månedlige indkomst for arbejderne i denne virksomhed være som følger:
|
 og størrelsen af den gennemsnitlige månedlige indkomst for arbejdere ifølge stikprøveundersøgelsesdata
og størrelsen af den gennemsnitlige månedlige indkomst for arbejdere ifølge stikprøveundersøgelsesdata  .
. t og gennemsnitlig prøveudtagningsfejl
t og gennemsnitlig prøveudtagningsfejl  .
. , hvor
, hvor  - varians for prøven.
- varians for prøven. .
.



 tusind rubler.
tusind rubler.
 tusind rubler.
tusind rubler. Bestem værdien af den marginale stikprøvefejl:
Bestem værdien af den marginale stikprøvefejl: ;
; .
.Svar: den gennemsnitlige månedlige indkomst for de ansatte i denne virksomhed med en sandsynlighed på 0,997 er i intervallet 18,08 tusind rubler. op til 18,92 tusind rubler.
2) Bestem andelen af arbejdere i virksomheden med en månedlig indkomst på 19 tusind rubler. og højere, hvilket garanterer et resultat med en sandsynlighed på 0,954.
|
n= 100 mennesker N= 1000 mennesker
|
Løsning: at bestemme intervallet for andelen af arbejdere med en månedlig indkomst på 19 tusind rubler. og ovenfor er det nødvendigt at kende værdien af den marginale fejl ved stikprøven af andelen Den marginale stikprøvefejl bestemmes af formlen Da P = 0,954, så (ifølge tabel 8.2) t= 2. Der blev foretaget et tilfældigt ikke-gentaget valg ifølge tabellen. 8.3 vælger vi en formel til at beregne den gennemsnitlige stikprøvefejl for en andel:
Prøveandelen bestemmes af forholdet mellem antallet af enheder med det undersøgte træk m til det samlede antal enheder i prøven n, eller Så er den gennemsnitlige brøkfejl At vide t og bestemme værdien af den marginale stikprøvefejl for andelen: Derefter intervallet for andelen af arbejdere med en månedlig indkomst på 19 tusind rubler. og højere i den generelle befolkning vil være som følger:
|

 og andelen af arbejdere med en sådan gennemsnitlig månedlig indkomst ifølge stikprøven W.
og andelen af arbejdere med en sådan gennemsnitlig månedlig indkomst ifølge stikprøven W. ... Det afhænger af værdien af tillidskoefficienten t og gennemsnitlig prøveudtagningsfejl.
... Det afhænger af værdien af tillidskoefficienten t og gennemsnitlig prøveudtagningsfejl. , hvor W- andelen af arbejdere i virksomheden med en gennemsnitlig månedlig indkomst på 19 tusind rubler. og højere i stikprøven.
, hvor W- andelen af arbejdere i virksomheden med en gennemsnitlig månedlig indkomst på 19 tusind rubler. og højere i stikprøven. .
. .
.Svar: andelen af arbejdere i virksomheden med en månedlig indkomst på 19 tusind rubler. og højere, med en sandsynlighed på 0,954, er den i området fra 19,4 % til 36,6 %.
Lad os bestemme den krævede størrelse af prøven, når vi bestemmer den gennemsnitlige månedlige indkomst for ansatte i virksomheden, så den marginale prøveudtagningsfejl med en sandsynlighed på 0,954 ikke overstiger 200 rubler.
|
N= 1000 mennesker |
Løsning: den nødvendige størrelse af stikprøven for at bestemme den gennemsnitlige månedlige indkomst bestemmes af formlen (ifølge tabel 8.4): Ved problemets tilstand er det kendt: for sandsynligheden P = 0,954 t= 2 (se tabel 8.2); 0,2 tusind rubler;
|
 (ifølge dataene fra den foregående prøve).
(ifølge dataene fra den foregående prøve). mennesker
menneskerSvar: For at den marginale prøveudtagningsfejl ikke overstiger 200 rubler med en sandsynlighed på 0,954, bør 189 personer undersøges.
4.5. Bestemmelse af prøvestørrelsen
Proceduren for prøveudtagningsplanen omfatter konsekvent løsning af følgende tre opgaver:
Bestemmelse af forskningsobjektet;
Bestemmelse af prøvestrukturen;
Bestemmelse af prøvestørrelsen.
Som regel, genstand for markedsføringsforskning er en samling af observationsobjekter, som kan være forbrugere, virksomhedsansatte, mellemmænd mv. Hvis denne population er så lille, at forskergruppen har de nødvendige arbejds-, økonomiske og tidsmæssige muligheder for at etablere kontakt til hver af dens elementer, så er det sagtens muligt at foretage en kontinuerlig undersøgelse af hele befolkningen. I dette tilfælde, efter at have identificeret genstanden for forskningen, kan du fortsætte til følgende procedure (valget af metoden til dataindsamling, forskningsværktøj og metode til kommunikation med publikum).
Men i praksis er det meget ofte ikke muligt eller tilrådeligt at foretage en kontinuerlig undersøgelse af hele befolkningen. Der kan være følgende årsager til dette:
Manglende evne til at etablere kontakt med nogle elementer af aggregatet;
Urimeligt høje omkostninger til at gennemføre en kontinuerlig undersøgelse eller tilstedeværelsen af økonomiske restriktioner, der ikke tillader gennemførelse af en kontinuerlig undersøgelse;
Den korte tid, der er afsat til undersøgelsen, på grund af tab over tid af relevansen af information eller andre årsager, og tillader ikke indsamling, systematisering og analyse af omfattende data for hele befolkningen.
Derfor studeres store og spredte populationer ofte ved hjælp af en stikprøve, som er kendt for at betyde en del af populationen designet til at repræsentere befolkningen som helhed.
Den præcision, hvormed en stikprøve afspejler befolkningen som helhed, afhænger af struktur og stikprøvestørrelse.
Der er to tilgange til prøvedesign- probabilistisk og deterministisk.
Probabilistisk tilgang til prøvedesign antager, at et hvilket som helst element i populationen kan udvælges med en vis (ikke nul) sandsynlighed. Der er forskellige typer prøver baseret på sandsynlighedsteori (typisk, indlejret osv.). Den enkleste og mest almindelige i praksis er simpel stikprøveudtagning, hvor hvert element i befolkningen har lige stor sandsynlighed for at blive udvalgt til forskning.
Sandsynlighedsprøvetagning er mere præcis, den giver forskeren mulighed for at vurdere graden af pålidelighed af de data, han har indsamlet, selvom det er mere kompliceret og dyrere end det deterministiske.
Deterministisk tilgang til prøvestrukturen forudsætter, at udvælgelsen af befolkningens elementer foretages ved metoder, der er baseret enten på bekvemmelighedshensyn, eller på forskerens beslutning eller på kontingentgrupper.
af bekvemmelighedsgrunde, består i valget af alle elementer i sættet baseret på, hvor let det er at etablere kontakt med dem. Ufuldkommenheden af denne metode skyldes muligvis den lave repræsentativitet af den opnåede prøve, da elementer af aggregatet, der er bekvemt for forskeren, kan være utilstrækkeligt karakteristiske repræsentanter for aggregatet på grund af deres ikke-tilfældige og uberettigede udvælgelse.
Men på den anden side har enkelheden, omkostningseffektiviteten og effektiviteten af den forskning, der udføres ved denne metode, vundet den ret udbredt i praksis og frem for alt under forundersøgelser med det formål at afklare hovedproblemerne.
Prøvemetode baseret på forskerens beslutning, består i at vælge elementerne i sættet, som efter hans mening er dets karakteristiske repræsentanter. Denne metode er mere perfekt end den forrige, da den er baseret på en orientering mod de karakteristiske repræsentanter for den undersøgte befolkning, selvom de er udvalgt på grundlag af forskernes subjektive ideer om det.
Prøveudtagningsmetode baseret på kontingentsatser, består i valget af karakteristiske elementer i sættet i overensstemmelse med de tidligere opnåede karakteristika for sættet som helhed. Disse karakteristika kan opnås gennem forundersøgelser og er i modsætning til den tidligere metode ikke subjektive. Derfor er denne metode mere perfekt, den giver dig mulighed for at opnå stikprøverammer, der ikke er mindre repræsentative end probabilistiske prøver til meget lavere omkostninger ved at udføre en undersøgelse.
Efter at have valgt strukturen af prøven (tilgangen til dens dannelse, typen af probabilistisk eller tænkt på dannelsen af en deterministisk prøve), skal forskeren bestemme volumenet, dvs. antallet af elementer i prøven.
Prøvestørrelse bestemmer oplysningernes pålidelighed, opnået som resultat af sin forskning, samt de omkostninger, der er nødvendige for at udføre forskningen. Prøvestørrelsen afhænger på niveauet for homogenitet eller variation af de undersøgte objekter.
Jo større stikprøvestørrelsen er, jo højere er dens nøjagtighed og jo større omkostninger ved at gennemføre undersøgelsen. Med en probabilistisk tilgang til strukturen af prøven kan dens størrelse bestemmes ved hjælp af velkendte statistiske formler, baseret på de specificerede krav til dens nøjagtighed.
I praksis bruges flere metoder til at bestemme stikprøvestørrelsen:
1. Vilkårlig tilgang baseret på anvendelsen af "tommelfingerreglen". For eksempel antages det uden bevis, at stikprøven skal være 5 % af populationen for at opnå nøjagtige resultater. Denne tilgang er enkel og nem at implementere, men det er ikke muligt at fastslå nøjagtigheden af de opnåede resultater. Med en tilstrækkelig stor befolkning kan det også være ret dyrt.
Prøvestørrelsen kan indstilles baseret på nogle på forhånd aftalte betingelser. For eksempel ved en kunde af en marketingundersøgelse, at når han studerer den offentlige mening, er stikprøven normalt 1000-1200 personer, så han anbefaler, at forskeren holder sig til dette tal. Hvis der udføres årlige undersøgelser på et bestemt marked, anvendes et stikprøve af samme størrelse hvert år. I modsætning til den første tilgang anvendes her ved bestemmelse af stikprøvestørrelsen en velkendt logik, som dog er meget sårbar.
For eksempel kan det kræve mindre nøjagtighed at udføre visse undersøgelser, end når man studerer den offentlige mening, og befolkningens størrelse kan være mange gange mindre, end når man studerer den offentlige mening. Denne tilgang tager således ikke højde for de nuværende forhold og kan være ret dyr.
I nogle tilfælde bruges omkostningerne ved undersøgelsen som hovedargumentet ved bestemmelse af stikprøvestørrelsen. Markedsundersøgelsesbudgettet dækker således udgifterne til visse undersøgelser, som ikke må overskrides. Der tages naturligvis ikke hensyn til værdien af de modtagne oplysninger. Men i nogle tilfælde kan selv en lille prøve give ret nøjagtige resultater.
Det forekommer klogt at overveje omkostningerne ikke i absolutte tal, men i forhold til nytten af oplysningerne fra undersøgelserne. Klienten og forskeren bør overveje forskellige stikprøvestørrelser og metoder til dataindsamling, omkostninger, tage hensyn til andre faktorer
2. Stikprøvestørrelsen fra niveauet af konfidensintervallet for den tilladte fejl, der, som allerede nævnt, er sat af den passende nøjagtighed af de endelige generaliseringer: fra øget til omtrentlig. Men her mener vi de såkaldte tilfældige fejl forbundet med arten af eventuelle statistiske fejl. Det er dem, der beregnes som repræsentativitetsfejl af sandsynlighedsprøver.
V. I. Paniotto giver følgende beregninger af en repræsentativ prøve med en 5 % fejl (tabel 4.2).
Tabel 4.2
Eksempel på beregningstabel
For en befolkning på mere end 100.000 er stikprøven 400 enheder. Hvis vi har generelle befolkninger på 5 tusinde og mere i tankerne, så er det ifølge beregningerne af samme forfatter muligt at angive størrelsen af den faktiske prøveudtagningsfejl afhængigt af dens størrelse, hvilket er meget vigtigt for os, huske på, at størrelsen af den tilladte fejl afhænger af målforskningen og ikke behøver at være tæt på 5 procent-niveauet.
Tabel 4.3
Beregningstabel
Sammen med tilfældige fejl er systematiske fejl mulige. De afhænger af tilrettelæggelsen af stikprøveundersøgelsen. Disse er forskellige forskydninger af prøven mod en af polerne af den samplede parameter.
3. Prøvestørrelse baseret på statistisk analyse ... Denne tilgang er baseret på at bestemme den mindste stikprøvestørrelse baseret på visse krav til pålideligheden og validiteten af de opnåede resultater. Det bruges også til at analysere de opnåede resultater for individuelle undergrupper dannet i prøven efter køn, alder, uddannelsesniveau osv. Kravene til resultaternes pålidelighed og nøjagtighed for individuelle undergrupper dikterer visse krav til stikprøvestørrelsen som helhed.
Den mest teoretisk funderede og korrekte tilgang til at bestemme stikprøvestørrelsen er baseret på beregningen af pålidelige intervaller. Variationsbegrebet karakteriserer mængden af ulighed (lighed) i respondenternes svar på et bestemt spørgsmål. Mere stringent er variationen i værdierne af en funktion i et sæt forskellen i dens værdier for forskellige enheder af et givet sæt på samme periode eller tidspunkt. Resultaterne af svarene på undersøgelsesspørgsmålene præsenteres normalt i form af en fordelingskurve (fig. 4.1). Med en høj lighed af svar taler man om en lille variation (smal fordelingskurve) og med en lav lighed af svar en høj variation (bred fordelingskurve).
Som et mål for variation tages normalt standardafvigelsen, som karakteriserer den gennemsnitlige afstand fra den gennemsnitlige vurdering af hver respondents svar til et bestemt spørgsmål.

Lille variation
Høj variation
Ris. 4.1. Variations- og fordelingskurver
Da alle markedsføringsbeslutninger træffes under forhold med usikkerhed, er det tilrådeligt at tage denne omstændighed i betragtning, når stikprøvestørrelsen bestemmes. Da bestemmelsen af de undersøgte værdier for en population i en snæver en er udført på grundlag af stikprøvestatistik, er det nødvendigt at etablere det interval (konfidensinterval), hvor estimaterne for populationen som helhed forventes at falde, og fejlen i deres bestemmelse.
Et konfidensinterval er et interval, hvis yderpunkter svarer til en vis procentdel af bestemte svar på et spørgsmål. Konfidensintervallet er tæt forbundet med standardafvigelsen af det undersøgte træk i den generelle befolkning: Jo større det er, jo bredere skal konfidensintervallet være for at inkludere en vis procentdel af svarene.
Et konfidensinterval på enten 95 % eller 99 % er standard i marketingundersøgelser. Intet firma udfører marketingundersøgelser ved hjælp af flere prøver. Og matematisk statistik gør det muligt at få nogle oplysninger om stikprøvefordelingen, idet man kun har data om variationen af en enkelt prøve.
En indikator for, i hvor høj grad det estimat, der er sandt for populationen som helhed, adskiller sig fra det estimat, der forventes for en typisk stikprøve, er rod-middel-kvadrat-fejlen. Desuden, jo større stikprøvestørrelsen er, jo mindre er fejlen. En høj værdi af variation resulterer i en høj værdi af fejl og omvendt.
Når der kun er to mulige svar på et spørgsmål, udtrykt i procent (anvendt procent), bestemmes stikprøvestørrelsen af følgende formel:

hvor n er stikprøvestørrelsen; z - normaliseret afvigelse, bestemt baseret på det valgte konfidensniveau; p er den fundne variation for prøven; g - (100-p); e er en acceptabel fejl.
Når man bestemmer indikatoren for variation for en bestemt befolkning, er det først og fremmest tilrådeligt at udføre en foreløbig kvalitativ analyse af den undersøgte befolkning, først og fremmest for at fastslå ligheden mellem befolkningens enheder i demografiske, sociale og andre henseender. er af interesse for forskeren. Det er muligt at udføre en pilotundersøgelse, brug resultaterne af lignende undersøgelser udført i fortiden. Ved brug af det procentvise mål for variabilitet tages der højde for, at den maksimale variabilitet opnås for p = 50 %, hvilket er det værste tilfælde. Desuden påvirker denne indikator ikke stikprøvestørrelsen radikalt. Der tages også hensyn til undersøgelsens kundes mening om stikprøvestørrelsen.
Det er muligt at bestemme stikprøvestørrelsen ud fra brugen af gennemsnit frem for procenter.

hvor s er standardafvigelsen.
I praksis, hvis stikprøven er omdannet, og lignende undersøgelser ikke er blevet udført, så kendes s ikke. I dette tilfælde er det tilrådeligt at indstille fejlen e i brøkdele af standardafvigelsen. Beregningsformlen omdannes og har følgende form:
 hvor
hvor  .
.
Ovenfor talte vi om meget store aggregater. I nogle tilfælde er bestandene dog ikke store. Typisk, hvis stikprøven er mindre end fem procent af populationen, anses populationen for at være stor, og beregningerne foretages i henhold til ovenstående regler. Hvis stikprøvestørrelsen overstiger 5 % af populationen, betragtes sidstnævnte som lille, og der indføres en korrektionsfaktor i ovenstående formler.
Prøvestørrelsen i dette tilfælde bestemmes som følger:
 ,
,
Praktisk arbejde nr. 8. "Bestemmelse af den nødvendige stikprøvestørrelse"
"Bestemmelse af den nødvendige stikprøvestørrelse"
Den mest udbredte form for ikke-kontinuerlig observation er selektiv observation, hvor ikke alle enheder af den undersøgte befolkning er undersøgt, men kun en del af dem udvalgt på en bestemt måde.
Hele sættet af objekter (observationer), der skal studeres, kaldes almindelig befolkning. Prøvepopulation eller stikprøve er den del af den almindelige befolkning udvalgt til undersøgelse af ejendomme, der giver repræsentativitet.
Udvælgelse fra den generelle befolkning udføres på en sådan måde, at der på grundlag af stikprøven kan opnås en tilstrækkelig nøjagtig idé om hovedparametrene for befolkningen som helhed. I dette tilfælde taler vi både om et punktestimat, der tages som den tilsvarende værdi af gennemsnittet, aktien osv., opnået som resultat af stikprøven, og om et intervalestimat, dvs. om de grænser, inden for hvilke, med en vis sandsynlighed, værdien af den ønskede parameter i den almindelige befolkning kan ligge. Hovedkravet, som en stikprøvepopulation skal opfylde, er kravet til dens repræsentativitet, dvs. repræsentativitet.
I statistikker vurderes resultaterne af kontinuerlig observation nogle gange som prøvekarakteristika. Denne fortolkning af de opnåede data finder sted i tilfælde, hvor antallet af undersøgte enheder er lille, og der ikke er nogen sikker tillid til, at de undersøgte karakteristika ikke kan antage andre værdier end dem, der er identificeret som følge af observation. Når du udfører eksperimenter, kan antallet af værdier være uendeligt stort, derfor er det nødvendigt at formulere konklusioner baseret på et begrænset antal af dem, at betragte de opnåede data som prøvekarakteristika.
Når resultaterne af en stikprøveundersøgelse udvides til den brede befolkning, skal man huske på, at der kan være en uoverensstemmelse mellem karakteristikaene for den generelle befolkning og stikprøvepopulationen, fordi ikke hele populationen er undersøgt, men kun en del af det.
Statistisk observationsfejl værdien af afvigelsen mellem de beregnede og faktiske værdier af funktionerne i de undersøgte objekter tages i betragtning.
Den selektive metode giver betydelige besparelser i materielle og økonomiske ressourcer ved udførelse af statistisk observation, hvilket gør det muligt at udvide undersøgelsesprogrammet og øge dets effektivitet. Den anden fordel er den høje pålidelighed af de opnåede data, da der med en relativt lille stikprøvestørrelse kan organiseres effektiv kontrol over kvaliteten af den indsamlede information. Således reduceres sandsynligheden for registreringsfejl og deres manglende opdagelse på tidspunktet for kontrol af den primære information. Og endelig, i en række tilfælde, hvor kontinuerlig overvågning er forbundet med ødelæggelse eller beskadigelse af de undersøgte enheder (for eksempel ved kontrol af kvaliteten af fødevareprodukter til salg), er kun en stikprøveundersøgelse mulig.
Nøjagtigheden af estimater opnået på grundlag af stikprøvemetoden afhænger ikke af andelen af undersøgte enheder, men af deres antal.
De vigtigste stadier af selektiv observation;
1) at definere mål, mål og udarbejde et overvågningsprogram;
2) prøveudtagning;
3) dataindsamling baseret på det udviklede program;
4) analyse af de opnåede resultater og beregning af de vigtigste karakteristika for prøvepopulationen;
5) beregning af stikprøvefejlen og fordelingen af dens resultater til den generelle befolkning.
Skelne prøveudtagningstyper:
1) tilfældig(faktisk tilfældigt);
2) mekanisk(for eksempel hver 10., 20. osv.);
3) typisk (stratificeret), når den generelle befolkning er opdelt i grupper og flere objekter undersøges i hver gruppe));
4) seriel (indlejring), når hele serier er tilfældigt udvalgt.
Den enkleste måde at danne en prøve på er korrekt tilfældig udvælgelse. Det teoretiske grundlag for stikprøvemetoden, der oprindeligt er udviklet i forhold til korrekt stikprøveudtagning, bruges også til at bestemme stikprøvefejl for andre observationsmetoder.
Faktisk kan tilfældig udvælgelse gentages og ikke gentages. På gentaget Ved udvælgelse vender hver enhed, udvalgt tilfældigt fra den almindelige befolkning, efter observation, tilbage til denne population og kan undersøges igen. I praksis er denne udvælgelsesmetode sjælden. Meget mere almindeligt er faktisk tilfældigt ikke gentagelig udvælgelse, hvor de undersøgte enheder ikke vender tilbage til den almindelige befolkning og ikke kan re-undersøgt. Ved re-sampling forbliver sandsynligheden for at blive udtaget for hver enhed af populationen uændret. Når stikprøven tages uden gentagelse, ændres den, men for alle enheder, der forbliver i den generelle population efter at have valgt flere enheder fra den, er sandsynligheden for at blive inkluderet i stikprøven den samme.
Befolkninger er ofte holdt blandt store grupper af mennesker. Det er ofte en misforståelse, at pålideligheden af resultaterne vil være højere, hvis hvert medlem af samfundet besvarer spørgsmålene. På grund af den enorme tid, penge og arbejdsintensitet er en sådan undersøgelse uacceptabel. I takt med at antallet af respondenter vokser, vil omkostningerne ikke kun stige, men risikoen for at modtage forkerte data vil også stige. Fra et praktisk synspunkt vil mange spørgeskemaer og kodere reducere sandsynligheden for pålidelig overvågning af deres handlinger. Sådan en undersøgelse kaldes kontinuerlig.
I sociologien er diskontinuerlig forskning, eller prøveudtagningsmetoden, oftest brugt. Dens resultater kan udvides til en stor gruppe mennesker, som kaldes generel.
Definition og betydning af prøveudtagning
Prøveudtagningsmetoden er en kvantitativ måde at udvælge en del af de undersøgte enheder fra den samlede masse, mens undersøgelsesresultaterne også vil gælde for hver enkelt person, der ikke har deltaget heri.
Den selektive metode er både et genstand for videnskabelig forskning og en akademisk disciplin. Det fungerer som et middel til at opnå pålidelig information om den generelle befolkning og hjælper med at vurdere alle dens parametre. Betingelserne for udvælgelsen af enheder påvirker efterfølgende den statistiske analyse af resultaterne. Hvis de selektive procedurer udføres dårligt, vil brugen af selv de mest pålidelige metoder til behandling af de indsamlede oplysninger være ubrugelige.

Nøglebegreber for valgteori
Enheders indbyrdes sammenhæng kaldes, i forhold til hvilken stikprøveundersøgelsens konklusioner formuleres. Det kan være indbyggere i et land, en bestemt bygd, en virksomheds arbejdskollektiv osv.
Stikprøvepopulationen (eller stikprøven) er en del af den generelle befolkning, som er udvalgt ved hjælp af særlige metoder og kriterier. For eksempel tages statistiske kriterier i betragtning i dannelsesprocessen.
Antallet af individer inkluderet i et bestemt sæt kaldes dets volumen. Men det kan ikke kun udtrykkes ved antallet af mennesker, men også af valgsteder, bebyggelser, det vil sige bestemt af store enheder, der inkluderer observationsenheder. Men dette er allerede en flertrins prøvetagning.
Udvælgelsesenheden er de konstituerende dele af den almindelige befolkning, de kan enten være direkte observationsenhederne (et-trins prøveudtagning) eller større formationer.
En vigtig rolle i at opnå pålidelige forskningsresultater ved hjælp af prøvetagningsmetoden er en sådan egenskab som selektionens repræsentativitet. Det vil sige, at den del af den generelle befolkning, der er blevet respondenter, fuldt ud skal gengive alle dens karakteristika. Enhver afvigelse betragtes som en fejl.

Stadier af anvendelse af prøveudtagningsmetoden
Hver empiri består af stadier. I tilfælde af brug af prøveudtagningsmetoden vil deres rækkefølge blive bygget op som følger:
- Oprettelse af et prøveprojekt: den generelle befolkning er etableret, udvælgelsesprocedurer, mængder karakteriseres.
- Gennemførelse af projektet: i forbindelse med indsamling af sociologisk information udfører spørgeskemaerne opgaver med angivelse af metoden til udvælgelse af respondenter.
- Identifikation og rettelse af repræsentationsfejl.
Eksempeltyper i sociologi
Efter at have bestemt den generelle befolkning, fortsætter forskeren til selektive procedurer. De kan opdeles efter to typer (kriterier):
- Probabilistiske loves rolle i prøveudtagning.
- Antallet af udvælgelsestrin.
Hvis det første kriterium anvendes, skelnes metoden med tilfældig stikprøve og ikke-tilfældig udvælgelse. Baseret på sidstnævnte kan der argumenteres for, at prøven kan være enkelt- eller flertrins.
Prøvetyperne afspejles direkte ikke kun på stadierne af forberedelse og gennemførelse af undersøgelsen, men også på dens resultater. Før du giver fortrinsret til en af dem, bør du forstå indholdet af begreberne.
Definitionen af "tilfældig" i hverdagen har fået en fuldstændig modsat betydning end i matematik. En sådan udvælgelse udføres i henhold til strenge regler, ingen afvigelse fra dem er tilladt, da det er vigtigt at sikre, at hver enhed i den generelle befolkning har samme chancer for at blive inkluderet i stikprøven. Hvis disse betingelser ikke er opfyldt, vil denne sandsynlighed være anderledes.
Til gengæld er den tilfældige prøve opdelt i:
- enkel;
- mekanisk (systematisk);
- indlejret (seriel, klynge);
- stratificeret (typisk eller regionaliseret).
En simpel stikprøvemetode udføres ved hjælp af en tabel med tilfældige tal. Prøvestørrelsen bestemmes indledningsvis; der oprettes en komplet liste over nummererede respondenter fra den almindelige befolkning. Brugt til udvælgelse er specielle tabeller indeholdt i matematiske og statistiske publikationer. Alt andet end dem er forbudt at bruge. Hvis stikprøvestørrelsen er et trecifret tal, skal antallet af hver stikprøveenhed være trecifret, nemlig: fra 001 til 790. Det sidste tal refererer til det samlede antal personer. Undersøgelsen vil involvere de personer, der har fået tildelt et nummer i det specificerede interval, som findes i tabellen.

Systematisk udvælgelse er baseret på beregninger. En alfabetisk liste over alle elementer i den generelle befolkning er foreløbigt kompileret, trinnet er sat, og først derefter er stikprøvestørrelsen. Formlen for trinnet præsenteres som følger:
N: n, hvor N er populationen og n er stikprøven.
Eksempelvis 150.000: 5.000 = 30. Således vil hver 30. person blive udvalgt til at deltage i undersøgelsen.
Indlejret enhed
Redeprøvetagningen bruges under forhold, hvor populationen af personer, der undersøges, består af små naturlige grupper i forhold til antallet af naturlige grupper. I dette tilfælde skal det tages i betragtning, at i det første trin bestemmes listeantallet af sådanne reder. Ved hjælp af en tabel med tilfældige tal foretages en udvælgelse og en løbende undersøgelse af alle respondenter i hver udvalgt rede. Desuden, jo flere af dem, der deltog i undersøgelsen, jo mindre var den gennemsnitlige stikprøvefejl. Det er dog muligt at bruge en sådan teknik, hvis der er et lignende træk i de undersøgte reder.
Essensen af stratificeret valg
Den stratificerede prøve adskiller sig fra de foregående ved, at den generelle befolkning på tærsklen til udvælgelsen er opdelt i strata, det vil sige homogene dele, der har et fælles træk. For eksempel uddannelsesniveauet, valgpræferencer, niveauet af tilfredshed med forskellige aspekter af livet. Den enkleste mulighed er at opdele emnerne efter køn og alder. I princippet er det nødvendigt at udføre udvælgelsen på en sådan måde, at der fra hvert stratum tildeles et antal personer, proportionalt med det samlede antal.
Stikprøvestørrelsen kan i dette tilfælde være mindre end i situationen med stikprøver, men repræsentativiteten vil være højere. Det skal indrømmes, at en stratificeret stikprøve vil være den dyreste med hensyn til finansielle og informationsmæssige ressourcer, og en klyngeprøve vil være den mest rentable i denne henseende.

Ikke-tilfældig kvoteprøve
Der er også en kvoteprøve. Det er den eneste form for ikke-tilfældig udvælgelse, der har et matematisk grundlag. Kvoteprøven er dannet af enheder, der skal præsenteres i proportioner og svare til den generelle befolkning. På denne måde gennemføres den målrettede fordeling af egenskaber. Hvis blandt de undersøgte funktioner er meninger og vurderinger af mennesker, så er kvoterne ofte køn, alder, uddannelse af respondenterne.
I en sociologisk undersøgelse skelnes der også mellem to typer selektion: gentaget og ikke-gentaget. I første omgang vender den valgte enhed efter undersøgelsen tilbage til den generelle befolkning for yderligere at deltage i udvælgelsen. I den anden mulighed sorteres respondenterne, hvilket øger chancerne for, at resten af befolkningen bliver udvalgt.
Sociolog G.A. Churchill udviklede følgende regel: stikprøvestørrelsen skal stræbe efter at give mindst 100 observationer for den primære og 20-50 for den sekundære klassifikationskomponent. Man skal huske på, at nogle af de respondenter, der indgår i stikprøven, af forskellige årsager muligvis ikke deltager i undersøgelsen eller helt afviser den.

Metoder til bestemmelse af prøvestørrelsen
Følgende metoder er anvendelige i sociologisk forskning:
1. Vilkårlig, dvs. stikprøvestørrelsen bestemmes inden for 5-10 % af den generelle befolkning.
2. Den traditionelle beregningsmetode er baseret på regelmæssige undersøgelser, for eksempel én gang årligt med dækning af 600, 2.000 eller 2.500 respondenter.
3. Statistisk - er at fastslå pålideligheden af oplysninger. Statistik som videnskab udvikler sig ikke isoleret. Fagene og områderne for hendes forskning er aktivt involveret i andre relaterede industrier: tekniske, økonomiske og humanitære. Så dets metoder bruges i sociologi, som forberedelse til undersøgelser og især til at bestemme størrelsen af prøver. Statistik som videnskab har et omfattende metodologisk grundlag.
4. Dyrt, hvor det tilladte beløb for forskningsomkostninger er fastsat.
5. Stikprøvestørrelsen kan være lig med antallet af enheder i den generelle befolkning, så vil undersøgelsen være kontinuerlig. Denne tilgang er anvendelig i små grupper. Eksempelvis arbejdsstyrken, studerende mv.
Tidligere var det muligt at fastslå, at en stikprøve vil blive betragtet som repræsentativ, når dens karakteristika beskriver egenskaberne for den generelle befolkning med et minimum af fejl.
Estimatet af stikprøvestørrelsen går forud for den endelige beregning af antallet af enheder, der skal trækkes fra populationen:
n = Npqt 2: N∆ 2 p + pqt 2, hvor N er antallet af enheder i den almindelige befolkning, p er andelen af det undersøgte træk (q = 1 - p), t er korrespondancekoefficienten for konfidenssandsynlighed P (bestemt i henhold til en speciel tabel), ∆ p er en gyldig fejl.
Dette er blot en variation af, hvordan stikprøvestørrelsen beregnes. Formlen kan ændre sig afhængigt af betingelserne og de valgte forskningskriterier (for eksempel resampling eller ikke-resampling).
Prøveudtagningsfejl
Sociologiske undersøgelser af befolkningen er baseret på brugen af en af de prøvetyper, vi har diskuteret ovenfor. Men under alle omstændigheder bør opgaven for hver forsker være at vurdere graden af nøjagtighed af de opnåede indikatorer, det vil sige, det er nødvendigt at bestemme, hvordan de afspejler karakteristikaene for den generelle befolkning.
Prøveudtagningsfejl kan opdeles i tilfældige og ikke-tilfældige. Den første type indebærer afvigelsen af stikprøveindikatoren fra den generelle, som kan udtrykkes ved forskellen i deres andele (gennemsnit), og som kun er forårsaget af en ikke-kontinuerlig type undersøgelse. Og det er helt naturligt, hvis denne indikator falder på baggrund af en stigning i antallet af adspurgte.
En systematisk fejl er en afvigelse fra den generelle indikator, også fundet som et resultat af fratrækning af stikprøven og den generelle andel og som følge af uoverensstemmelsen mellem stikprøvemetoden og de etablerede regler.
Disse typer fejl er inkluderet i den generelle stikprøvefejl. I en undersøgelse kan der kun udtages én stikprøve fra populationen. Beregningen af den maksimalt mulige afvigelse af en prøveindikator kan udføres ved hjælp af en speciel formel. Dette kaldes den marginale stikprøvefejl. Der er også sådan noget som den gennemsnitlige prøveudtagningsfejl. Dette er standardafvigelsen for prøven fra den generelle andel.
Der er også en a posteriori (efter-oplevelse) type fejl. Det betyder stikprøveindikatorernes afvigelse fra den generelle andel (gennemsnit). Den beregnes ved at sammenligne den generelle indikator, information om hvilken kom fra pålidelige kilder og stikprøven, som blev etableret under undersøgelsen. Som pålidelige informationskilder er ofte virksomhedernes personaleafdelinger, statslige statistiske organer.
Der er også en a priori fejl, som også er stikprøvens afvigelse og generelle indikatorer, som kan udtrykkes ved forskellen mellem deres andele, og som kan beregnes ved hjælp af en speciel formel.

I pædagogisk forskning begås følgende fejl oftest i forbindelse med udvælgelsen af respondenter til en undersøgelse:
1. Prøvesæt af grupper, der tilhører forskellige generelle grupper. Ved brug af dem udvikles statistiske konklusioner, der gælder for hele stikprøven. Dette kan naturligvis ikke accepteres.
2. Forskerens organisatoriske og økonomiske formåen tages ikke i betragtning, når prøvetyperne tages i betragtning, og en af dem foretrækkes.
3. De statistiske kriterier for den generelle befolknings struktur er ikke fuldt ud brugt til at forhindre stikprøvefejl.
4. Krav til repræsentativitet af udvælgelsen af respondenter i løbet af sammenlignende undersøgelser tages ikke i betragtning.
5. Instruktioner til intervieweren bør tilpasses under hensyntagen til de særlige forhold ved den valgte type udvælgelse.
Karakteren af respondenternes deltagelse i undersøgelsen kan være åben eller anonym. Dette bør tages i betragtning ved udvælgelsen af stikprøven, da deltagere kan falde fra, hvis de er uenige i vilkårene og betingelserne.
Det samlede antal observationsobjekter (mennesker, husholdninger, virksomheder, bosættelser osv.) med et bestemt sæt karakteristika (køn, alder, indkomst, antal, omsætning osv.), begrænset i rum og tid. Eksempler på populationer
- Alle indbyggere i Moskva (10,6 millioner mennesker ifølge folketællingen i 2002)
- Moskovitiske mænd (4,9 millioner mennesker ifølge folketællingen i 2002)
- Juridiske enheder i Rusland (2,2 millioner i begyndelsen af 2005)
- Detailforretninger, der sælger fødevarer (20 tusind i begyndelsen af 2008) osv.
Prøve (prøvepopulation)
En del af objekterne fra den almene befolkning udvalgt til undersøgelse med henblik på at lave en konklusion om hele den generelle befolkning. For at den konklusion, der opnås ved at undersøge stikprøven, kan udvides til at omfatte hele den generelle befolkning, skal stikprøven have egenskaben af repræsentativitet.
Prøvens repræsentativitet
En prøves egenskab til korrekt at afspejle den generelle befolkning. Den samme stikprøve kan være repræsentativ og ikke-repræsentativ for forskellige populationer.
Eksempel:
- Stikprøven, der udelukkende består af muskovitter, der ejer en bil, repræsenterer ikke hele Moskvas befolkning.
- Stikprøven af russiske virksomheder med op til 100 personer repræsenterer ikke alle virksomheder i Rusland.
- Stikprøven af muskovitter, der foretager indkøb på markedet, repræsenterer ikke alle muskovitters købsadfærd.
Samtidig kan de angivne prøver (med forbehold for andre betingelser) perfekt repræsentere henholdsvis Moskovitter-bilejere, små og mellemstore russiske virksomheder og købere, der køber på markederne.
Det er vigtigt at forstå, at stikprøvens repræsentativitet og stikprøvefejl er forskellige fænomener. Repræsentativitet, i modsætning til fejl, afhænger ikke på nogen måde af stikprøvestørrelsen.
Eksempel:
Uanset hvordan vi øger antallet af adspurgte muskovitter-bilejere, vil vi ikke være i stand til at repræsentere alle muskovitter med denne prøve.
Sampling fejl (konfidensinterval)
Afvigelsen af resultaterne opnået ved hjælp af selektiv observation fra de sande data fra den generelle befolkning.
Der er to typer stikprøvefejl - statistiske og systematiske. Den statistiske fejl afhænger af stikprøvestørrelsen. Jo større stikprøvestørrelsen er, jo lavere er den.
Eksempel:
For en simpel tilfældig stikprøve på 400 enheder er den maksimale statistiske fejl (med et 95% konfidensniveau) 5%, for en stikprøve på 600 enheder - 4%, for en stikprøve på 1100 enheder - 3% Normalt, når folk taler om prøveudtagningsfejl, de betyder den statistiske fejl ...
Bias afhænger af forskellige faktorer, der har en permanent indvirkning på undersøgelsen og skævvrider undersøgelsens resultater i en bestemt retning.
Eksempel:
- Brug af en hvilken som helst sandsynlighedsprøve undervurderer andelen af højindkomstpersoner med aktiv livsstil. Dette sker på grund af det faktum, at sådanne mennesker er meget sværere at finde på et bestemt sted (for eksempel derhjemme).
- Problemet med respondenter, der nægter at besvare spørgsmål (andelen af "afvisninger" i Moskva, for forskellige meningsmålinger, varierer fra 50% til 80%)
I nogle tilfælde, når de sande fordelinger er kendt, kan skævheden neutraliseres ved at indføre kvoter eller genvægte dataene, men i de fleste virkelige studier kan det være ret problematisk overhovedet at estimere det.
Prøvetyper
Prøver er opdelt i to typer:
- sandsynligt
- usandsynlig
1. Sandsynlighedsprøver
1.1 Tilfældig stikprøve (simpel tilfældig stikprøve)
En sådan prøve antager homogeniteten af den generelle befolkning, den samme sandsynlighed for tilgængelighed af alle elementer, tilstedeværelsen af en komplet liste over alle elementer. Ved valg af elementer anvendes som regel en tabel med tilfældige tal.
1.2 Mekanisk (systematisk) prøveudtagning
En slags tilfældig stikprøve, ordnet efter et eller andet kriterium (alfabetisk rækkefølge, telefonnummer, fødselsdato osv.). Det første element vælges tilfældigt, og derefter, i trin på 'n', vælges hvert 'k'te element. Størrelsen af den generelle befolkning, mens - N = n * k
1.3 Stratificeret (zoneinddelt)
Det bruges i tilfælde af heterogenitet i den generelle befolkning. Den almindelige befolkning er opdelt i grupper (lag). I hvert stratum udføres udvælgelsen tilfældigt eller mekanisk.
1.4 Seriel (indlejret eller klynget) prøveudtagning
Ved seriel sampling er udvælgelsesenhederne ikke selve objekterne, men grupper (klynger eller reder). Grupper er tilfældigt udvalgt. Objekter inden for grupperne undersøges i fast form.
2 usandsynlig prøveudtagning
Udvælgelse i en sådan prøve udføres ikke i henhold til principperne om tilfældighed, men efter subjektive kriterier - tilgængelighed, typiskhed, lige repræsentation osv.
2.1. Kvoteprøveudtagning
I første omgang tildeles et vist antal grupper af objekter (for eksempel mænd i alderen 20-30 år, 31-45 år og 46-60 år; personer med en indkomst på op til 30 tusind rubler med en indkomst på 30 til 60 tusind rubler og en indkomst på over 60 tusind rubler ) For hver gruppe indstilles antallet af genstande, der skal undersøges. Antallet af objekter, der skal falde ind i hver af grupperne, fastsættes oftest enten i forhold til den tidligere kendte andel af gruppen i den almindelige befolkning, eller det samme for hver gruppe. Inden for grupperne vælges objekter tilfældigt. Kvoteprøver bruges ret ofte.
2.2. Snebold metode
Prøven er konstrueret som følger. Hver respondent, begyndende med den første, bliver bedt om kontakter til sine venner, kolleger, bekendte, som ville passe til udvælgelsesbetingelserne og kunne deltage i undersøgelsen. Med undtagelse af det første trin dannes stikprøven således med deltagelse af selve forskningsobjekterne. Metoden bruges ofte, når det er nødvendigt at finde og interviewe svært tilgængelige grupper af respondenter (f.eks. respondenter med høj indkomst, respondenter, der tilhører samme faggruppe, respondenter med lignende hobbyer/hobbyer osv.)
2.3 Spontan prøveudtagning
De mest tilgængelige respondenter bliver interviewet. Typiske eksempler på spontan prøveudtagning er i aviser/magasiner, givet til respondenter til selvudfyldelse, de fleste internetundersøgelser. Størrelsen og sammensætningen af spontane prøver kendes ikke på forhånd og bestemmes kun af én parameter - respondenternes aktivitet.
2.4 Eksempel på typiske tilfælde
Enheder af den generelle befolkning vælges, der har den gennemsnitlige (typiske) værdi af egenskaben. Dette rejser problemet med at vælge en funktion og bestemme dens typiske værdi.
Forelæsningsforløb om statistikteori
Mere detaljerede oplysninger om prøveobservationer kan fås ved at se.
Beregning af prøvestørrelse
Af alle de spørgsmål, der bliver stillet til personalet på det berømte Gallup Institute for Public Opinion, er det mest populære dette: hvordan kan du, efter at have interviewet 1.000 mennesker, bedømme, hvad 250 millioner amerikanere mener?
For at besvare dette spørgsmål bør man ikke kun nævne medarbejdernes høje kvalifikationer og store praktiske erfaring, men også deres brug af statistik og matematik. Hvis dine undersøgelsesmetoder ikke er baseret på videnskab, kan resultaterne være vildledende.
I statistikker er følgende afgrænsning af stikprøvestørrelser vedtaget. Stikprøvestørrelsen, tilstrækkelig til gensidig annullering af ulykker og opnåelse af statistiske karakteristika af regulær karakter, er lig med 30. En stikprøve af denne størrelse kaldes lille. Arten af fordelingen af værdierne af karakteristikken i små prøver nærmer sig normal med en stigning i antallet af forsøg. Den mindste prøvestørrelse, der giver dig mulighed for at få gennemsnitsværdierne af attributten med angivelse af tillidssandsynligheder, er 5. Prøver af denne størrelse kaldes ultra-lille. Fordelingen af karakteristiske værdier i sådanne prøver er karakteriseret ved elevens fordeling. Men oftest i sociologi beskæftiger de sig med en meget større stikprøvestørrelse.
Når man planlægger en stikprøveundersøgelse, kommer der et tidspunkt, hvor det er nødvendigt at beslutte, hvor mange personer, der skal interviewes, dvs. hvad prøvestørrelsen skal være. Denne beslutning er ekstremt vigtig, fordi for stor en stikprøve ville være unødvendig, og for lille ville reducere kvaliteten af resultaterne.
Prøvestørrelse- det samlede antal observationsenheder inkluderet i stikprøven.
Da stikprøvepopulationen er en del af den generelle befolkning, udvalgt ved hjælp af specielle metoder, er det vigtigt, at denne del ikke forvrænger ideen om helheden, dvs. repræsenterede det. Sociologer, som ofte udfører empirisk forskning, er konstant bekymrede for, hvor meget en person skal interviewes for at få pålidelig information? Gallup Institute i USA udfører regelmæssige meningsmålinger på en national stikprøve på 1,5 tusinde mennesker og opnår en forbløffende nøjagtighed (prøveudtagningsfejl varierer fra 1 til 1,5%). Socio-Express Center for Institut for Sociologi ved Det Russiske Videnskabsakademi udfører forskning på en prøve på 2 tusinde mennesker, mens prøveudtagningsfejlen ikke overstiger 3% 31.
Eksperter mener, at den bedste prøve ikke nødvendigvis er stor. Jo større stikprøvestørrelsen er, jo højere er nøjagtigheden af resultaterne. Selv en stor stikprøve garanterer dog ikke succes, hvis den generelle befolkning er "dårligt blandet", dvs. er heterogen. Homogen et sådant sæt anses for, hvor den kontrollerede funktion er jævnt fordelt, ikke danner hulrum eller kondensering. I dette tilfælde kan du ved at interviewe flere personer få nøjagtige oplysninger om fordelingen af denne funktion i den generelle befolkning.
Repræsentativiteten af dataene påvirkes således ikke af prøvens kvantitative karakteristika (dens volumen), men af den generelle befolknings kvalitative karakteristika - af graden af dens homogenitet.
Sociologien har endnu ikke opfundet en enkelt og klar formel, der kan bruges til at beregne den optimale størrelse af prøvepopulationen – sådan en formel findes simpelthen ikke i naturen. Og dette er forklaret meget enkelt. Faktum er, at bestemmelsen af størrelsen af stikprøvepopulationen ikke er så meget et statistisk problem som et væsentligt. Med andre ord afhænger stikprøvepopulationens størrelse af mange faktorer, herunder målene og formålene, den teoretiske model, hypoteser og forskningsmetoder, graden af homogenitet i den generelle befolkning og endelig den nødvendige nøjagtighed af den modtagne information.
Det skal altid huskes, at hver procentvis stigning i nøjagtigheden af oplysninger i en undersøgelse fører til en kraftig stigning i omkostningerne ved at udføre den. Det berømte Gallup Institute, som har gennemført meningsmålinger i USA i mange årtier, fandt ud af, at med en landsdækkende stikprøve på 100 personer, vil stikprøvefejlen være inden for ± 11 %; 200 personer - ± 8%; 400 - ± 6%; 600 - ± 5%; 750 - ± 4%; 1000 - ± 4%; 1500 - ± 3%; 4000 personer - ± 2%. Derfor laver han landsdækkende meningsmålinger i USA på et udvalg på 1.500-2.000 personer. Som du kan se, foretrækker han en stigning på 1 % i fejl frem for en multipel stigning i forskningsomkostninger.
Praksis viser, at for mange sociologer er begrundelsen for stikprøvestørrelsen en stopklods på trods af den betydelige mængde litteratur om stikprøvemetoder og især beregningen af stikprøvestørrelsen. Der er flere årsager: 1) manglen på specialiseret litteratur i periferien; 2) mangel på tid til selvuddannelse; 3) manglende evne til at bruge det matematiske apparat. I denne henseende bliver det nødvendigt at skitsere strategien og taktikken til at underbygge stikprøvestørrelsen uden komplekse matematiske formler.
Proceduren til at beregne stikprøvestørrelsen er en kæde af uendelige afvejninger mellem stræben efter nøjagtighed og begrænsede ressourcer, mangel på tid og ufuldstændig information om det undersøgte fænomen. Samtidig er det en videnskab og kunst, hvis viden er tilgængelig for enhver person. For at gøre dette skal du dog kende strategierne til at beregne stikprøvestørrelsen (foreløbig beregning, sekventielle og kombinerede strategier), samt faktorer, der påvirker stikprøvestørrelsen (størrelsen af den generelle befolkning, variation af respondenternes svar, estimeringsnøjagtighed , arten af den forventede fordeling af svar, forskningsmetode, behandlingsprocedure) ...
Forberegningsstrategi består i, at stikprøvestørrelsen bestemmes inden udførelse af hovedundersøgelsen. I det enkleste tilfælde kan du bruge de allerede opnåede erfaringer, for eksempel Gallup Instituttet, som bruger en stikprøvestørrelse på cirka 1500-2000 personer. For en gennemsnitlig russisk undersøgelse er stikprøvestørrelsen omkring 400-600 personer.
For at beregne volumen af en tilfældig prøve, skal du kende den ønskede estimeringsnøjagtighed, risikoværdien af svaret og graden af variabilitet af svaret. Traditionelt tages estimeringsnøjagtigheden som 5%, og risikoværdien - som 0,95. Med andre ord, hvis, ifølge en stikprøveundersøgelse, 60 % af de adspurgte er tilfredse med deres arbejde, så kan der argumenteres for, at andelen af tilfredse mennesker i den generelle befolkning vil være fra 55 til 65 % i 95 % af tilfældene. og i 5 % af tilfældene kan denne andel gå ud over dette interval. Forudsat en nøjagtighed på 5 % og en risikoværdi på 0,95, vil stikprøvestørrelsen være som følger (tabel 2.4).
bord 2.4 Stikprøvestørrelsens afhængighed af størrelsen af den generelle befolkning
Resultaterne er vist i tabel. 2.4, vidner mod den udbredte misforståelse, at stikprøvestørrelsen er en strengt fastsat procentdel af den generelle befolkning, svarende til 10. Faktisk er denne værdi ikke konstant, men en variabel, der ændrer sig under specifikke forhold. Stikprøvestørrelsen afhænger også af, hvilke spørgsmål der bruges i spørgeskemaet. Figurer i tabel. 2.4 er kun gyldige for ét tilfælde - når det drejer sig om et dikotomt spørgsmål, hvor den maksimale spredning af svar er 50 til 50 %. I mangel af foreløbige oplysninger om omfanget af skøn ser sociologen ud til at være forsikret på forhånd og mener, at dette interval vil være 50 til 50 %. Hvis sådanne oplysninger er tilgængelige, vil stikprøvestørrelsen være som følger.
Tabel 2.5 Afhængighed af stikprøvestørrelsen af fordelingen af det dikotome svar
Bord 2.5 viser fordelingen af svar på kvalitative spørgsmål. Beregningen af stikprøvestørrelsen for kvantitative spørgsmål, herunder spørgsmål som "alder" og "løn", er baseret på variationskoefficienten (tabel 2.6), som viser, hvor stor en procentdel er standardafvigelsen fra det aritmetiske gennemsnit, og giver dig mulighed for at sammenligne (efter variationsgrad) eventuelle tegn.
Tabel 2.6 Stikprøvestørrelsens afhængighed af variationskoefficienten
| Variationskoefficienten, % | ||||||||||||
| Prøvestørrelse |
Hvis arbejdsforhold, relationer i teamet, løn osv. undersøges. ved brug af en femledsskala varierer variationskoefficienten her fra 27 til 62 %, og ved brug af en syvledsskala fra 78 til 113 %. Jo længere skalaen er, jo højere er variationskoefficienten, og jo større skal stikprøvestørrelsen være. Hvis en sociolog vil klare sig med et lille udsnit, så bør spørgsmålene formuleres lettere. Det menes nogle gange, at jo længere skalaen er, jo mere nøjagtig er målingen. Men fordelene ved syvpunktsskalaer frem for fempunktsskalaer er ikke blevet bevist.
Der er en udbredt opfattelse blandt sociologer, at jo større stikprøvestørrelsen er, jo mere præcist er resultatet, og det tvinger dem til at øge antallet af respondenter urimeligt. I virkeligheden er situationen anderledes: tab. 2.7, udarbejdet fra Gallup Instituttet, viser sammenhængen mellem stikprøvestørrelse og procentvis nøjagtighed. Det følger af det, at med en stigning i stikprøvestørrelsen øges nøjagtigheden, men op til en vis tærskel. Allerede med 600 respondenter opnås den ønskede 5% nøjagtighed. Derfor er 600 personer en acceptabel stikprøvestørrelse.
Der er ingen modsætning mellem antallet af 400 og 600 personer. I det første tilfælde blev stikprøvestørrelsen beregnet ud fra bestemmelsen om normalfordelingen af respondenternes svar, og i det andet - fra praksis. Uoverensstemmelsen mellem teori og praksis skyldes, at fordelingen af estimater i en reel situation adskiller sig fra den normale, så stikprøvestørrelsen skal beregnes under hensyntagen til netop denne omstændighed; den mest effektive måde at reducere stikprøvestørrelsen på er at reducere variationskoefficienten for estimaterne.
Tabel 2.7 Sammenhæng mellem stikprøvestørrelse og estimeringsnøjagtighed
Når sociologer beregner stikprøvestørrelsen, begår sociologer ofte følgende fejl: at have beregnet den nødvendige stikprøvestørrelse som helhed for befolkningen ved hjælp af de eksisterende formler, og derefter proportionalt allokere den til separate underopdelinger af stikprøven, for eksempel efter værksteder, virksomheder, distrikter , byer og familietyper. Derefter analyseres selve forskellene mellem afdelingerne i databehandlingsstadiet. Det er dog mere korrekt at beregne stikprøvestørrelsen separat for hver division og derefter opsummere de enkelte volumener. Eksempelvis gjorde beregningerne af stikprøvestørrelsen for tre butikker (under hensyntagen til størrelsen af skalaen, antallet af ansatte, arten af den estimerede fordeling af estimater) det muligt at fastslå, at det i den første butik er nødvendigt at spørg 384 personer, i den anden - 222 og i den tredje - 600. Så vil den samlede stikprøvestørrelse være 384 + 222 + 600 = 1206 personer.
Hvis en sociolog har brug for at interviewe en hvilken som helst kategori af arbejdere (for eksempel buschauffører), om hvilke det kun er kendt, at den tilhører den, for eksempel den tiende medarbejder i virksomheden, og han besluttede at spørge 139 buschauffører, og den samlede stikprøvestørrelse for virksomheden vil være 1390 personer, de. med andre ord, ved tilfældigt at udvælge 1.390 respondenter på virksomheden i overensstemmelse med stikprøveteorien, håber vi at identificere 139 personer af det speciale, der interesserer os.
Når de beregner en kvoteprøve, bestemmer sociologer ofte vilkårligt dens størrelse til 1000, baseret på bekvemmeligheden ved at beregne kvoter. Men du kan lige så godt tage et hvilket som helst andet rundt tal. Mere rimelig er tilgangen, hvor størrelsen af kvoteprøven beregnes som for en tilfældig stikprøve. En anden mulighed for at beregne størrelsen af kvoteprøven er at bruge teorien om små stikprøver. Dens essens: hvis målet ikke er at give en differentieret analyse af grupper af arbejdere, så ganges antallet af gradueringer af spørgsmål, der skal studeres, med 25 (den mindste statistisk signifikante gruppestørrelse). For eksempel studeres tre variabler: køn - to kategorier, alder - to kategorier (under 30 og over 30), arbejdsglæde - målt på en fempunktsskala. Så vil den nødvendige stikprøvestørrelse for dette eksempel være 2x2x5x25 = 500 personer. Prøvestørrelsen øges 2,5 gange. Det er klart, at med udvidelsen af antallet af variable og antallet af gradationer, kan stikprøvestørrelsen blive katastrofalt stor. Der er kun én vej ud: en detaljeret undersøgelse af det oprindelige problem, som giver dig mulighed for at afvise unødvendige spørgsmål i spørgeskemaet og efterlade de vigtigste. Hvis en undersøgelse tester flere hypoteser, beregnes stikprøvestørrelsen for at teste hver hypotese separat. Når man bruger en stikprøve, bør antallet af spørgsmål i spørgeskemaet og hypoteserne således være minimalt.
Så vi har beregnet den nødvendige stikprøvestørrelse. Nu, og først nu, er det nødvendigt at kontrollere, om den opnåede værdi er kompatibel med de tildelte ressourcer. En typisk fejl for mange anvendte sociologer er, at når de beregner stikprøvestørrelsen, er tilgængelige ressourcer i højsædet, eller værre, sociologen accepterer passivt alle de betingelser, klienten dikterer. Dette er grundlæggende forkert af flere grunde. For det første giver beregningen af stikprøvestørrelsen mulighed for en dybere indsigt i essensen af det emne, der undersøges, og de særlige forhold ved forskningsmetoder, hvilket betyder, at det med rimelighed kan kræve flere ressourcer eller træffe den rigtige beslutning om at reducere stikprøvestørrelsen. Hvis administrationen har afvist yderligere ressourcer, og undersøgelsens formål ikke tillader at reducere stikprøvestørrelsen (dvs. sociologen kan ikke træffe afgørelsen fra administrationen), så er det nødvendigt at skifte til en anden forskningsordning. For det andet viser en rimelig beregning af stikprøvestørrelsen sociologens professionalisme og får klienten til at behandle ham med mere respekt.
Sekventiel afviklingsstrategi prøvestørrelse. Ved beregning af stikprøvestørrelsen er det ønskeligt at kende spredningen af estimater og nogle andre parametre. De er dog normalt ukendte. For at undgå fejl er det bedre at antage, at de er maksimale. Betalingen for vores uvidenhed er udvidelsen af stikprøvestørrelsen ud over de nødvendige og yderligere økonomiske og tidsmæssige omkostninger (vi skal interviewe et større antal personer). For at spare omkostninger anvendes en konsekvent strategi - stikprøvestørrelsen beregnes ikke på forhånd, men gøres afhængig af undersøgelsens endelige resultater. For eksempel bliver 100 personer interviewet, derefter fastsættes værdien af spredningen af estimater, og afhængigt af dette beregnes den nødvendige stikprøvestørrelse. Hvis det viser sig, at 100 personer er nok, så slutter undersøgelsen. Ellers når det nødvendige antal respondenter der, men ikke uendeligt. Der er et eksempel fra J. Gallups praksis, som i begyndelsen af sin karriere aktivt eksperimenterede med stikprøvestørrelser. I 1936 blev amerikanerne stillet spørgsmålet: "Vil du forny loven om genoprettelse af den nationale industri?" Et mærkeligt paradoks dukkede op: J. Gallup interviewede først 500 personer og målte stikprøvefejlen og øgede derefter konsekvent antallet af respondenter til 30 tusind. Desværre fandt han ud af, at tilføjelsen af 29,5 tusinde respondenter øgede nøjagtigheden af information med mindre end 1 %. Derfor kunne afstemningen allerede være stoppet med 500 respondenter. Dette eksempel viser, at ved at bruge en sekventiel strategi er det muligt at opnå en signifikant reduktion i antallet af nødvendige observationer sammenlignet med den foreløbige beregning af stikprøvestørrelsen.
Men strategien med sekventiel beregning af stikprøvestørrelsen giver kun det ønskede resultat, hvis sociologen kan foretage de nødvendige beregninger i løbet af selve undersøgelsen, for eksempel telefon, ved hjælp af computersystemer. Sociologen indtaster respondentens svar på sin personlige computer, hvorfra resultaterne straks sendes til forskningslederens computer, behandles, og displayet viser information ikke kun om de endimensionelle frekvenser fordelt på et bestemt emne, men også om påkrævet prøvestørrelse.
Hvis der er fare for, at stikprøvestørrelsen kan vise sig at være katastrofal stor, er det nødvendigt at kombinere begge typer strategier - foreløbige og sekventielle, dvs. at ansøge kombineret strategi. Ved at beregne stikprøven i henhold til den foreløbige strategi, opnår vi de øvre tilladelige værdier for den sekventielle strategi, eller med andre ord, værdien af stikprøvestørrelsen, når vi når hvilken polling ifølge den sekventielle strategi stopper.
Den mest rimelige og korrekte tilgang til at bestemme stikprøvestørrelsen er baseret på beregningen af konfidensintervaller, som er baseret på en række grundlæggende begreber inden for matematisk statistik (variation, standardafvigelse, konfidensinterval, standardfejl).
Til at beregne den krævede stikprøvestørrelse i kvantitativ forskning bruges to statistiske begreber oftest - konfidensintervallet og konfidenssandsynligheden. Konfidensinterval repræsenterer den prøveudtagningsfejl, du angiver på forhånd. Hvis du for eksempel sætter et konfidensinterval på 3 %, og det specifikke svar på et specifikt forskningsspørgsmål er 48 %, betyder det, at selvom du undersøger hele befolkningen, vil den faktiske værdi falde inden for intervallet mellem 45 (48 - 3) ) og 51 % (48 + 3). Tillidssandsynlighed viser, hvor sikker du kan være på de opnåede resultater, at stikprøvens karakteristika svarer til karakteristika for hele den generelle befolkning - med andre ord med hvilken sandsynlighed det tilfældige svar falder inden for konfidensintervallet. 95% og 99% konfidensniveauer bruges normalt. Oftest bruges 95% - det er ganske nok i langt de fleste undersøgelser. Hvis man kombinerer konfidensniveauet og konfidensintervallet, så kan vi sige, at svarene på spørgsmålet med 95 % sandsynlighed falder i intervallet mellem 45 og 51 %.
Følgende grove skøn over pålideligheden af stikprøveundersøgelsesresultater er meget nyttigt. Øget pålidelighed giver mulighed for en stikprøvefejl på op til 3%, almindelig - fra 3 til 10% (konfidensinterval for fordelinger på niveauet 0,03 til 0,1), omtrentlig - fra 10 til 20%, omtrentlig - fra 20 til 40%, og cirka - mere end 40%.
Ud fra disse begreber, under hensyntagen til en række antagelser, udledes formler til beregning af stikprøvestørrelsen, som antager, at repræsentativitet er garanteret ved at anvende korrekte probabilistiske stikprøveprocedurer.
I nogle tilfælde bruges omkostningerne ved undersøgelsen som hovedargumentet ved bestemmelse af stikprøvestørrelsen. Markedsundersøgelsesbudgettet dækker således udgifterne til visse undersøgelser, som ikke bør overskrides, og det er åbenlyst, at værdien af de modtagne oplysninger ikke tages i betragtning. Men i nogle tilfælde kan selv en lille prøve give ret nøjagtige resultater.
Forskningspraksis foreslår følgende regel: stikprøvestørrelsen skal give mindst 100 observationer for hver primær og mindst 20-50 observationer for hver sekundær klassifikationskomponent. 11 svarer de primære klassifikationskomponenter til de mest kritiske, og de sekundære svarer til de mindst kritiske celler i krydsklassifikationen, der er vedtaget i denne undersøgelse 34. Teoretiske beregninger og praksis viser, at for at opnå pålidelige data om befolkningens mening og præferencer i en så stor by som St. Petersborg er det nok at interviewe 700-800 mennesker. Men de fleste af befolkningsundersøgelserne her er udført på stikprøver på op til 1,5 tusinde mennesker.
Prøveudtagningsfejl
Som vi allerede ved, er repræsentativitet en prøves egenskab til at repræsentere en karakteristik af den generelle befolkning. Hvis der ikke er match, taler de om repræsentativitetsfejl- i hvilket omfang den statistiske struktur af stikprøven afviger fra strukturen i den tilsvarende generelle population. Antag, at den gennemsnitlige månedlige familieindkomst for pensionister i den almindelige befolkning er 2 tusind rubler, og i prøven - 6 tusind rubler. Det betyder, at sociologen kun interviewede den velstillede del af pensionister, og der sneg sig en repræsentativitetsfejl ind i hans forskning. Med andre ord kaldes repræsentativitetsfejlen uoverensstemmelse mellem to populationer- generelt, som sociologens teoretiske interesse er rettet mod og en idé om de egenskaber, som han ønsker at få til sidst, og selektiv, som sociologens praktiske interesse er rettet mod, som samtidig fungerer som en genstand for undersøgelse og et middel til at indhente oplysninger om den almindelige befolkning.
Sammen med udtrykket "repræsentativitetsfejl" i den hjemlige litteratur kan du finde en anden - "prøveudtagningsfejl". Nogle gange bruges de synonymt, og nogle gange bruges "sampling error" i stedet for "representativeness error" som et kvantitativt mere præcist begreb.
Prøveudtagningsfejl- afvigelsen af stikprøvens gennemsnitlige karakteristika fra gennemsnitskarakteristika for den almindelige befolkning.
I praksis bestemmes stikprøvefejl ved at sammenligne de kendte karakteristika for den generelle befolkning med stikprøvegennemsnit. I sociologien, når man undersøger den voksne befolkning, bruges data fra folketællinger, aktuelle statistiske optegnelser og resultaterne af tidligere undersøgelser oftest. Sociodemografiske karakteristika bruges normalt som kontrolparametre. Sammenligning af gennemsnittet af den generelle og stikprøvepopulation, på grundlag af dette, kaldes bestemmelsen af stikprøvefejlen og dens reduktion kontrollerende repræsentativitet. Da en sammenligning af dine egne og andres data kan foretages i slutningen af undersøgelsen, kaldes denne kontrolmetode a posteriori, de der. udført efter forsøget.
I J. Gallup Instituttets meningsmålinger kontrolleres repræsentativiteten i henhold til de tilgængelige data i de nationale folketællinger om befolkningens fordeling på køn, alder, uddannelse, indkomst, erhverv, race, bopæl og bebyggelsens størrelse . Det All-Russian Center for Study of Public Opinion (VTsIOM) bruger til sådanne formål sådanne indikatorer som køn, alder, uddannelse, bosættelsestype, civilstand, beskæftigelsessfære, respondentens jobstatus, som er lånt fra staten Udvalget for Statistik i Den Russiske Føderation. I begge tilfælde er den generelle befolkning kendt. Stikprøvefejlen kan ikke fastslås, hvis værdierne af variablen i stikprøven og den generelle population er ukendte.
Ved analyse af dataene sikrer VTsIOM-specialister en grundig reparation af prøven for at minimere afvigelser, der opstod i feltarbejdet. Særligt stærke forskydninger observeres med hensyn til køn og alder. Dette forklares med, at kvinder og personer med videregående uddannelser tilbringer mere tid hjemme og lettere får kontakt til intervieweren, dvs. er en let opnåelig gruppe sammenlignet med mænd og "uuddannede" mennesker.
Prøveudtagningsfejl skyldes to faktorer: stikprøvemetoden og stikprøvestørrelsen.
Prøveudtagningsfejl er klassificeret i to typer - tilfældige og systematiske. Tilfældig fejl - det er sandsynligheden for, at stikprøvegennemsnittet vil gå (eller ikke gå) ud over det specificerede interval. Tilfældige fejl omfatter statistiske fejl, der er iboende i selve stikprøvemetoden. De falder med stigende stikprøvestørrelse (tabel 2.8).
Tabel 2.8
Stikprøvestørrelsens afhængighed af dens fejl 36 (størrelsen af den generelle befolkning er 20 tusinde enheder)
| Sampling fejl, % | |||||||||||||
| Prøvestørrelse, enheder |
Den anden type stikprøvefejl er systematiske fejl. Hvis en sociolog besluttede at finde ud af alle byens indbyggeres mening om den socialpolitik, som de lokale myndigheder fører, og kun interviewede dem, der har en telefon, så er der en bevidst skævhed i stikprøven til fordel for de velhavende do strata, dvs systematisk fejl.
Systematiske fejl er således resultatet af forskerens aktiviteter. De er de farligste, fordi de fører til ret betydelige skævheder i forskningsresultater. Systematiske fejl anses også for at være værre end tilfældige fejl, fordi de ikke kan kontrolleres og måles.
De opstår, når f.eks.: 1) stikprøven ikke svarer til undersøgelsens mål (sociologen besluttede kun at undersøge arbejdende pensionister, men interviewede alle i træk); 2) der mangler viden om den generelle befolknings karakter (sociologen mente, at 70 % af alle pensionister ikke arbejder, men det viste sig, at kun 10 % ikke arbejder); 3) kun "vindende" elementer af den generelle befolkning vælges (f.eks. kun velhavende pensionister).
Opmærksomhed!I modsætning til tilfældige fejl falder systematiske fejl ikke med stigende stikprøvestørrelse.
Ved at opsummere alle de tilfælde, hvor der opstår systematiske fejl, har metodologerne udarbejdet deres register. De mener, at følgende faktorer kan være kilden til ukontrolleret skævhed i fordelingen af stikprøvetilfælde:
♦ de metodiske og metodiske regler for udførelse af en sociologisk forskning er blevet overtrådt;
♦ utilstrækkelige metoder til at danne stikprøvepopulationen, metoder til indsamling og beregning af data blev udvalgt;
♦ de nødvendige observationsenheder blev erstattet af andre, mere tilgængelige;
♦ Ufuldstændig dækning af stikprøven blev noteret (mangel på spørgeskemaer, ufuldstændig udfyldning, utilgængelighed af observationsenheder).
Sociologen laver sjældent bevidste fejl. Oftere opstår der fejl på grund af det faktum, at sociologen ikke godt kender strukturen i den almindelige befolkning: fordelingen af mennesker efter alder, erhverv, indkomst osv.
Systematiske fejl er nemmere at forhindre (sammenlignet med tilfældige fejl), men de er meget svære at eliminere. Det er bedst at forhindre systematiske fejl ved præcist at forudsige deres kilder på forhånd - helt i begyndelsen af undersøgelsen.
Her er nogle måder at undgå fejl på:
♦ hver enhed i den generelle befolkning skal have lige stor sandsynlighed for at blive inkluderet i stikprøven;
♦ det er ønskeligt at foretage selektion fra homogene populationer;
♦ du skal kende den generelle befolknings karakteristika;
♦ ved sammenstilling af en stikprøve er det nødvendigt at tage højde for tilfældige og systematiske fejl.
Hvis prøvepopulationen (eller blot prøven) er sammensat korrekt, opnår sociologen pålidelige resultater, der karakteriserer hele den generelle befolkning. Hvis det er tegnet forkert, så formerer den fejl, der opstod på prøvetagningsstadiet, på hvert efterfølgende trin af den sociologiske forskning, sig og når til sidst en værdi, der opvejer værdien af forskningen. Det siges, at der er mere skade end gavn af sådan forskning.
Sådanne fejl kan kun forekomme med en stikprøvepopulation. For at undgå eller reducere sandsynligheden for fejl er den enkleste måde at øge stikprøvestørrelserne (og ideelt set til størrelsen af den generelle population: når begge populationer falder sammen, vil stikprøvefejlen forsvinde helt). Økonomisk er denne metode umulig. Der er stadig en anden måde - at forbedre de matematiske metoder til prøveudtagning. De bruges i praksis. Dette er den første kanal for indtrængen i matematikkens sociologi. Den anden kanal er matematisk databehandling.
Problemet med fejl bliver især vigtigt i markedsføringsundersøgelser, hvor der ikke bruges særlig store stikprøver. Normalt udgør de flere hundrede, sjældnere - tusinde respondenter. Her er udgangspunktet for beregning af stikprøven spørgsmålet om at bestemme størrelsen af stikprøvepopulationen. Størrelsen af stikprøven afhænger af to faktorer: I) omkostningerne ved at indsamle information og 2) stræben efter en vis grad af statistisk pålidelighed af de resultater, som forskeren håber at opnå. Selvfølgelig forstår selv folk, der ikke er erfarne i statistik og sociologi, intuitivt, at jo større stikprøvestørrelse, dvs. jo tættere de er på størrelsen af den generelle befolkning som helhed, jo mere pålidelige og pålidelige er de torturerede data. Men ovenfor har vi allerede talt om den praktiske umulighed af kontinuerlige undersøgelser i de tilfælde, hvor de udføres på genstande, hvis antal overstiger titusinder, hundredtusinder og endda millioner. Det er klart, at omkostningerne ved at indsamle information (inklusive betaling for replikering af værktøjskassen, arbejde med spørgeskemaer, feltledere og computerinputoperatører) afhænger af det beløb, som kunden er villig til at allokere, og afhænger kun lidt af forskerne. Hvad angår den anden faktor, vil vi dvæle ved det lidt mere detaljeret.
Så jo større stikprøvestørrelsen er, jo mindre er den mulige fejl. Det skal dog bemærkes, at hvis du vil fordoble nøjagtigheden, bliver du nødt til at øge prøven ikke to gange, men fire gange. For at gøre dit estimat af data opnået fra en undersøgelse med 400 personer dobbelt så nøjagtige, skal du for eksempel interviewe ikke 800, men 1600 personer. Det er dog usandsynligt, at markedsføringsforskning behøver hundrede procent nøjagtighed. Hvis en brygger skal finde ud af, hvilken del af ølforbrugerne der foretrækker hans mærke frem for konkurrentens mærke - 60 % eller 40 %, så vil forskellen mellem 57 %, 60 eller 63 % ikke påvirke hans planer på nogen måde.
Prøveudtagningsfejl kan afhænge ikke kun af dens størrelse, men også af graden af forskelle mellem individuelle enheder inden for den generelle befolkning, som vi studerer. For eksempel, hvis vi har brug for at vide, hvor meget øl der indtages, så vil vi opdage, at inden for vores generelle befolkning er forbrugsraterne for forskellige mennesker markant forskellige. (heterogen almindelig befolkning). I et andet tilfælde vil vi studere forbruget af brød og finde ud af, at det for forskellige mennesker adskiller sig meget mindre væsentligt. (homogen almindelig befolkning). Jo større forskel (eller heterogenitet) inden for den generelle befolkning er, jo større er størrelsen af den mulige stikprøvefejl. Dette mønster bekræfter kun, hvad simpel sund fornuft fortæller os. Således, som V. Yadov med rette hævder, "Størrelsen (størrelsen) af prøven afhænger af niveauet af homogenitet eller heterogenitet af de genstande, der undersøges. Jo mere homogene de er, jo mindre kan antallet give statistisk pålidelige konklusioner."
Bestemmelsen af stikprøvestørrelsen afhænger også af niveauet af konfidensintervallet for den tilladelige statistiske fejl. Dette henviser til den såkaldte tilfældig fejl, der er relateret til arten af enhver statistisk fejl. I OG. Paniotto giver følgende beregninger for en repræsentativ prøve med en 5 % fejl (tabel 2.9):
Tabel 2.9
Repræsentative prøveudregninger
Det betyder, at hvis du for eksempel spurgte 400 mennesker i en distriktsby, hvor den voksne opløsningsmiddelbefolkning er 100.000 mennesker, fandt du ud af, at 33 % af de adspurgte købere foretrækker produkterne fra et lokalt kødforarbejdningsanlæg, så med en 95 % 39 sandsynlighed kan du sige, at 33 ± 5% (dvs. fra 28 til 38%) af indbyggerne i denne by er regelmæssige købere af disse produkter.
Du kan også bruge Gallup-beregninger til at estimere forholdet mellem stikprøvestørrelse og stikprøvefejl (se ovenfor).
I dag udføres en masse svære beregninger af teknikere, og statistiske programmer kan hentes fra internettet. Så med beregningen af prøven fik den dovne sociolog en sådan mulighed på webstedet for det analytiske center "Business and Marketing" (http://www.bma.ru/enter.htm), hvor brugeren kun behøver at indtast de nødvendige data, og klik derefter på knappen Beregn.
Interval estimering af sandsynligheden for en hændelse. Formler til beregning af stikprøvens størrelse med en korrekt tilfældig udvælgelsesmetode.For at bestemme sandsynligheden for begivenhederne af interesse for os, bruger vi prøveudtagningsmetoden: vi udfører n uafhængige eksperimenter, i hver af hvilke begivenheden A (sandsynlighed R forekomsten af hændelse A i hvert eksperiment er konstant). Derefter den relative frekvens p * af forekomster af begivenheder EN i en række af n test tages som et punktestimat for sandsynligheden s forekomst af en begivenhed EN i en særskilt retssag. I dette tilfælde kaldes mængden p * selektiv andel begivenhedsoptrædener EN, og p - generel andel .
I kraft af en følge af den centrale grænsesætning (Moivre-Laplace-sætningen) kan den relative frekvens af en hændelse for en stor stikprøvestørrelse betragtes som normalfordelt med parametrene M (p *) = p og
Derfor, for n> 30, kan konfidensintervallet for den generelle brøk konstrueres ved hjælp af formlerne:

hvor u cr findes i henhold til tabellerne i Laplace-funktionen under hensyntagen til den givne konfidenssandsynlighed γ: 2Ф (u cr) = γ.
Med en lille stikprøvestørrelse n≤30 bestemmes den marginale fejl ε ud fra Elevens fordelingstabel: ![]() hvor t cr = t (k; α) og antallet af frihedsgrader k = n-1 sandsynlighed α = 1-γ (tosidet område).
hvor t cr = t (k; α) og antallet af frihedsgrader k = n-1 sandsynlighed α = 1-γ (tosidet område).
Formlerne er gyldige, hvis udvælgelsen blev udført på en tilfældig gentagen måde (den generelle befolkning er uendelig), ellers er det nødvendigt at foretage en ændring for ikke-gentagelse af udvælgelsen (tabel).
Gennemsnitlig stikprøvefejl for den generelle andel
| Almen befolkning | Endeløs | Ultimativ volumen N |
| Udvalgstype | Gentaget | Kan ikke gentages |
| Gennemsnitlig prøveudtagningsfejl |
Formler til beregning af stikprøvens størrelse med en korrekt tilfældig udvælgelsesmetode
| Udvælgelsesmetode | Prøvestørrelsesformler | ||
| for midten | til del | ||
| Gentaget | |||
| Kan ikke gentages | |||
Generelle aktieproblemer
Til spørgsmålet "Dækker konfidensintervallet den givne værdi af p 0?" - kan besvares ved at kontrollere den statistiske hypotese H 0: p = p 0. I dette tilfælde antages det, at eksperimenterne udføres i henhold til Bernoulli-testskemaet (uafhængig, sandsynligheden s forekomst af en begivenhed EN konstant). Efter prøvevolumen n bestem den relative frekvens p * for forekomsten af hændelse A: hvor m- antallet af hændelser EN i en række af n tests. For at teste hypotesen H 0 anvendes statistik, der har en standard normalfordeling for en tilstrækkelig stor stikprøvestørrelse (tabel 1).Tabel 1 - Hypoteser om den generelle andel
Hypotese | H 0: p = p 0 | H 0: p 1 = p 2 |
| Forudsætninger | Bernoulli testskema | Bernoulli testskema |
| Prøvevurderinger |  |
|
| Statistikker K | 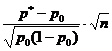 | 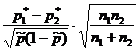 |
| Fordeling af statistik K | Standard normal N (0,1) |
Eksempel #1. Ved hjælp af tilfældig genudtagning gennemførte ledelsen en stikprøveundersøgelse af 900 af sine medarbejdere. Blandt de adspurgte var der 270 kvinder. Plot konfidensintervallet, der dækker den sande andel af kvinder i hele virksomheden med en sandsynlighed på 0,95.
Løsning. Efter betingelse er stikprøveandelen af kvinder (den relative hyppighed af kvinder blandt alle respondenter). Da stikprøven gentages, og stikprøvestørrelsen er stor (n = 900), bestemmes den marginale stikprøvefejl af formlen ![]()
Værdien af u cr findes fra tabellen for Laplace-funktionen ud fra relationen 2Ф (u cr) = γ, dvs. ![]() Laplace-funktionen (bilag 1) tager værdien 0,475 ved u cr = 1,96. Derfor er den marginale fejl
Laplace-funktionen (bilag 1) tager værdien 0,475 ved u cr = 1,96. Derfor er den marginale fejl ![]() og det ønskede konfidensinterval
og det ønskede konfidensinterval
(p - e, p + e) = (0,3 - 0,18; 0,3 + 0,18) = (0,12; 0,48)
Så med en sandsynlighed på 0,95 kan vi garantere, at andelen af kvinder i hele virksomhedens team er i området fra 0,12 til 0,48.
Eksempel nr. 2. Ejeren af parkeringspladsen anser dagen for "god", hvis parkeringspladsen er mere end 80 % fyldt. I løbet af året er der gennemført 40 eftersyn af parkeringspladsen, hvoraf de 24 var "vellykkede". Find konfidensintervallet med en sandsynlighed på 0,98 for at estimere den sande andel af "vellykkede" dage i løbet af et år.
Løsning... Den selektive andel af "vellykkede" dage er
Ved hjælp af tabellen for Laplace-funktionen finder vi værdien af u cr for en given
Selvtillidsniveau
Ф (2,23) = 0,49, u cr = 2,33.
I betragtning af at valget ikke kan gentages (dvs. to kontroller blev ikke udført på en dag), finder vi den marginale fejl: ![]()
hvor n = 40, N = 365 (dage). Herfra ![]()
og konfidensintervallet for den generelle andel: (p - ε, p + ε) = (0,6 - 0,17; 0,6 + 0,17) = (0,43; 0,77)
Med en sandsynlighed på 0,98 kan vi forvente, at andelen af ”vellykkede” dage i løbet af året ligger i intervallet fra 0,43 til 0,77.
Eksempel nr. 3. Efter at have kontrolleret 2500 genstande i et parti, fandt vi ud af, at 400 genstande var af højeste kvalitet, og n – m ikke var. Hvor mange produkter skal du kontrollere for med 95 % sikkerhed at bestemme andelen af den højeste karakter med en nøjagtighed på 0,01?
Vi leder efter en løsning i henhold til formlen til at bestemme størrelsen af prøven til genudvælgelse.
Ф (t) = γ / 2 = 0,95 / 2 = 0,475 og denne værdi ifølge Laplace-tabellen svarer til t = 1,96
Prøvefraktion w = 0,16; prøveudtagningsfejl ε = 0,01
Eksempel nr. 4. En masse produkter accepteres, hvis sandsynligheden for, at produktet vil være i overensstemmelse med standarden, er mindst 0,97. Blandt de tilfældigt udvalgte 200 genstande i det testede parti blev 193 fundet at leve op til standarden. Er det muligt at acceptere en part på signifikansniveauet α = 0,02?
Løsning... Lad os formulere de vigtigste og alternative hypoteser.
H 0: p = p 0 = 0,97 - ukendt generel andel s lig med den givne værdi p 0 = 0,97. Med hensyn til betingelsen - sandsynligheden for, at en del fra det testede parti vil være i overensstemmelse med standarden, er 0,97; de der. partiet af produkter kan accepteres.
H 1: s<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Observeret statistisk værdi K(tabel) beregner vi for de givne værdier p 0 = 0,97, n = 200, m = 193

Vi finder den kritiske værdi fra tabellen over Laplace-funktionen fra ligheden
![]()
Ved betingelse er α = 0,02, derfor Ф (Ккр) = 0,48 og Ккр = 2,05. Den kritiske region er venstresidet, dvs. er intervallet (-∞; -K kp) = (-∞; -2,05). Den observerede værdi af K obs = -0,415 hører ikke til den kritiske region, derfor er der på dette signifikansniveau ingen grund til at afvise hovedhypotesen. Du kan acceptere et parti af produkter.
Eksempel nr. 5. To fabrikker producerer den samme type dele. For at vurdere deres kvalitet blev der taget prøver af produkterne fra disse fabrikker, og følgende resultater blev opnået. Blandt de 200 udvalgte produkter fra den første plante var 20 defekte, blandt de 300 produkter fra den anden plante - 15 var defekte.
Ved et signifikansniveau på 0,025 skal du finde ud af, om der er en væsentlig forskel i kvaliteten af de dele, der produceres af disse fabrikker.
Ved betingelsen α = 0,025, derfor Ф (Ккр) = 0,4875 og Ккр = 2,24. Med et tosidet alternativ er intervallet af tilladte værdier (-2,24; 2,24). Den observerede værdi af K obs = 2,15 falder inden for dette interval, dvs. på dette betydningsniveau er der ingen grund til at forkaste hovedhypotesen. Fabrikker producerer produkter af samme kvalitet.